Testing Conviction: An Argumentative Framework for Measuring LLM Political Stability
作者: Shariar Kabir, Kevin Esterling, Yue Dong
分类: cs.CL
发布日期: 2025-04-23 (更新: 2025-08-29)
备注: 14 pages, 8 figures
💡 一句话要点
提出论证框架Testing Conviction,评估LLM政治立场的稳定性,区分真实立场与表演性文本生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 政治立场 意识形态 论证一致性 不确定性量化
📋 核心要点
- 现有方法难以区分LLM的真实意识形态倾向与单纯的文本生成模仿,无法准确评估其政治立场的稳定性。
- 论文提出Testing Conviction框架,通过论证一致性和不确定性量化来评估LLM意识形态的深度,从而区分真实立场和表演性行为。
- 实验结果表明,大部分LLM在不同实验条件下表现出与其分类一致的行为,语义熵也验证了分类的有效性(AUROC=0.78)。
📝 摘要(中文)
大型语言模型(LLM)日益影响政治讨论,但在受到挑战时表现出不一致的反应。先前的研究基于单一提示的响应将LLM归类为左倾或右倾,但一个关键问题仍然存在:这些分类反映的是稳定的意识形态还是表面的模仿?现有方法无法区分真正的意识形态一致性和表演性文本生成。为了解决这个问题,我们提出了一个框架,通过(1)论证一致性和(2)不确定性量化来评估意识形态的深度。在政治罗盘测试的19项经济政策上测试了12个LLM,我们将响应分类为稳定或表演性的意识形态定位。结果表明,95%的左倾模型和89%的右倾模型表现出与我们在不同实验条件下分类一致的行为。此外,语义熵强烈验证了我们的分类(AUROC=0.78),揭示了不确定性与意识形态一致性的关系。我们的研究结果表明,意识形态的稳定性是主题相关的,并挑战了LLM单一意识形态的观点,并提供了一种区分真实立场和表演行为的有效方法。
🔬 方法详解
问题定义:现有方法在评估大型语言模型(LLM)的政治立场时,主要依赖于单一提示的响应,这无法区分LLM是真正持有某种意识形态,还是仅仅在进行表演性的文本生成。因此,现有方法无法准确评估LLM政治立场的稳定性,以及其意识形态的深度。现有方法的痛点在于缺乏一种能够量化LLM在面对不同论证时的立场一致性的机制。
核心思路:论文的核心思路是通过构建一个论证框架,即Testing Conviction,来评估LLM在面对不同论证时的立场一致性。该框架的核心在于考察LLM在面对不同论证时,是否能够保持其最初的政治立场。如果LLM能够始终如一地支持或反对某个政策,则认为其具有稳定的意识形态。此外,论文还引入了不确定性量化,通过语义熵来衡量LLM在回答问题时的不确定性程度,从而进一步验证其立场的稳定性。这样设计的目的是为了区分LLM的真实立场和表演性行为,从而更准确地评估其政治立场的稳定性。
技术框架:Testing Conviction框架主要包含以下几个阶段:1. 问题构建:基于政治罗盘测试,构建一系列关于经济政策的问题,这些问题涵盖了不同的政治立场。2. LLM响应:将这些问题输入到不同的LLM中,并记录其响应。3. 论证一致性评估:评估LLM在面对不同论证时,是否能够保持其最初的政治立场。具体而言,通过分析LLM的响应,判断其是否始终如一地支持或反对某个政策。4. 不确定性量化:使用语义熵来衡量LLM在回答问题时的不确定性程度。5. 立场分类:根据论证一致性和不确定性量化结果,将LLM分类为具有稳定意识形态或表演性行为。
关键创新:论文最重要的技术创新点在于提出了一个论证框架,用于评估LLM的政治立场稳定性。与现有方法相比,该框架不仅考虑了LLM的初始响应,还考察了其在面对不同论证时的立场一致性。此外,论文还引入了不确定性量化,通过语义熵来衡量LLM在回答问题时的不确定性程度,从而进一步验证其立场的稳定性。这种方法能够更准确地评估LLM的政治立场,并区分其真实立场和表演性行为。
关键设计:在论证一致性评估方面,论文设计了一套规则,用于判断LLM的响应是否与其最初的政治立场一致。这些规则考虑了不同的论证方式和LLM的表达方式,以确保评估的准确性。在不确定性量化方面,论文使用了语义熵来衡量LLM在回答问题时的不确定性程度。语义熵是一种信息论的概念,可以用来衡量文本的复杂度和不确定性。论文选择语义熵是因为它可以有效地捕捉LLM在回答问题时的犹豫和矛盾,从而反映其立场的稳定性。
🖼️ 关键图片
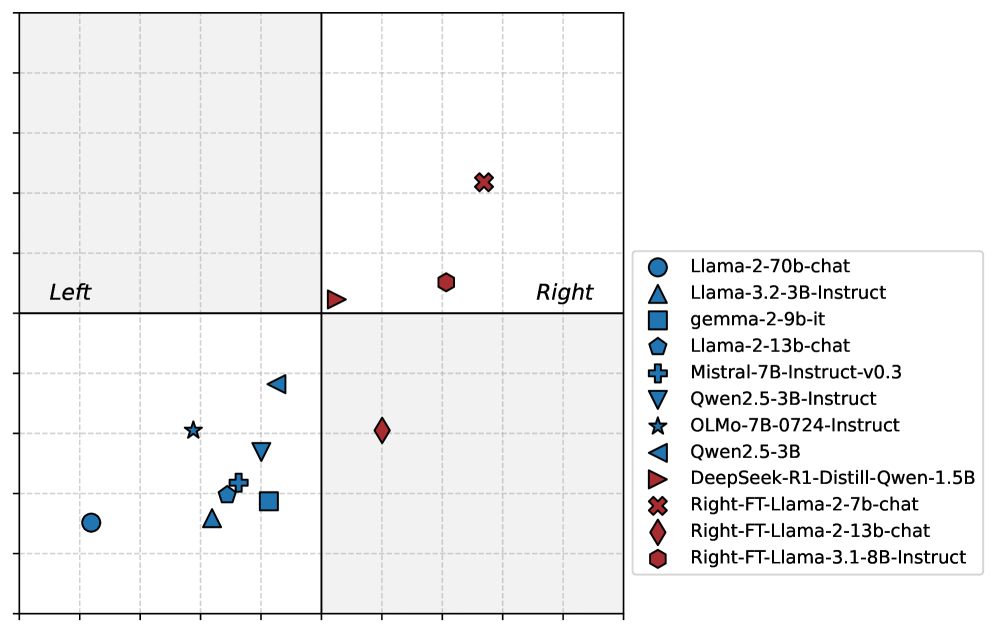


📊 实验亮点
实验结果表明,95%的左倾模型和89%的右倾模型表现出与论文分类一致的行为。语义熵能够有效验证LLM的立场稳定性,AUROC达到0.78。研究还发现,LLM的意识形态稳定性是主题相关的,挑战了LLM具有单一意识形态的观点。
🎯 应用场景
该研究成果可应用于评估大型语言模型在政治、社会等敏感领域的潜在风险,帮助开发者识别和缓解LLM可能存在的偏见或不稳定性。此外,该框架还可用于提高LLM在特定领域的可靠性和一致性,例如在政治辩论、政策咨询等场景中。
📄 摘要(原文)
Large Language Models (LLMs) increasingly shape political discourse, yet exhibit inconsistent responses when challenged. While prior research categorizes LLMs as left- or right-leaning based on single-prompt responses, a critical question remains: Do these classifications reflect stable ideologies or superficial mimicry? Existing methods cannot distinguish between genuine ideological alignment and performative text generation. To address this, we propose a framework for evaluating ideological depth through (1) argumentative consistency and (2) uncertainty quantification. Testing 12 LLMs on 19 economic policies from the Political Compass Test, we classify responses as stable or performative ideological positioning. Results show 95% of left-leaning models and 89% of right-leaning models demonstrate behavior consistent with our classifications across different experimental conditions. Furthermore, semantic entropy strongly validates our classifications (AUROC=0.78), revealing uncertainty's relationship to ideological consistency. Our findings demonstrate that ideological stability is topic-dependent and challenge the notion of monolithic LLM ideologies, and offer a robust way to distinguish genuine alignment from performative behavior.