MOOSComp: Improving Lightweight Long-Context Compressor via Mitigating Over-Smoothing and Incorporating Outlier Scores
作者: Fengwei Zhou, Jiafei Song, Wenjin Jason Li, Gengjian Xue, Zhikang Zhao, Yichao Lu, Bailin Na
分类: cs.CL, cs.LG
发布日期: 2025-04-23
💡 一句话要点
MOOSComp:通过缓解过平滑和引入异常值评分,改进轻量级长文本压缩
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本压缩 BERT 过平滑 异常值检测 token分类 资源受限环境 移动设备 模型优化
📋 核心要点
- 现有长文本处理方法在资源受限场景下,推理时间和资源消耗过高,限制了实际应用。
- MOOSComp通过缓解过平滑问题和引入异常值评分,提升BERT压缩器的性能,保留关键信息。
- 实验表明,MOOSComp在长文本理解和推理任务上表现优异,并在移动设备上实现了显著加速。
📝 摘要(中文)
大型语言模型在处理长文本输入方面取得了显著进展,但实际应用中面临推理时间和资源消耗增加的挑战,尤其是在资源受限的环境中。为了解决这些挑战,我们提出了一种基于token分类的长文本压缩方法MOOSComp,它通过缓解过平滑问题和引入异常值评分来增强基于BERT的压缩器的性能。在训练阶段,我们增加了一个类间余弦相似度损失项,以惩罚过度相似的token表示,从而提高token分类的准确性。在压缩阶段,我们引入异常值评分来保留在任务无关压缩中容易被丢弃的稀有但关键的token。这些评分与分类器的输出相结合,使压缩器更具通用性,适用于各种任务。在长文本理解和推理基准测试中,在各种压缩率下都取得了优异的性能。此外,我们的方法在资源受限的移动设备上以4倍压缩率实现了3.3倍的加速。
🔬 方法详解
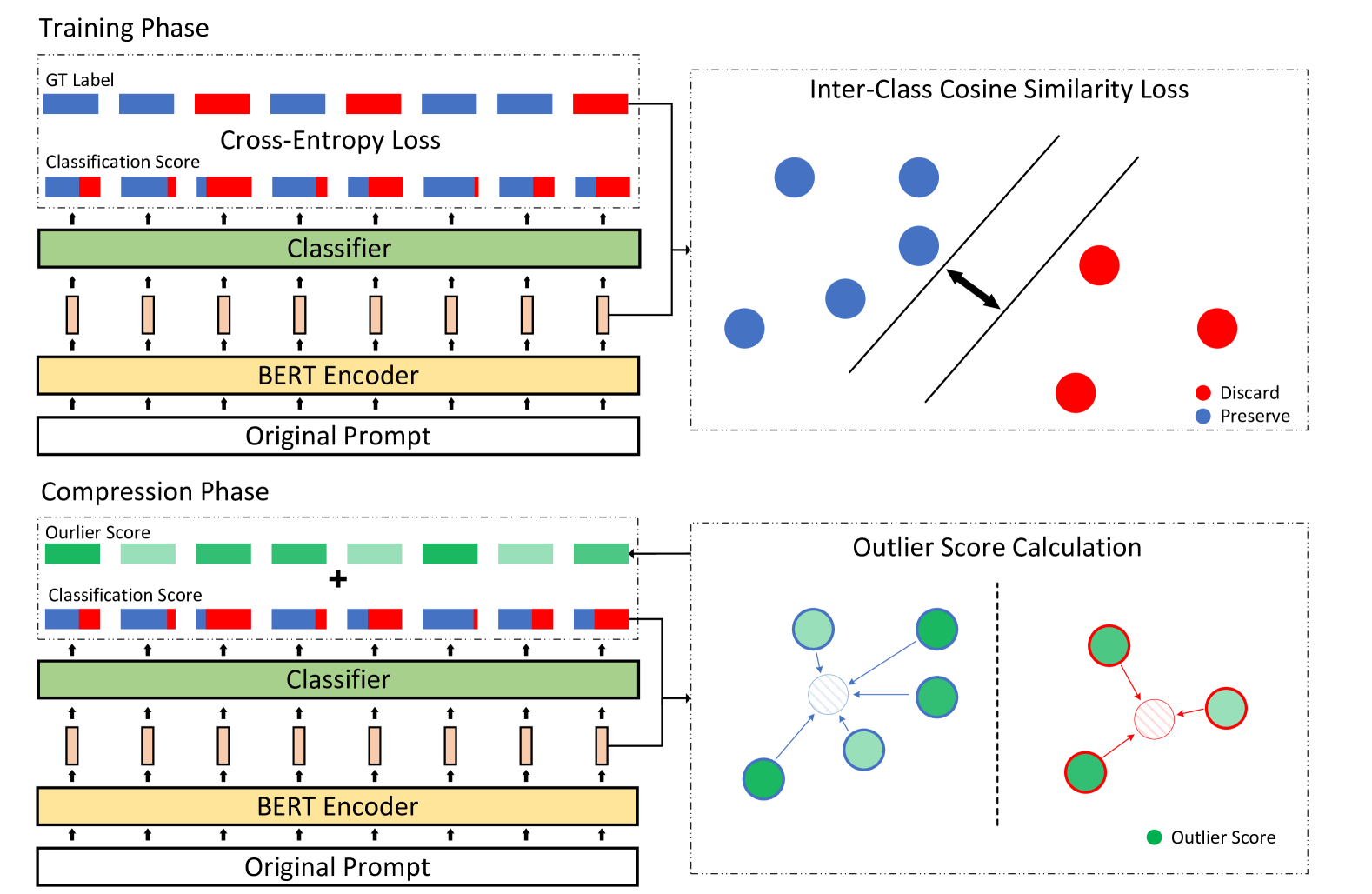
问题定义:现有基于BERT的文本压缩方法在长文本处理中存在过平滑问题,导致token表示过于相似,降低了分类精度。此外,任务无关的压缩方法容易丢弃一些稀有但关键的token,影响下游任务的性能。
核心思路:MOOSComp的核心思路是通过引入类间余弦相似度损失来缓解过平滑问题,并利用异常值评分来保留重要的稀有token。通过结合分类器输出和异常值评分,提高压缩器在不同任务上的泛化能力。
技术框架:MOOSComp包含训练和压缩两个阶段。在训练阶段,使用BERT模型进行token分类,并加入类间余弦相似度损失。在压缩阶段,计算每个token的异常值评分,并将其与分类器的输出结合,决定是否保留该token。整体流程是:输入长文本 -> BERT编码 -> token分类 -> 异常值评分 -> 压缩输出。
关键创新:MOOSComp的关键创新在于:1) 提出了类间余弦相似度损失,有效缓解了过平滑问题,提高了token分类的准确性。2) 引入了异常值评分,能够保留重要的稀有token,提升了压缩器在不同任务上的泛化能力。与现有方法相比,MOOSComp更加关注token表示的区分性和关键信息的保留。
关键设计:类间余弦相似度损失旨在惩罚不同类别token表示之间的相似性,其具体形式为:L_inter = Σ cos(v_i, v_j),其中v_i和v_j分别属于不同的类别。异常值评分的计算方式未知,但其目的是衡量token的重要性。在压缩阶段,将分类器输出和异常值评分进行加权融合,以决定是否保留该token。
🖼️ 关键图片


📊 实验亮点
MOOSComp在长文本理解和推理基准测试中取得了优异的性能,证明了其有效性。在资源受限的移动设备上,以4倍压缩率实现了3.3倍的加速,显著提升了推理效率。这些结果表明,MOOSComp是一种高效且实用的长文本压缩方法。
🎯 应用场景
MOOSComp适用于资源受限环境下的长文本处理,例如移动设备上的文档摘要、智能问答和信息检索。该方法可以有效降低计算成本和存储需求,提高长文本处理的效率和可用性。未来可应用于边缘计算、物联网等领域,为资源有限的设备提供强大的长文本处理能力。
📄 摘要(原文)
Recent advances in large language models have significantly improved their ability to process long-context input, but practical applications are challenged by increased inference time and resource consumption, particularly in resource-constrained environments. To address these challenges, we propose MOOSComp, a token-classification-based long-context compression method that enhances the performance of a BERT-based compressor by mitigating the over-smoothing problem and incorporating outlier scores. In the training phase, we add an inter-class cosine similarity loss term to penalize excessively similar token representations, thereby improving the token classification accuracy. During the compression phase, we introduce outlier scores to preserve rare but critical tokens that are prone to be discarded in task-agnostic compression. These scores are integrated with the classifier's output, making the compressor more generalizable to various tasks. Superior performance is achieved at various compression ratios on long-context understanding and reasoning benchmarks. Moreover, our method obtains a speedup of 3.3x at a 4x compression ratio on a resource-constrained mobile device.