A Hierarchical Framework for Measuring Scientific Paper Innovation via Large Language Models
作者: Hongming Tan, Shaoxiong Zhan, Fengwei Jia, Hai-Tao Zheng, Wai Kin Chan
分类: cs.CL
发布日期: 2025-04-20 (更新: 2025-10-24)
DOI: 10.1016/j.ins.2025.122787
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于大语言模型的层级框架HSPIM,用于评估科学论文的创新性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 论文创新性评估 大型语言模型 层级框架 零样本学习 问答增强
📋 核心要点
- 现有方法在评估论文创新性时,忽略全文上下文,难以捕捉创新全貌,且泛化能力不足。
- HSPIM框架通过层级分解,利用LLM进行章节分类、问答增强和加权评分,从而评估论文创新性。
- 实验结果表明,HSPIM在有效性、泛化性和可解释性方面均优于现有基线方法。
📝 摘要(中文)
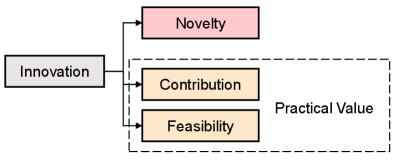
评估科学论文的创新性既重要又具有挑战性。现有的基于内容的方法通常忽略全文语境,无法捕捉创新的全部范围,并且缺乏泛化能力。我们提出了HSPIM,一个基于大型语言模型(LLM)的层级且无需训练的框架。它引入了“论文到章节到问答”的分解方法来评估创新性。我们按章节标题分割文本,并使用零样本LLM提示来实现章节分类、问答(QA)增强和加权创新评分。生成的QA对侧重于章节级别的创新,并作为额外的上下文来改进LLM评分。对于每个文本块,LLM输出一个新颖性得分和一个置信度得分。我们使用置信度得分作为权重,将新颖性得分聚合为论文级别的创新得分。为了进一步提高性能,我们提出了一种由通用问题和特定章节问题组成的两层问题结构,并应用遗传算法来优化问题提示组合。此外,在细粒度的创新结构下,我们将HSPIM扩展到HSPIM$^+$,生成新颖性、贡献和可行性得分以及各自的置信度得分。在科学会议论文数据集上的综合实验表明,HSPIM在有效性、泛化性和可解释性方面优于基线方法。演示代码可在https://github.com/Jasaxion/HSPIM获得。
🔬 方法详解
问题定义:现有方法在评估科学论文创新性时存在局限性,主要体现在无法充分利用全文信息,对创新性的理解不够全面,并且在不同领域或数据集上的泛化能力较差。这些方法通常只关注论文的某些特定部分,而忽略了论文整体的上下文信息,导致评估结果不够准确和可靠。
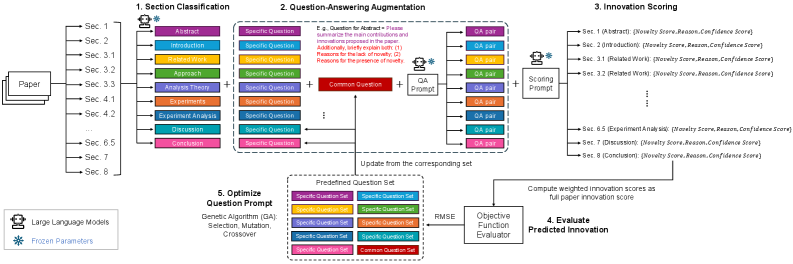
核心思路:HSPIM的核心思路是将论文创新性的评估分解为多个层级,从论文整体到章节,再到基于问答的细粒度分析。通过这种层级结构,可以更全面地理解论文的创新点。同时,利用大型语言模型(LLM)的强大能力,实现自动化的章节分类、问答生成和创新性评分,从而提高评估的效率和准确性。
技术框架:HSPIM框架主要包含以下几个模块:1) 章节分割:根据论文的章节标题将论文文本分割成多个章节。2) 章节分类:利用LLM对每个章节进行分类,确定其所属的研究领域或主题。3) 问答增强:针对每个章节,利用LLM生成一系列与创新性相关的问答对,作为额外的上下文信息。4) 创新性评分:利用LLM对每个章节进行创新性评分,并给出相应的置信度。5) 论文级创新性评分:根据章节的创新性评分和置信度,加权聚合得到论文级别的创新性评分。
关键创新:HSPIM的关键创新在于其层级分解的评估方法和基于LLM的自动化流程。与现有方法相比,HSPIM能够更全面地利用论文的上下文信息,更准确地捕捉论文的创新点。此外,HSPIM还引入了置信度评分机制,可以更好地反映评估结果的可靠性。两层问题结构和遗传算法优化问题提示组合也是提升性能的关键。
关键设计:HSPIM的关键设计包括:1) 两层问题结构:设计通用问题和特定章节问题,以更全面地评估创新性。2) 遗传算法优化:使用遗传算法自动优化问题提示组合,以提高LLM的评分准确性。3) 加权聚合:使用置信度作为权重,将章节级别的创新性评分聚合为论文级别的评分,从而提高评估结果的可靠性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,HSPIM在科学会议论文数据集上取得了显著的性能提升,在有效性、泛化性和可解释性方面均优于基线方法。具体性能数据未知,但摘要强调了HSPIM的优越性。
🎯 应用场景
HSPIM可应用于科研评价、论文推荐、基金评审等领域。它可以帮助科研人员快速了解论文的创新性,辅助编辑和审稿人进行更客观的评价,并为基金评审提供更全面的参考信息。该研究有助于推动科学研究的创新和发展。
📄 摘要(原文)
Measuring scientific paper innovation is both important and challenging. Existing content-based methods often overlook the full-paper context, fail to capture the full scope of innovation, and lack generalization. We propose HSPIM, a hierarchical and training-free framework based on large language models (LLMs). It introduces a Paper-to-Sections-to-QAs decomposition to assess innovation. We segment the text by section titles and use zero-shot LLM prompting to implement section classification, question-answering (QA) augmentation, and weighted innovation scoring. The generated QA pair focuses on section-level innovation and serves as additional context to improve the LLM scoring. For each chunk, the LLM outputs a novelty score and a confidence score. We use confidence scores as weights to aggregate novelty scores into a paper-level innovation score. To further improve performance, we propose a two-layer question structure consisting of common and section-specific questions, and apply a genetic algorithm to optimize the question-prompt combinations. Furthermore, under the fine-grained structure of innovation, we extend HSPIM to an HSPIM$^+$ that generates novelty, contribution, and feasibility scores with respective confidence scores. Comprehensive experiments on scientific conference paper datasets show that HSPIM outperforms baseline methods in effectiveness, generalization, and interpretability. Demo code is available at https://github.com/Jasaxion/HSPIM.