LiveLongBench: Tackling Long-Context Understanding for Spoken Texts from Live Streams
作者: Yongxuan Wu, Runyu Chen, Peiyu Liu, Hongjin Qian
分类: cs.CL, cs.AI
发布日期: 2025-04-24
🔗 代码/项目: GITHUB
💡 一句话要点
提出LiveLongBench,用于评估LLM在直播场景下长文本理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本理解 口语文本 直播场景 大型语言模型 自然语言处理 数据集构建 信息检索 推理任务
📋 核心要点
- 现有长文本理解基准难以反映真实对话场景的复杂性,尤其是在语音文本中,存在冗余和信息密度不均等问题。
- 论文构建了首个源自直播流的口语长文本数据集LiveLongBench,旨在模拟真实场景中的冗余和对话特性。
- 实验表明,现有方法在处理冗余输入时表现不佳,且任务偏好性强。论文提出了一种新的基线方法,能更好地处理冗余并取得良好效果。
📝 摘要(中文)
长文本理解在自然语言处理中面临重大挑战,尤其是在具有语音元素、高冗余和信息密度不均的真实对话中。尽管大型语言模型(LLM)在现有基准测试中取得了令人印象深刻的结果,但这些数据集未能反映此类文本的复杂性,限制了它们在实际场景中的适用性。为了弥合这一差距,我们构建了第一个口语长文本数据集LiveLongBench,该数据集源自直播流,旨在反映真实场景中富含冗余和对话的性质。我们构建了三类任务:检索依赖型、推理依赖型和混合型。然后,我们评估了流行的LLM和专门的方法,以评估它们在这些任务中理解长文本的能力。我们的结果表明,当前的方法表现出很强的任务特定偏好,并且在高度冗余的输入上表现不佳,没有一种方法始终优于其他方法。我们提出了一种新的基线,可以更好地处理口语文本中的冗余,并在各项任务中取得良好的性能。我们的发现突出了当前方法的主要局限性,并为改进长文本理解提出了未来的方向。最后,我们的基准测试填补了评估长文本口语理解的空白,并为开发实际的电子商务系统提供了实践基础。
🔬 方法详解
问题定义:论文旨在解决现有长文本理解模型在处理真实场景下口语长文本时遇到的困难。现有方法在处理直播场景下常见的冗余信息和信息密度不均问题时表现不佳,导致模型无法有效提取关键信息并进行准确理解。
核心思路:论文的核心思路是构建一个更贴近真实场景的口语长文本数据集,并在此基础上评估现有模型的性能,同时提出一种新的基线方法来更好地处理冗余信息。通过这种方式,可以更准确地评估模型在真实场景下的长文本理解能力,并为未来的研究提供方向。
技术框架:LiveLongBench数据集包含从直播流中提取的口语文本,并构建了三类任务:检索依赖型、推理依赖型和混合型。检索依赖型任务需要模型从上下文中检索相关信息;推理依赖型任务需要模型进行逻辑推理;混合型任务则结合了检索和推理。论文还提出了一种新的基线方法,该方法旨在更好地处理口语文本中的冗余信息。
关键创新:论文的关键创新在于构建了一个更贴近真实场景的口语长文本数据集LiveLongBench,该数据集能够更准确地反映真实场景下的长文本理解挑战。此外,论文提出的新的基线方法能够更好地处理口语文本中的冗余信息,并在各项任务中取得良好的性能。
关键设计:论文在构建数据集时,特别关注了直播场景下的特点,例如口语化表达、高冗余度和信息密度不均等。在设计基线方法时,论文可能采用了注意力机制或其他技术来过滤冗余信息,并突出关键信息。具体的参数设置、损失函数和网络结构等技术细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片
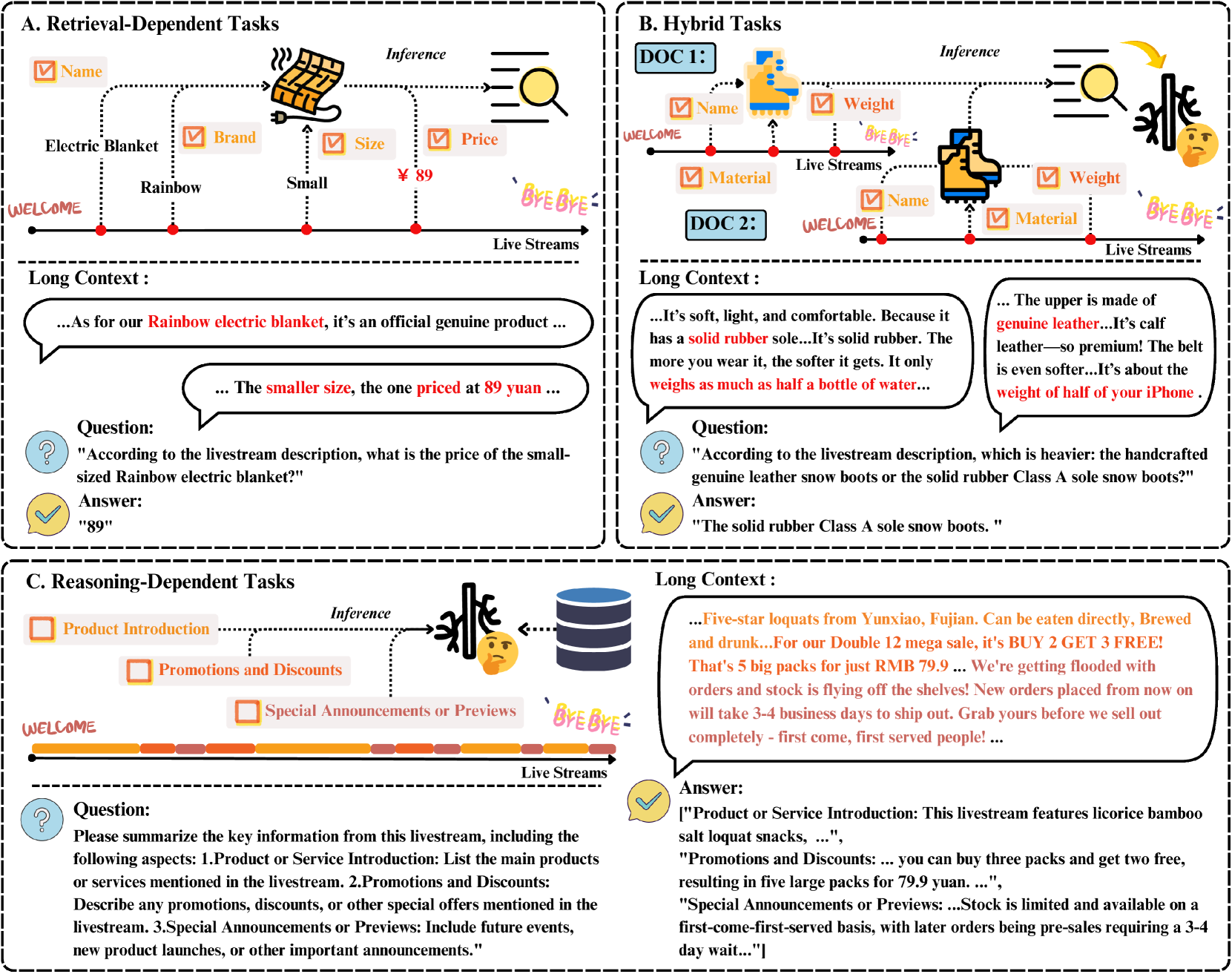

📊 实验亮点
实验结果表明,现有LLM在LiveLongBench数据集上表现出较强的任务偏好性,且在处理冗余输入时性能下降。论文提出的新基线方法能够更好地处理冗余信息,并在各项任务中取得良好的性能,表明其在口语长文本理解方面具有优势。具体的性能提升幅度需要参考论文中的实验数据(未知)。
🎯 应用场景
该研究成果可应用于智能客服、语音助手、直播内容理解、电商推荐等领域。通过提升模型在口语长文本上的理解能力,可以改善用户体验,提高服务效率,并为相关应用提供更准确的信息支持。该数据集和基线方法为未来长文本理解研究提供了有价值的资源和参考。
📄 摘要(原文)
Long-context understanding poses significant challenges in natural language processing, particularly for real-world dialogues characterized by speech-based elements, high redundancy, and uneven information density. Although large language models (LLMs) achieve impressive results on existing benchmarks, these datasets fail to reflect the complexities of such texts, limiting their applicability to practical scenarios. To bridge this gap, we construct the first spoken long-text dataset, derived from live streams, designed to reflect the redundancy-rich and conversational nature of real-world scenarios. We construct tasks in three categories: retrieval-dependent, reasoning-dependent, and hybrid. We then evaluate both popular LLMs and specialized methods to assess their ability to understand long-contexts in these tasks. Our results show that current methods exhibit strong task-specific preferences and perform poorly on highly redundant inputs, with no single method consistently outperforming others. We propose a new baseline that better handles redundancy in spoken text and achieves strong performance across tasks. Our findings highlight key limitations of current methods and suggest future directions for improving long-context understanding. Finally, our benchmark fills a gap in evaluating long-context spoken language understanding and provides a practical foundation for developing real-world e-commerce systems. The code and benchmark are available at https://github.com/Yarayx/livelongbench.