Meta-rater: A Multi-dimensional Data Selection Method for Pre-training Language Models
作者: Xinlin Zhuang, Jiahui Peng, Ren Ma, Yinfan Wang, Tianyi Bai, Xingjian Wei, Jiantao Qiu, Chi Zhang, Ying Qian, Conghui He
分类: cs.CL
发布日期: 2025-04-19 (更新: 2025-08-06)
备注: ACL 2025 Best Theme Paper Award
🔗 代码/项目: GITHUB
💡 一句话要点
Meta-rater:一种面向预训练语言模型的多维度数据选择方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 预训练语言模型 数据选择 数据质量评估 多维度评估 代理模型
📋 核心要点
- 现有数据选择方法在评估预训练数据质量时,通常局限于单一维度或侧重于去除冗余,无法全面衡量数据价值。
- Meta-rater通过综合专业性、可读性、推理能力和清洁度四个维度,并学习最优权重,实现多维度数据质量评估。
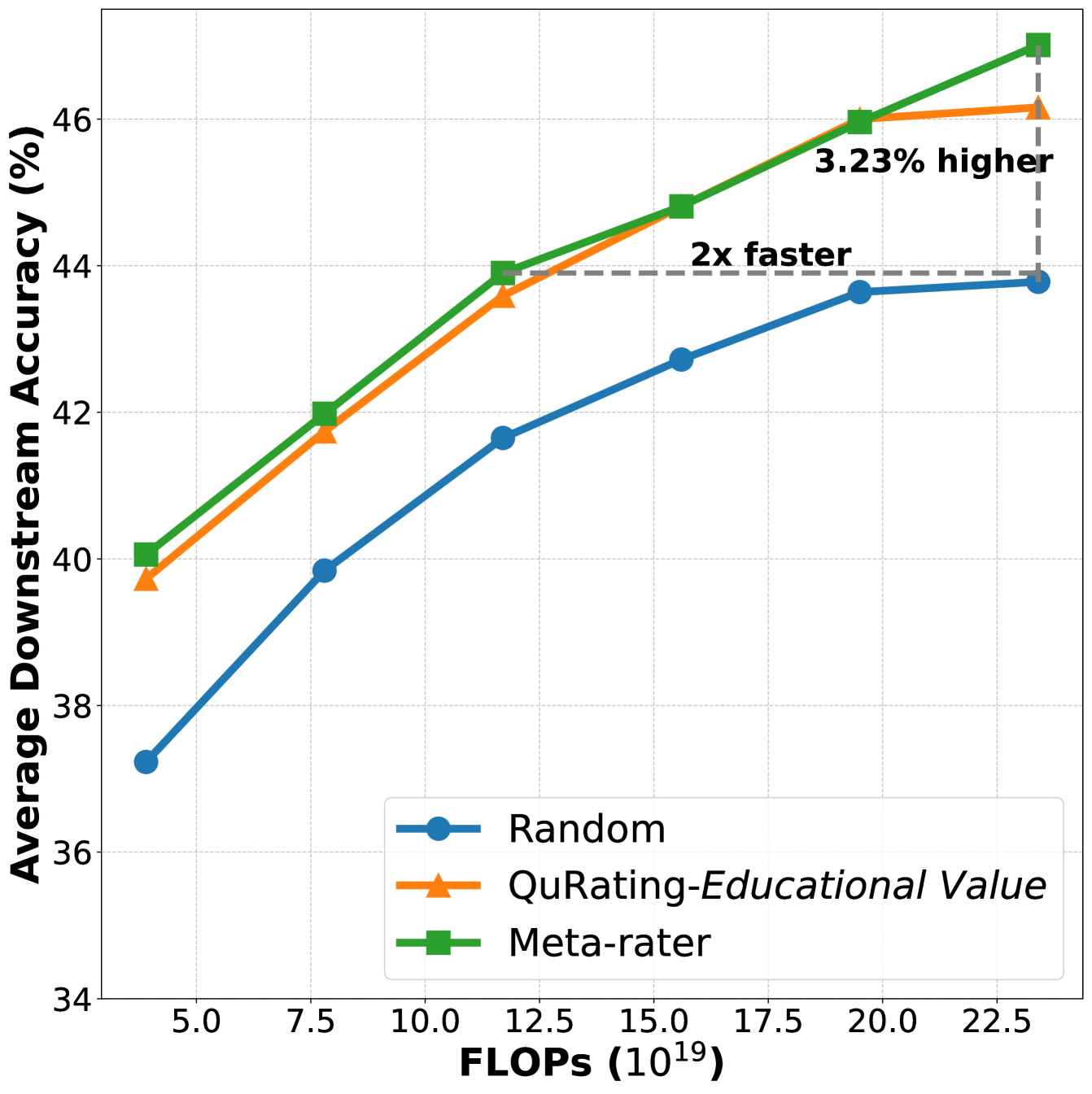
- 实验结果表明,Meta-rater能显著提升预训练效率和下游任务性能,尤其在大规模模型上优势更为明显。
📝 摘要(中文)
大型语言模型(LLM)的预训练数据集构成通常是不公开的,这阻碍了透明度以及优化数据质量的努力,而数据质量是模型性能的关键驱动因素。当前的数据选择方法,如自然语言质量评估、基于多样性的过滤器和基于分类器的方法,都受到单维度评估或以冗余为中心的策略的限制。为了解决这些差距,我们提出了四个维度来评估数据质量:专业性、可读性、推理能力和清洁度。我们进一步引入了Meta-rater,这是一种多维度数据选择方法,它通过学习到的最优权重将这些维度与现有的质量指标相结合。Meta-rater采用代理模型来训练一个回归模型,该模型预测验证损失,从而能够识别质量分数的最佳组合。实验表明,Meta-rater使13亿参数模型的收敛速度提高了一倍,并将下游任务性能提高了3.23,其优势可扩展到72亿参数的模型。我们的工作表明,整体的、多维度的质量整合明显优于传统的单维度方法,为提高预训练效率和模型能力提供了一种可扩展的范例。为了推进未来的研究,我们在https://github.com/opendatalab/Meta-rater上发布了脚本、数据和模型。
🔬 方法详解
问题定义:现有预训练数据选择方法主要存在两个痛点:一是评估维度单一,无法全面衡量数据质量;二是侧重于去除冗余,忽略了数据本身蕴含的知识和价值。这导致预训练效率低下,模型性能提升受限。
核心思路:Meta-rater的核心思路是构建一个多维度的质量评估体系,并学习不同维度之间的最优权重。通过综合考虑数据的专业性、可读性、推理能力和清洁度,更准确地评估数据对模型训练的贡献,从而选择更有价值的数据进行预训练。
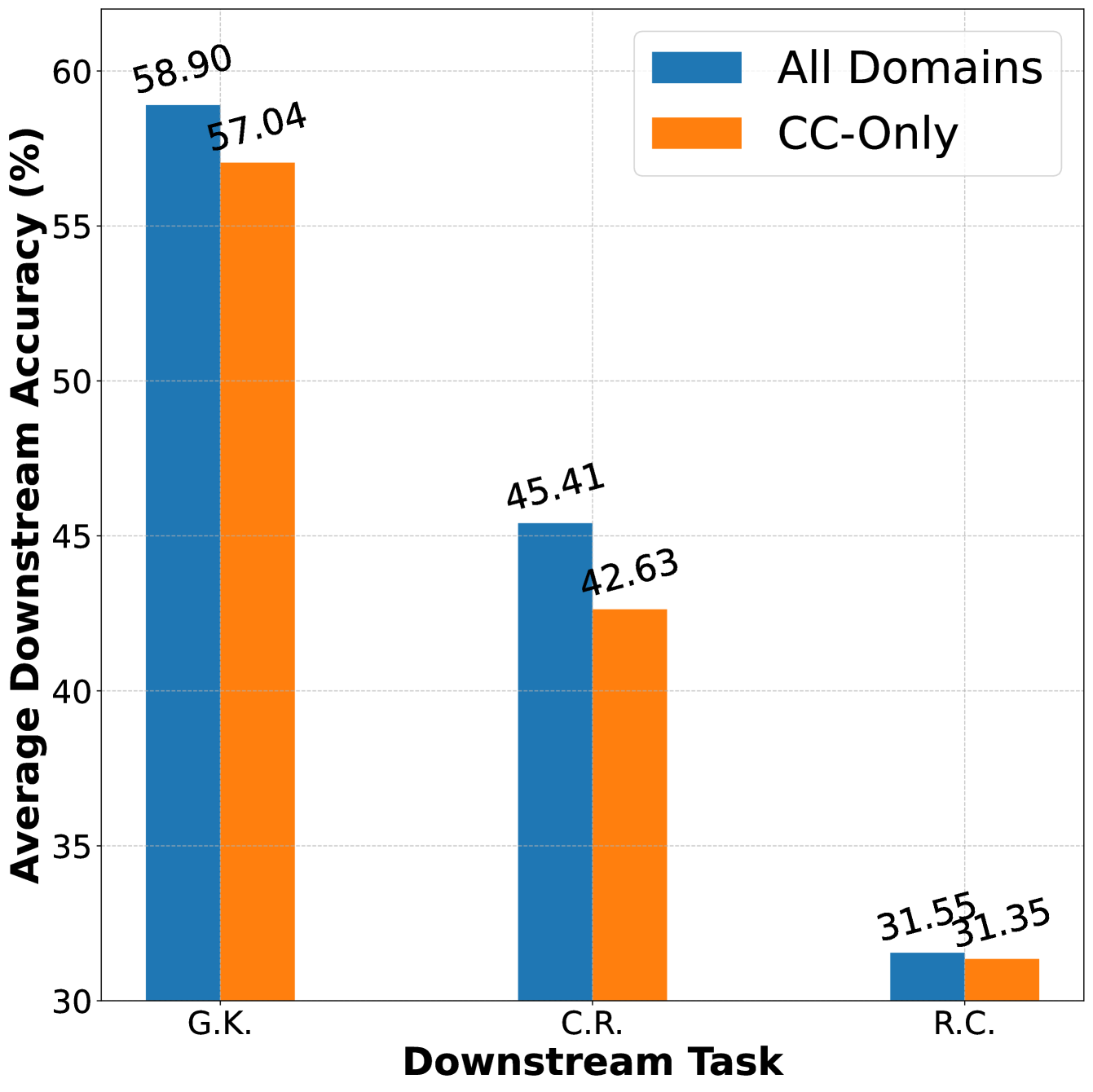
技术框架:Meta-rater主要包含以下几个阶段:1) 质量维度定义:确定专业性、可读性、推理能力和清洁度四个维度。2) 质量评估:使用现有的质量评估指标或模型对每个数据样本在各个维度上进行评分。3) 权重学习:使用代理模型训练一个回归模型,该模型以质量评分为输入,预测验证损失。通过优化权重,使得预测的验证损失与实际验证损失尽可能接近。4) 数据选择:根据学习到的权重,对数据样本进行排序,选择质量最高的数据进行预训练。
关键创新:Meta-rater的关键创新在于提出了一个多维度的质量评估体系,并使用代理模型学习不同维度之间的最优权重。与传统的单维度评估方法相比,Meta-rater能够更全面、更准确地评估数据质量,从而选择更有价值的数据进行预训练。
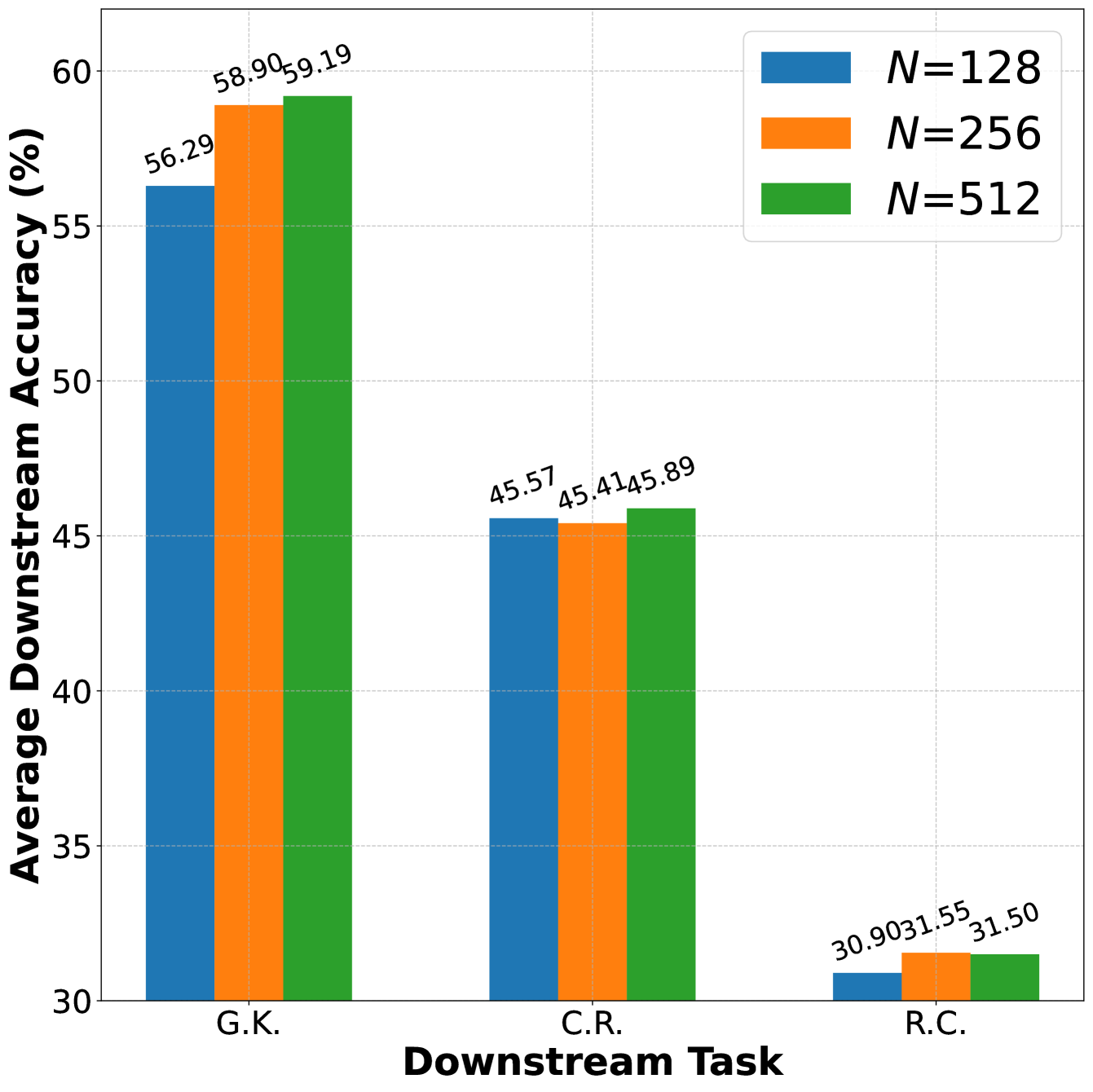
关键设计:在权重学习阶段,Meta-rater使用代理模型来预测验证损失。代理模型可以是任何回归模型,例如线性回归、神经网络等。损失函数通常选择均方误差(MSE),目标是最小化预测验证损失与实际验证损失之间的差异。此外,数据选择的比例也是一个重要的超参数,需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Meta-rater在13亿参数模型上使收敛速度提高了一倍,并在下游任务性能上提升了3.23。更重要的是,Meta-rater的优势可以扩展到72亿参数的模型,证明了其在大规模模型上的有效性。这些结果表明,多维度质量整合明显优于传统的单维度方法。
🎯 应用场景
Meta-rater可应用于各种规模的语言模型预训练,尤其适用于数据资源有限或计算资源受限的场景。通过选择高质量的数据进行预训练,可以显著提高模型性能,降低训练成本。该方法还可推广到其他机器学习任务,例如图像分类、目标检测等,通过选择高质量的训练数据来提升模型性能。
📄 摘要(原文)
The composition of pre-training datasets for large language models (LLMs) remains largely undisclosed, hindering transparency and efforts to optimize data quality, a critical driver of model performance. Current data selection methods, such as natural language quality assessments, diversity-based filters, and classifier-based approaches, are limited by single-dimensional evaluation or redundancy-focused strategies. To address these gaps, we propose four dimensions to evaluate data quality: professionalism, readability, reasoning, and cleanliness. We further introduce Meta-rater,a multi-dimensional data selection method that integrates these dimensions with existing quality metrics through learned optimal weightings. Meta-rater employs proxy models to train a regression model that predicts validation loss, enabling the identification of optimal combinations of quality scores. Experiments demonstrate that Meta-rater doubles convergence speed for 1.3B parameter models and improves downstream task performance by 3.23, with advantages that scale to models as large as 7.2B parameters. Our work establishes that holistic, multi-dimensional quality integration significantly outperforms conventional single-dimension approaches, offering a scalable paradigm for enhancing pre-training efficiency and model capability. To advance future research, we release scripts, data, and models at https://github.com/opendatalab/Meta-rater.