Evaluating Multi-Hop Reasoning in Large Language Models: A Chemistry-Centric Case Study
作者: Mohammad Khodadad, Ali Shiraee Kasmaee, Mahdi Astaraki, Nicholas Sherck, Hamidreza Mahyar, Soheila Samiee
分类: cs.CL
发布日期: 2025-04-23 (更新: 2025-08-06)
💡 一句话要点
提出化学领域多跳推理基准,评估大型语言模型的复杂推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多跳推理 化学领域 知识图谱 命名实体识别
📋 核心要点
- 现有大型语言模型在复杂的多跳推理任务中表现不足,尤其是在需要专业知识的化学领域。
- 论文提出一种自动化的数据生成流程,构建化学领域的多跳推理数据集,并结合知识图谱增强LLM的推理能力。
- 实验表明,即使是先进的LLM在多跳推理中仍面临挑战,文档检索增强能显著提升性能,但无法完全消除推理错误。
📝 摘要(中文)
本研究提出了一个新的基准,包含一个精心策划的数据集和一个明确的评估流程,旨在评估大型语言模型在化学领域内的组合推理能力。我们设计并验证了一个完全自动化的流程,并由领域专家进行了验证,以促进这项任务。我们的方法集成了 OpenAI 推理模型与命名实体识别 (NER) 系统,从最新文献中提取化学实体,然后使用外部知识库对其进行增强,从而形成一个全面的知识图谱。通过在这些图谱上生成多跳问题,我们评估了 LLM 在上下文增强和非上下文增强设置中的性能。实验表明,即使是最先进的模型在多跳组合推理方面也面临着重大挑战。结果反映了使用文档检索增强 LLM 的重要性,这可以对提高其性能产生重大影响。然而,即使在完全上下文的情况下实现完美的检索准确率,也无法消除推理错误,这突显了组合推理的复杂性。这项工作不仅对当前 LLM 的局限性进行了基准测试和强调,还提出了一个新颖的数据生成流程,能够生成跨各种领域的具有挑战性的推理数据集。总的来说,这项研究提高了我们对计算语言学中推理的理解。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在化学领域进行多跳组合推理的能力。现有的LLM在处理需要多个推理步骤和领域知识的问题时表现不佳,尤其是在化学这种专业性强的领域。现有的数据集和评估方法难以充分衡量LLM的推理能力,缺乏针对化学领域多跳推理的专门基准。
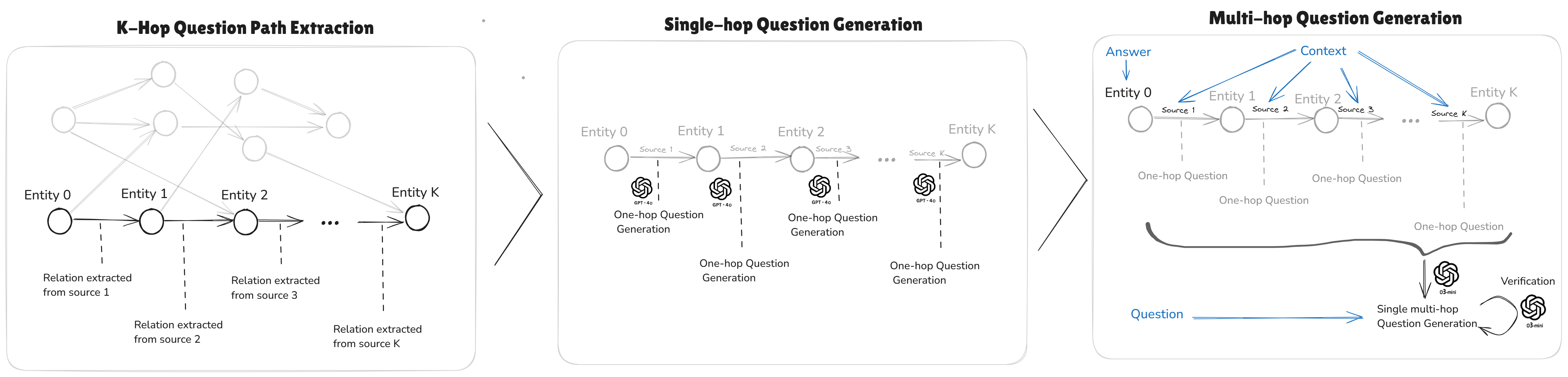
核心思路:论文的核心思路是构建一个化学领域的多跳推理数据集,并设计一个自动化的评估流程,以系统地评估LLM的推理能力。通过结合命名实体识别(NER)和知识图谱,从化学文献中提取信息,并生成多跳问题,从而考察LLM在不同上下文条件下的推理表现。
技术框架:整体框架包含以下几个主要模块:1) 数据收集与预处理:从化学文献中提取文本数据,并使用NER系统识别化学实体。2) 知识图谱构建:利用提取的化学实体和外部知识库(未知),构建化学领域的知识图谱。3) 问题生成:基于知识图谱,自动生成多跳推理问题,包括上下文增强和非上下文增强两种类型。4) LLM推理:使用OpenAI的推理模型(具体型号未知)对生成的问题进行推理。5) 评估:根据预定义的评估指标,评估LLM的推理性能。
关键创新:论文的关键创新在于提出了一个完全自动化的数据生成流程,能够高效地构建化学领域的多跳推理数据集。该流程结合了NER、知识图谱和问题生成技术,能够生成具有挑战性的推理问题,并支持上下文增强和非上下文增强两种设置。此外,该流程具有通用性,可以应用于其他领域,生成类似的推理数据集。
关键设计:论文中关于参数设置、损失函数、网络结构等技术细节描述较少,具体设计未知。但可以推测,NER系统的选择和知识图谱的构建方式对最终的数据集质量和评估结果有重要影响。问题生成策略的设计也至关重要,需要保证生成的问题既具有挑战性,又能够反映LLM的真实推理能力。
🖼️ 关键图片


📊 实验亮点
实验结果表明,即使是最先进的LLM在化学领域的多跳推理任务中也面临显著挑战。文档检索增强可以显著提高LLM的性能,但即使在完美检索的情况下,仍然存在推理错误。这表明LLM的推理能力仍有很大的提升空间,需要进一步研究更有效的推理方法和知识表示方式。
🎯 应用场景
该研究成果可应用于开发更智能的化学信息检索系统、化学知识问答系统和化学研究辅助工具。通过提高LLM在化学领域的推理能力,可以加速新材料的发现、药物研发和化学反应预测等过程。未来,该方法可推广到其他专业领域,提升LLM在各领域的应用价值。
📄 摘要(原文)
In this study, we introduced a new benchmark consisting of a curated dataset and a defined evaluation process to assess the compositional reasoning capabilities of large language models within the chemistry domain. We designed and validated a fully automated pipeline, verified by subject matter experts, to facilitate this task. Our approach integrates OpenAI reasoning models with named entity recognition (NER) systems to extract chemical entities from recent literature, which are then augmented with external knowledge bases to form a comprehensive knowledge graph. By generating multi-hop questions across these graphs, we assess LLM performance in both context-augmented and non-context augmented settings. Our experiments reveal that even state-of-the-art models face significant challenges in multi-hop compositional reasoning. The results reflect the importance of augmenting LLMs with document retrieval, which can have a substantial impact on improving their performance. However, even perfect retrieval accuracy with full context does not eliminate reasoning errors, underscoring the complexity of compositional reasoning. This work not only benchmarks and highlights the limitations of current LLMs but also presents a novel data generation pipeline capable of producing challenging reasoning datasets across various domains. Overall, this research advances our understanding of reasoning in computational linguistics.