Comparing Large Language Models and Traditional Machine Translation Tools for Translating Medical Consultation Summaries: A Pilot Study
作者: Andy Li, Wei Zhou, Rashina Hoda, Chris Bain, Peter Poon
分类: cs.CL, cs.AI
发布日期: 2025-04-23
备注: 8 pages, 2 tables and 1 Figure
💡 一句话要点
对比大型语言模型与传统机器翻译工具在医疗咨询摘要翻译中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器翻译 大型语言模型 医疗咨询摘要 多语言翻译 性能评估
📋 核心要点
- 现有机器翻译工具在医学领域的翻译质量仍有提升空间,尤其是在处理复杂医学文本时。
- 该研究对比了大型语言模型和传统机器翻译工具在医疗咨询摘要翻译任务中的表现。
- 实验结果表明,传统机器翻译工具在复杂文本翻译中表现更优,而大型语言模型在简单文本翻译中展现潜力。
📝 摘要(中文)
本研究评估了大型语言模型(LLM)和传统机器翻译(MT)工具将医疗咨询摘要从英语翻译成阿拉伯语、中文和越南语的效果。评估使用了标准自动化指标,针对患者友好型和临床医生关注型文本。结果表明,传统MT工具通常表现更好,尤其是在翻译复杂文本时。LLM在翻译更简单的摘要时显示出潜力,尤其是在越南语和中文方面。由于阿拉伯语的形态学特点,其翻译质量随着文本复杂性的增加而提高。总的来说,虽然LLM提供了上下文灵活性,但它们仍然不稳定,并且当前的评估指标未能捕捉到临床相关性。该研究强调了医学翻译中领域特定训练、改进的评估方法和人工监督的必要性。
🔬 方法详解
问题定义:该论文旨在评估和比较大型语言模型(LLM)和传统机器翻译(MT)工具在医疗咨询摘要翻译任务中的性能。现有方法,特别是通用型的机器翻译工具,在处理医学领域的专业术语和复杂语境时,可能无法保证翻译的准确性和流畅性,从而影响医患沟通和临床决策。
核心思路:论文的核心思路是通过实验对比LLM和传统MT工具在不同语言(阿拉伯语、中文、越南语)和不同文本类型(患者友好型、临床医生关注型)的医疗咨询摘要翻译任务中的表现,从而分析各自的优缺点,并为医学翻译提供指导。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 收集英文医疗咨询摘要,并将其分为患者友好型和临床医生关注型两类;2) 使用LLM和传统MT工具将英文摘要翻译成阿拉伯语、中文和越南语;3) 使用标准自动化指标(具体指标未知)评估翻译质量;4) 分析实验结果,比较LLM和传统MT工具的性能,并探讨影响翻译质量的因素。
关键创新:该研究的关键创新在于将LLM应用于医疗咨询摘要翻译任务,并与传统MT工具进行对比分析。这有助于了解LLM在医学翻译领域的潜力和局限性,并为未来开发更有效的医学翻译系统提供参考。此外,该研究还关注了不同语言和文本类型对翻译质量的影响,从而更全面地评估了LLM和传统MT工具的性能。
关键设计:论文中关于LLM和传统MT工具的具体选择、自动化评估指标的选择以及实验参数的设置等关键设计细节未知。但可以推测,研究者可能选择了具有代表性的LLM(例如,GPT系列)和传统MT工具(例如,Google Translate、Microsoft Translator),并使用了BLEU、METEOR等常用的机器翻译评估指标。
🖼️ 关键图片
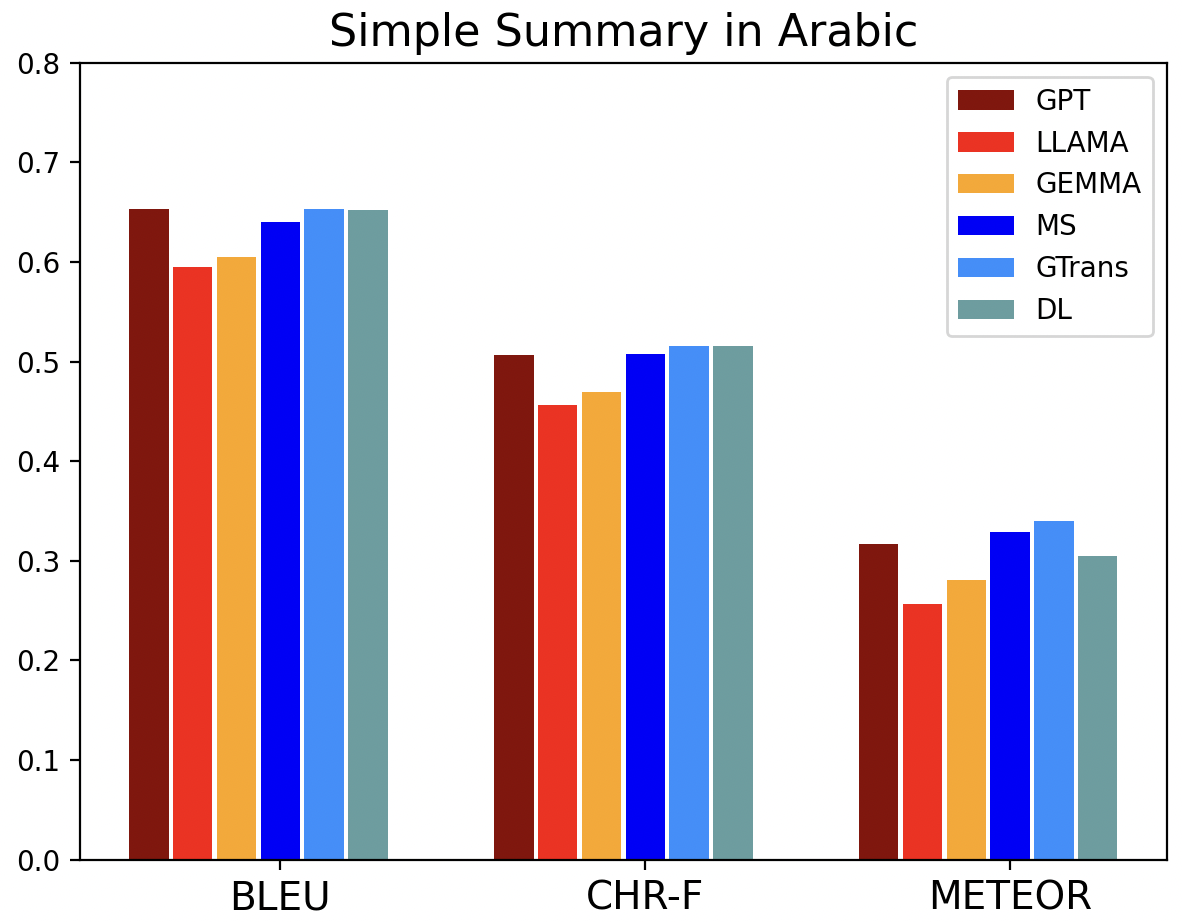
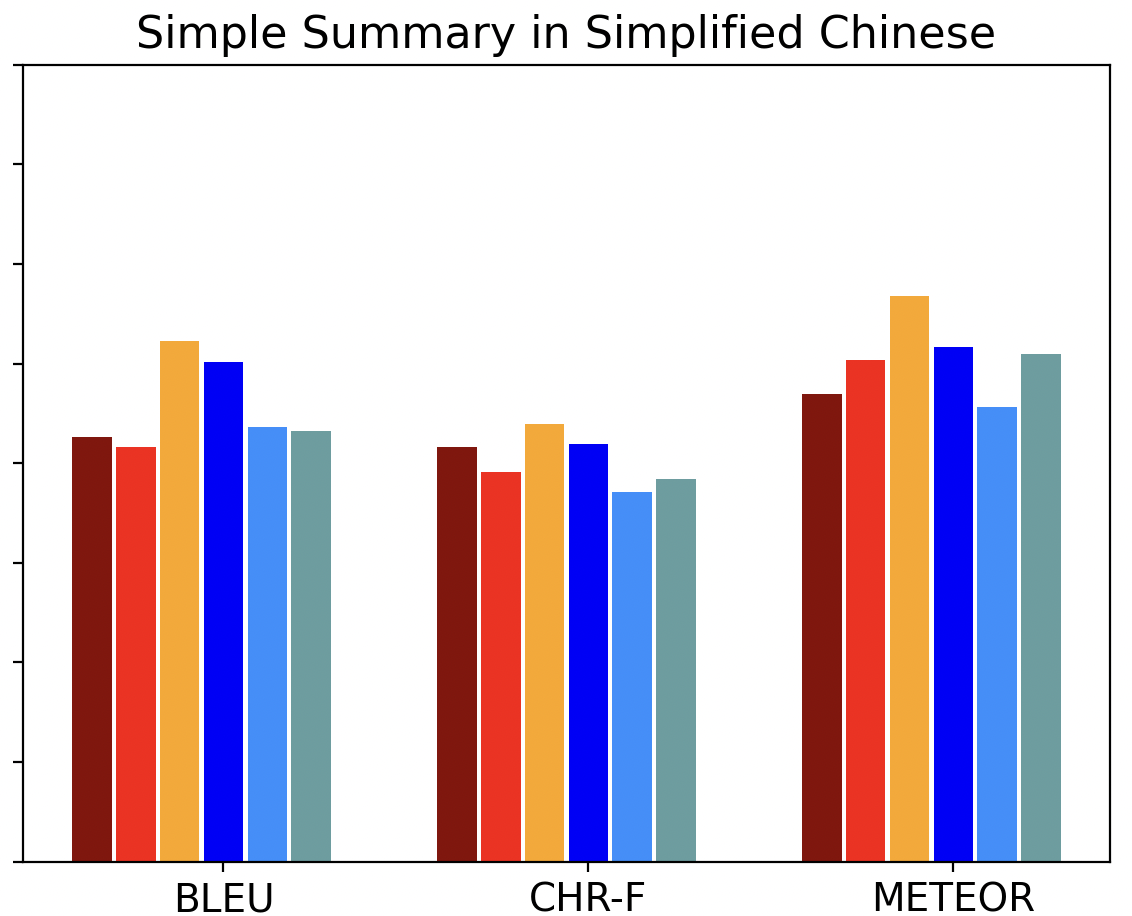

📊 实验亮点
实验结果表明,传统机器翻译工具在翻译复杂医疗文本时通常表现更好,而大型语言模型在翻译简单摘要时展现出潜力,尤其是在越南语和中文的翻译中。阿拉伯语翻译质量随文本复杂性增加而提高,这可能与该语言的形态学特性有关。具体性能数据和提升幅度未知。
🎯 应用场景
该研究成果可应用于开发更准确、更高效的医学翻译系统,辅助医患沟通,提高医疗服务的可及性和质量。未来,结合领域知识和人工监督,有望构建更加智能化的医学翻译工具,促进全球医疗信息的交流与共享。
📄 摘要(原文)
This study evaluates how well large language models (LLMs) and traditional machine translation (MT) tools translate medical consultation summaries from English into Arabic, Chinese, and Vietnamese. It assesses both patient, friendly and clinician, focused texts using standard automated metrics. Results showed that traditional MT tools generally performed better, especially for complex texts, while LLMs showed promise, particularly in Vietnamese and Chinese, when translating simpler summaries. Arabic translations improved with complexity due to the language's morphology. Overall, while LLMs offer contextual flexibility, they remain inconsistent, and current evaluation metrics fail to capture clinical relevance. The study highlights the need for domain-specific training, improved evaluation methods, and human oversight in medical translation.