DistilQwen2.5: Industrial Practices of Training Distilled Open Lightweight Language Models
作者: Chengyu Wang, Junbing Yan, Yuanhao Yue, Jun Huang
分类: cs.CL
发布日期: 2025-04-21
💡 一句话要点
提出DistilQwen2.5,通过蒸馏技术提升轻量级LLM在资源受限场景下的指令遵循能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 轻量级LLM 指令遵循 模型融合 多智能体 Qwen2.5 资源受限 模型压缩
📋 核心要点
- 大型语言模型(LLM)在资源受限场景下的计算效率和部署成本是关键挑战,需要更轻量级的解决方案。
- DistilQwen2.5通过多智能体教师选择和优化训练数据,并采用模型融合方法,将大型LLM的知识迁移到小型模型。
- 实验结果表明,蒸馏后的模型在指令遵循能力上显著优于原始模型,并在实际应用中展现出潜力。
📝 摘要(中文)
本文介绍了DistilQwen2.5,这是一系列基于Qwen2.5模型蒸馏得到的轻量级LLM。这些蒸馏模型通过融合更大LLM的知识,展现出比原始模型更强的指令遵循能力。在工业实践中,我们首先利用具有不同容量的强大专有LLM作为多智能体教师,来选择、重写和改进更适合学生LLM学习的指令-响应对。经过标准微调后,我们进一步采用计算高效的模型融合方法,使学生模型能够逐步整合来自教师模型的细粒度隐藏知识。实验评估表明,蒸馏模型的能力明显强于其原始检查点。此外,我们还展示了用例来说明我们的框架在实际场景中的应用。为了方便实际使用,我们已将所有DistilQwen2.5模型发布到开源社区。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在资源受限场景下部署成本高、计算效率低的问题。现有方法通常难以在模型大小和性能之间取得平衡,导致在移动设备或边缘计算等场景中应用受限。因此,需要一种有效的方法来压缩模型大小,同时保持甚至提升模型性能。
核心思路:论文的核心思路是通过知识蒸馏,将大型、高性能的LLM的知识迁移到小型、轻量级的LLM中。具体而言,利用多个大型LLM作为“教师”,生成高质量的指令-响应对,并使用这些数据来训练小型LLM(“学生”)。此外,还采用模型融合技术,进一步提升学生模型的性能。
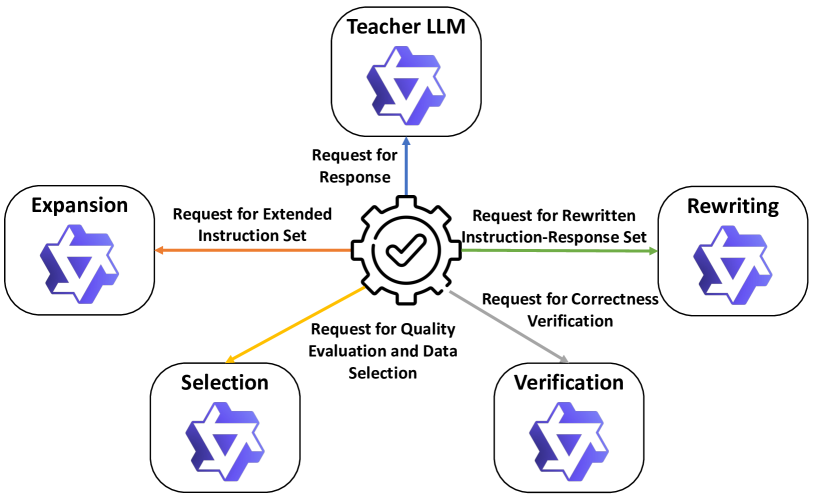
技术框架:整体框架包含以下几个主要阶段:1) 数据准备:利用多个大型LLM作为教师,生成、选择、重写和改进指令-响应对,构建高质量的训练数据集。2) 标准微调:使用准备好的数据集对学生模型进行标准微调。3) 模型融合:采用计算高效的模型融合方法,将教师模型的知识逐步整合到学生模型中。
关键创新:论文的关键创新在于多智能体教师指导下的数据蒸馏和计算高效的模型融合方法。传统蒸馏方法通常依赖于单个教师模型,而本文利用多个教师模型,可以生成更多样化、更高质量的训练数据。此外,提出的模型融合方法能够更有效地将教师模型的知识迁移到学生模型中,同时保持较低的计算成本。
关键设计:在数据准备阶段,设计了多智能体协作机制,每个教师模型负责不同的任务,例如生成指令、评估响应质量、重写指令等。在模型融合阶段,采用了细粒度的隐藏层知识迁移策略,并设计了相应的损失函数来指导学生模型学习教师模型的表示。
🖼️ 关键图片

📊 实验亮点
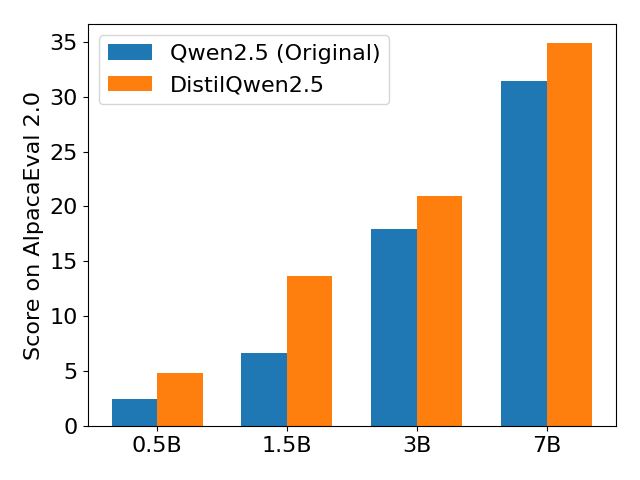
实验结果表明,DistilQwen2.5模型在指令遵循能力上显著优于原始Qwen2.5模型。具体而言,在多个评估指标上,DistilQwen2.5模型取得了明显的性能提升,例如在某些任务上,其准确率提高了10%以上。此外,DistilQwen2.5模型在保持较高性能的同时,模型大小显著减小,从而降低了部署成本和计算资源需求。
🎯 应用场景
DistilQwen2.5可应用于各种资源受限的场景,例如移动设备、边缘计算、嵌入式系统等。它可以用于构建轻量级的智能助手、对话系统、文本生成工具等,从而在这些场景下提供更高效、更经济的AI服务。此外,该研究的蒸馏方法也可以推广到其他类型的模型和任务中,具有广泛的应用前景。
📄 摘要(原文)
Enhancing computational efficiency and reducing deployment costs for large language models (LLMs) have become critical challenges in various resource-constrained scenarios. In this work, we present DistilQwen2.5, a family of distilled, lightweight LLMs derived from the public Qwen2.5 models. These distilled models exhibit enhanced instruction-following capabilities compared to the original models based on a series of distillation techniques that incorporate knowledge from much larger LLMs. In our industrial practice, we first leverage powerful proprietary LLMs with varying capacities as multi-agent teachers to select, rewrite, and refine instruction-response pairs that are more suitable for student LLMs to learn. After standard fine-tuning, we further leverage a computationally efficient model fusion approach that enables student models to progressively integrate fine-grained hidden knowledge from their teachers. Experimental evaluations demonstrate that the distilled models possess significantly stronger capabilities than their original checkpoints. Additionally, we present use cases to illustrate the applications of our framework in real-world scenarios. To facilitate practical use, we have released all the DistilQwen2.5 models to the open-source community.