Retrieval-Augmented Generation with Conflicting Evidence
作者: Han Wang, Archiki Prasad, Elias Stengel-Eskin, Mohit Bansal
分类: cs.CL, cs.AI
发布日期: 2025-04-17 (更新: 2025-08-12)
备注: COLM 2025, Data and Code: https://github.com/HanNight/RAMDocs
💡 一句话要点
提出MADAM-RAG,解决检索增强生成中冲突证据带来的歧义、噪声和错误信息问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 多智能体系统 冲突证据 信息过滤 自然语言处理
📋 核心要点
- 现有RAG方法在处理复杂场景时,无法同时有效应对用户查询的歧义性、文档噪声和错误信息。
- MADAM-RAG采用多智能体辩论机制,通过多轮讨论消除歧义,过滤噪声和错误信息,提升回答质量。
- 实验表明,MADAM-RAG在处理冲突证据时,显著优于传统RAG基线,尤其是在抑制错误信息方面。
📝 摘要(中文)
大型语言模型(LLM)越来越多地采用检索增强生成(RAG)来提高其回答的真实性。然而,在实践中,这些系统经常需要处理模糊的用户查询和来自多个来源的潜在冲突信息,同时抑制来自嘈杂或不相关文档的不准确信息。以往的研究通常孤立地研究和解决这些挑战,一次只考虑一个方面,例如处理歧义或对噪声和错误信息的鲁棒性。我们同时考虑多个因素,提出(i)RAMDocs(文档中存在歧义和错误信息的检索),这是一个新的数据集,模拟了用户查询的冲突证据的复杂和真实场景,包括歧义、错误信息和噪声;以及(ii)MADAM-RAG,一种多智能体方法,其中LLM智能体就答案的优点进行多轮辩论,允许聚合器整理对应于消除歧义的实体的响应,同时丢弃错误信息和噪声,从而共同处理各种冲突来源。我们通过在AmbigDocs(需要呈现模糊查询的所有有效答案)上使用封闭和开源模型证明了MADAM-RAG的有效性,相对于强大的RAG基线提高了高达11.40%,并且在FaithEval(需要抑制错误信息)上,使用Llama3.3-70B-Instruct提高了高达15.80%(绝对值)。此外,我们发现RAMDocs对现有的RAG基线提出了挑战(Llama3.3-70B-Instruct仅获得32.60的精确匹配分数)。虽然MADAM-RAG开始解决这些冲突因素,但我们的分析表明,仍然存在很大的差距,尤其是在增加支持证据和错误信息的不平衡程度时。
🔬 方法详解
问题定义:论文旨在解决检索增强生成(RAG)在处理包含歧义、噪声和错误信息的文档时表现不佳的问题。现有的RAG方法通常孤立地处理这些问题,无法有效应对真实场景中多种因素同时存在的情况,导致生成答案的准确性和可靠性降低。
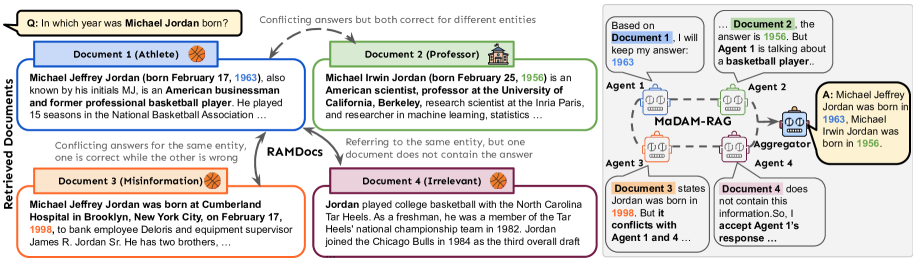
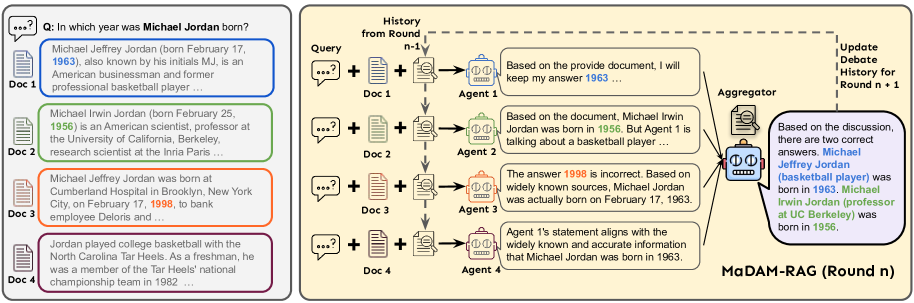
核心思路:论文的核心思路是引入多智能体辩论机制,让多个LLM智能体针对检索到的文档进行多轮辩论,从而消除歧义、过滤噪声和错误信息。通过智能体之间的相互质疑和验证,最终聚合出高质量的答案。这种方法模拟了人类专家团队协作解决问题的过程,能够更有效地处理复杂和冲突的信息。
技术框架:MADAM-RAG包含以下主要模块:1) 检索模块:从文档库中检索相关文档。2) 多智能体辩论模块:多个LLM智能体针对检索到的文档进行多轮辩论,每个智能体提出自己的观点和证据,并质疑其他智能体的观点。3) 聚合模块:根据智能体辩论的结果,聚合器选择最可靠的答案,并生成最终的回答。整个流程旨在通过多智能体的协作,提高RAG系统处理冲突证据的能力。
关键创新:MADAM-RAG的关键创新在于引入了多智能体辩论机制,将RAG系统从单智能体模式扩展到多智能体协作模式。这种模式能够更有效地处理复杂和冲突的信息,提高生成答案的准确性和可靠性。此外,论文还提出了一个新的数据集RAMDocs,用于评估RAG系统在处理歧义、噪声和错误信息方面的能力。
关键设计:在多智能体辩论模块中,每个智能体都配备了不同的角色和目标,例如支持者、反对者和中立者。智能体之间的辩论过程采用迭代的方式进行,每一轮辩论都基于上一轮的结果进行。聚合模块使用加权投票机制,根据智能体的可信度和辩论的表现,对不同的答案进行加权,最终选择得分最高的答案。
🖼️ 关键图片
📊 实验亮点
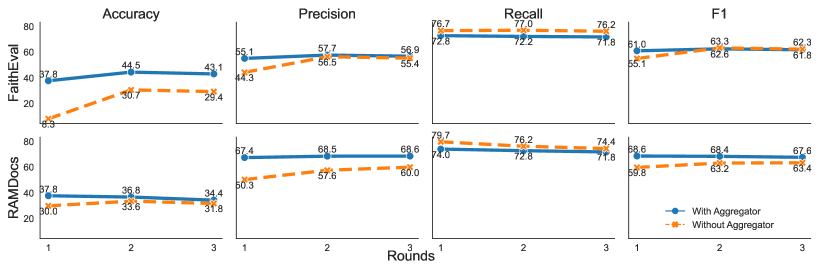
实验结果表明,MADAM-RAG在AmbigDocs数据集上,相对于强大的RAG基线提高了高达11.40%,在FaithEval数据集上,使用Llama3.3-70B-Instruct提高了高达15.80%(绝对值)。此外,RAMDocs数据集对现有RAG基线提出了挑战,Llama3.3-70B-Instruct仅获得32.60的精确匹配分数,表明MADAM-RAG在处理冲突证据方面具有显著优势。
🎯 应用场景
MADAM-RAG可应用于需要处理大量信息并从中提取准确信息的各种场景,例如智能客服、金融分析、医疗诊断等。该方法能够提高信息检索的准确性和可靠性,减少错误信息的传播,为用户提供更可靠的决策支持。未来,该方法有望应用于更广泛的领域,例如新闻报道、学术研究等。
📄 摘要(原文)
Large language model (LLM) agents are increasingly employing retrieval-augmented generation (RAG) to improve the factuality of their responses. However, in practice, these systems often need to handle ambiguous user queries and potentially conflicting information from multiple sources while also suppressing inaccurate information from noisy or irrelevant documents. Prior work has generally studied and addressed these challenges in isolation, considering only one aspect at a time, such as handling ambiguity or robustness to noise and misinformation. We instead consider multiple factors simultaneously, proposing (i) RAMDocs (Retrieval with Ambiguity and Misinformation in Documents), a new dataset that simulates complex and realistic scenarios for conflicting evidence for a user query, including ambiguity, misinformation, and noise; and (ii) MADAM-RAG, a multi-agent approach in which LLM agents debate over the merits of an answer over multiple rounds, allowing an aggregator to collate responses corresponding to disambiguated entities while discarding misinformation and noise, thereby handling diverse sources of conflict jointly. We demonstrate the effectiveness of MADAM-RAG using both closed and open-source models on AmbigDocs -- which requires presenting all valid answers for ambiguous queries -- improving over strong RAG baselines by up to 11.40% and on FaithEval -- which requires suppressing misinformation -- where we improve by up to 15.80% (absolute) with Llama3.3-70B-Instruct. Furthermore, we find that RAMDocs poses a challenge for existing RAG baselines (Llama3.3-70B-Instruct only obtains 32.60 exact match score). While MADAM-RAG begins to address these conflicting factors, our analysis indicates that a substantial gap remains especially when increasing the level of imbalance in supporting evidence and misinformation.