FLUKE: A Linguistically-Driven and Task-Agnostic Framework for Robustness Evaluation
作者: Yulia Otmakhova, Hung Thinh Truong, Rahmad Mahendra, Zenan Zhai, Rongxin Zhu, Daniel Beck, Jey Han Lau
分类: cs.CL, cs.AI
发布日期: 2025-04-24 (更新: 2025-10-17)
💡 一句话要点
FLUKE:一种语言驱动且任务无关的鲁棒性评估框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 鲁棒性评估 自然语言处理 大型语言模型 语言变动 任务无关
📋 核心要点
- 现有NLP模型缺乏系统性的鲁棒性评估方法,难以充分了解模型在面对语言变动时的表现。
- FLUKE框架通过引入跨语言层面的受控变动,并结合LLM生成和人工验证,实现了对模型鲁棒性的全面评估。
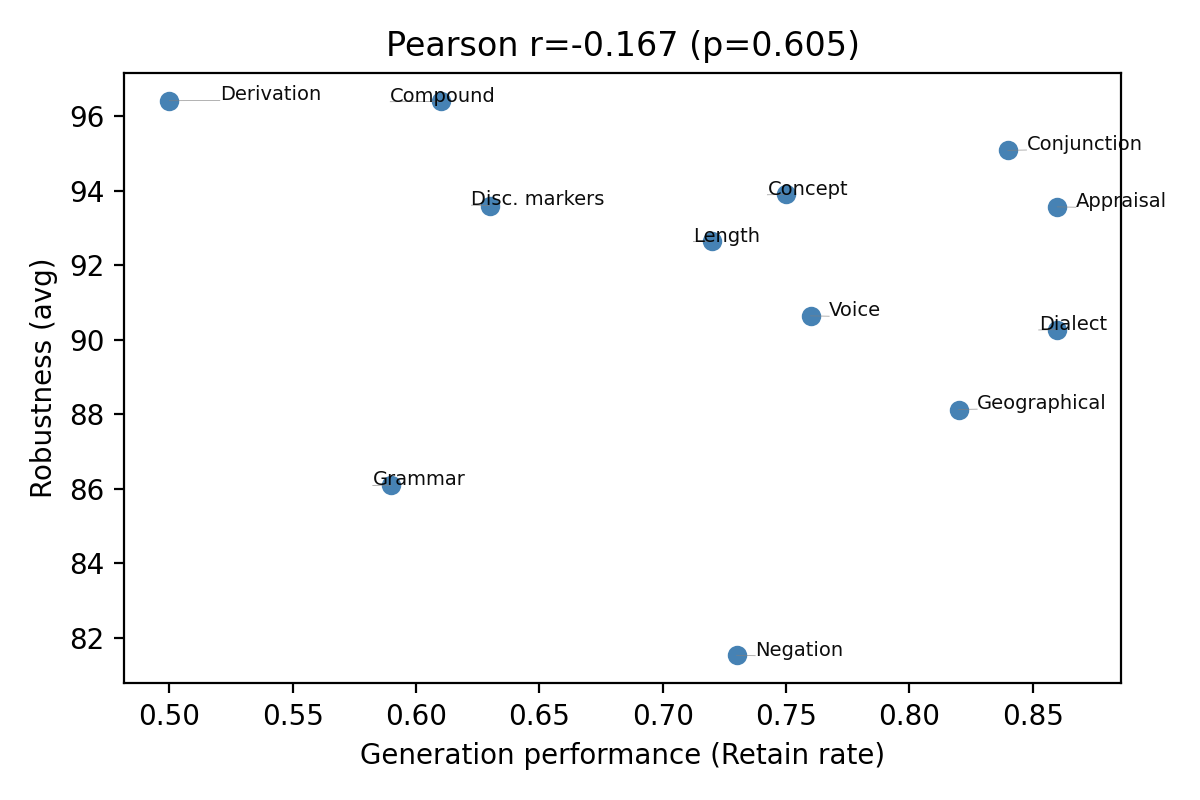
- 实验表明,模型对不同语言变动的鲁棒性存在显著差异,且模型生成能力与鲁棒性之间没有直接关联。
📝 摘要(中文)
FLUKE(语言驱动且任务无关的鲁棒性评估框架)是一种通过系统性地对测试数据进行最小变动来评估模型鲁棒性的框架。FLUKE引入了跨语言层面的受控变动,从正字法到方言和风格,并利用大型语言模型(LLM)进行修改生成,同时进行人工验证。我们通过在六个不同的NLP任务(四个分类任务和两个生成任务)中评估微调模型和LLM来展示FLUKE的效用,并揭示:(1)语言变动的影响高度依赖于任务,某些测试对于某些任务至关重要,但对于其他任务则无关紧要;(2)LLM在某些语言变动方面仍然表现出明显的脆弱性,令人惊讶的是,推理LLM在某些任务上的鲁棒性低于基础模型;(3)与诸如字母翻转之类的损坏风格测试相比,模型总体上对自然、流畅的修改(例如语法或风格变化,尤其是否定)更加脆弱;(4)模型在生成中使用语言特征的能力与模型在下游任务中对该特征的鲁棒性无关。这些发现突出了系统鲁棒性测试对于理解模型行为的重要性。
🔬 方法详解
问题定义:现有NLP模型,包括微调模型和大型语言模型(LLM),在面对真实世界中存在的各种语言变动时,其鲁棒性往往不足。现有的鲁棒性评估方法通常不够系统化,难以覆盖各种可能的语言变动,并且缺乏对不同任务的针对性分析。因此,需要一种更加系统、全面且任务无关的鲁棒性评估框架,以更好地理解模型的行为并发现其潜在的弱点。
核心思路:FLUKE的核心思路是通过系统性地引入各种语言层面的变动,并观察模型在这些变动下的表现,从而评估模型的鲁棒性。这种方法的核心在于控制变动的类型和程度,并确保变动后的数据仍然保持一定的自然性和流畅性。通过对不同任务和模型的评估,可以揭示模型对不同语言特征的敏感程度,并为模型的改进提供指导。
技术框架:FLUKE框架主要包含以下几个关键模块:1) 语言变动生成模块:该模块负责生成各种语言层面的变动,包括正字法、词汇、句法、语义、风格和方言等。该模块利用LLM生成变动,并进行人工验证,以确保变动的质量和自然性。2) 任务执行模块:该模块负责在原始数据和变动后的数据上执行各种NLP任务,包括分类和生成任务。3) 鲁棒性评估模块:该模块负责比较模型在原始数据和变动后的数据上的表现,并计算鲁棒性指标。该模块可以分析不同语言变动对模型性能的影响,并识别模型的弱点。
关键创新:FLUKE的关键创新在于其系统性和任务无关性。它提供了一种通用的框架,可以用于评估各种NLP任务和模型的鲁棒性。此外,FLUKE还引入了LLM生成和人工验证,以确保语言变动的质量和自然性。与传统的基于对抗样本的鲁棒性评估方法相比,FLUKE更加注重对自然语言变动的模拟,从而更真实地反映了模型在实际应用中的表现。
关键设计:FLUKE的关键设计包括:1) 语言变动类型的选择:FLUKE选择了涵盖各种语言层面的变动类型,以全面评估模型的鲁棒性。2) LLM生成和人工验证:FLUKE利用LLM生成语言变动,并进行人工验证,以确保变动的质量和自然性。3) 鲁棒性指标的选择:FLUKE选择了多种鲁棒性指标,包括准确率、F1值和BLEU分数等,以全面评估模型的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,语言变动对模型性能的影响高度依赖于任务类型。例如,某些任务对语法变动非常敏感,而另一些任务则对拼写错误更加敏感。此外,研究还发现,大型语言模型在某些任务上的鲁棒性甚至低于微调模型,这表明大型语言模型仍然存在一定的脆弱性。更重要的是,模型在生成中使用某种语言特征的能力并不一定意味着它对该特征具有鲁棒性。
🎯 应用场景
FLUKE框架可广泛应用于NLP模型的鲁棒性评估和改进。它可以帮助开发者识别模型在面对各种语言变动时的弱点,并针对性地进行改进,从而提高模型在实际应用中的可靠性和泛化能力。此外,FLUKE还可以用于比较不同模型的鲁棒性,为模型选择提供参考。
📄 摘要(原文)
We present FLUKE (Framework for LingUistically-driven and tasK-agnostic robustness Evaluation), a framework for assessing model robustness through systematic minimal variations of test data. FLUKE introduces controlled variations across linguistic levels -- from orthography to dialect and style -- and leverages large language models (LLMs) with human validation to generate modifications. We demonstrate FLUKE's utility by evaluating both fine-tuned models and LLMs across six diverse NLP tasks (four classification and two generation tasks), and reveal that (1) the impact of linguistic variations is highly task-dependent, with some tests being critical for certain tasks but irrelevant for others; (2) LLMs still exhibit significant brittleness to certain linguistic variations, with reasoning LLMs surprisingly showing less robustness on some tasks compared to base models; (3) models are overall more brittle to natural, fluent modifications such as syntax or style changes (and especially to negation), compared to corruption-style tests such as letter flipping; (4) the ability of a model to use a linguistic feature in generation does not correlate to its robustness to this feature on downstream tasks. These findings highlight the importance of systematic robustness testing for understanding model behaviors.