Dynamic Early Exit in Reasoning Models
作者: Chenxu Yang, Qingyi Si, Yongjie Duan, Zheliang Zhu, Chenyu Zhu, Qiaowei Li, Minghui Chen, Zheng Lin, Weiping Wang
分类: cs.CL, cs.AI
发布日期: 2025-04-22 (更新: 2025-09-28)
备注: 41 pages, 18 figures
💡 一句话要点
提出动态早期退出机制以提升推理模型效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推理模型 动态早期退出 长思维链 模型效率 准确性提升
📋 核心要点
- 现有的推理模型在处理复杂任务时,长思维链生成导致效率低下和准确性下降。
- 本文提出了一种动态早期退出机制,允许模型在生成过程中自我截断推理链,提升效率。
- 实验表明,该方法在多个推理基准上显著减少了推理链长度,并提高了模型的准确性。
📝 摘要(中文)
近年来,大型推理语言模型(LRLMs)的进展依赖于测试时扩展,这种方法通过延长思维链(CoT)生成来解决复杂任务。然而,过度思考导致的冗长推理不仅降低了解题效率,还可能因过于详细或冗余的推理步骤而影响准确性。本文提出了一种简单而有效的方法,允许LLMs在生成过程中自我截断CoT序列,通过动态监测模型在潜在推理转折点的行为,在模型对试探性答案表现出高信心时提前终止下一推理链的生成。该方法无需额外训练,可无缝集成到现有的o1类推理LLMs中。实验结果显示,该方法在10个推理基准上对11种不同系列和规模的前沿推理LLMs均表现出一致的有效性,平均减少CoT序列长度19.1%至80.1%,同时提高准确率0.3%至5.0%。
🔬 方法详解
问题定义:本文旨在解决长思维链生成导致的推理效率低下和准确性损失问题。现有方法依赖固定启发式,无法灵活应对模型的实际推理情况。
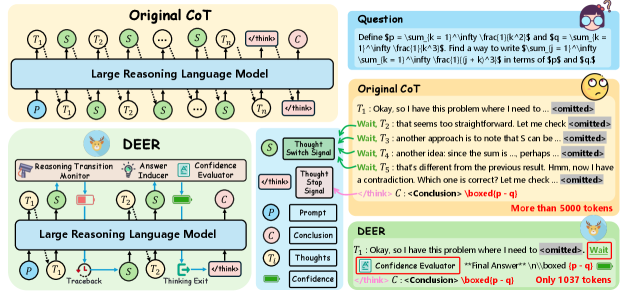
核心思路:提出一种动态早期退出机制,通过监测模型在推理过程中的信心水平,允许模型在达到高信心时提前终止推理链的生成,从而减少冗余步骤。
技术框架:整体架构包括输入处理、推理监测和动态退出三个主要模块。输入处理模块负责接收问题并生成初步推理,推理监测模块实时评估模型信心,动态退出模块则在信心达到阈值时终止生成。
关键创新:最重要的创新在于动态监测模型行为并根据信心水平自我截断推理链,这与传统的固定启发式方法形成鲜明对比,提升了灵活性和效率。
关键设计:该方法不需要额外的训练,设计上通过设定信心阈值来决定何时退出,确保在保持准确性的同时,显著减少推理步骤。
🖼️ 关键图片
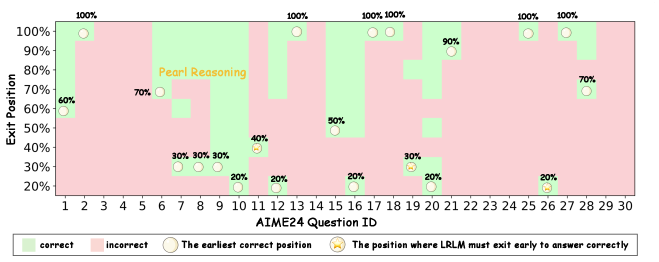
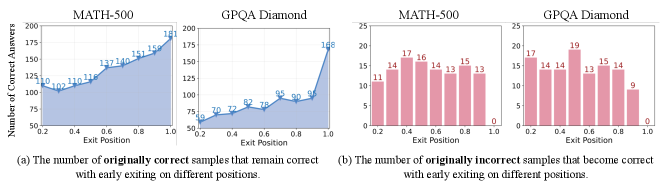
📊 实验亮点
实验结果显示,所提方法在11种前沿推理LLMs上均表现出色,平均减少CoT序列长度19.1%至80.1%,同时提高准确率0.3%至5.0%。这些结果表明,动态早期退出机制在推理效率和准确性方面具有显著优势。
🎯 应用场景
该研究的潜在应用领域包括教育、自动问答系统和复杂决策支持等场景。通过提升推理效率和准确性,能够为用户提供更快速、更可靠的智能服务,具有重要的实际价值和未来影响。
📄 摘要(原文)
Recent advances in large reasoning language models (LRLMs) rely on test-time scaling, which extends long chain-of-thought (CoT) generation to solve complex tasks. However, overthinking in long CoT not only slows down the efficiency of problem solving, but also risks accuracy loss due to the extremely detailed or redundant reasoning steps. We propose a simple yet effective method that allows LLMs to self-truncate CoT sequences by early exit during generation. Instead of relying on fixed heuristics, the proposed method monitors model behavior at potential reasoning transition points and dynamically terminates the next reasoning chain's generation when the model exhibits high confidence in a trial answer. Our method requires no additional training and can be seamlessly integrated into existing o1-like reasoning LLMs. Experiments on 10 reasoning benchmarks (e.g., GSM8K, MATH-500, AMC, GPQA, AIME and LiveCodeBench) show that the proposed method is consistently effective on 11 cutting-edge reasoning LLMs of varying series and sizes, reducing the length of CoT sequences by an average of 19.1% to 80.1% while improving accuracy by 0.3% to 5.0%.