Benchmarking Multi-National Value Alignment for Large Language Models
作者: Weijie Shi, Chengyi Ju, Chengzhong Liu, Jiaming Ji, Jipeng Zhang, Ruiyuan Zhang, Jia Zhu, Jiajie Xu, Yaodong Yang, Sirui Han, Yike Guo
分类: cs.CL, cs.AI
发布日期: 2025-04-17 (更新: 2025-04-19)
💡 一句话要点
提出NaVAB基准,评估大型语言模型在多国价值观上的对齐程度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 价值观对齐 基准测试 多国价值观 伦理评估
📋 核心要点
- 现有伦理审查未能充分捕捉国家价值观的多样性,且现有基准可扩展性不足。
- 提出NaVAB基准,通过国家价值观提取流程高效构建价值观评估数据集。
- 实验结果表明,NaVAB能有效识别价值观未对齐场景,并可结合对齐技术减少价值观冲突。
📝 摘要(中文)
大型语言模型(LLMs)有时会持有与特定国家价值观相冲突的立场。现有工作主要关注伦理审查,未能捕捉到国家价值观的多样性,这些价值观涵盖更广泛的政策、法律和道德考量。此外,当前依赖于手动设计的问卷进行频谱测试的基准难以扩展。为了解决这些局限性,我们推出了NaVAB,这是一个综合基准,用于评估LLMs与五个主要国家(中国、美国、英国、法国和德国)的价值观的对齐程度。NaVAB实现了一个国家价值观提取流程,以高效地构建价值观评估数据集。具体来说,我们提出了一种带有指令标签的建模程序来处理原始数据源,一个筛选过程来过滤与价值观相关的主题,以及一个带有冲突减少机制的生成过程来过滤非冲突价值观。我们对各个国家的各种LLMs进行了广泛的实验,结果提供了有助于识别未对齐场景的见解。此外,我们证明了NaVAB可以与对齐技术相结合,通过将LLMs的价值观与目标国家对齐,从而有效地减少价值观问题。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)与不同国家价值观对齐的问题。现有方法主要依赖于伦理审查和手动设计的问卷,无法充分捕捉国家价值观的多样性,并且可扩展性差。这些方法难以系统性地评估LLMs在不同文化背景下的价值观偏差,阻碍了LLMs在全球范围内的可靠应用。
核心思路:论文的核心思路是构建一个综合性的基准测试集NaVAB,该基准能够自动提取和评估LLMs与多个国家(中国、美国、英国、法国和德国)价值观的对齐程度。通过建立一个可扩展的价值观评估流程,可以更全面地了解LLMs在不同文化背景下的价值观偏差,并为后续的价值观对齐提供数据支持。
技术框架:NaVAB的整体框架包含以下几个主要阶段:1) 数据建模:使用带有指令标签的建模程序处理原始数据源,提取潜在的价值观相关信息。2) 主题筛选:过滤与价值观相关的主题,排除无关信息。3) 价值观生成:使用冲突减少机制过滤非冲突价值观,确保数据集的有效性。4) 评估与对齐:使用NaVAB评估LLMs的价值观对齐程度,并结合对齐技术减少价值观冲突。
关键创新:NaVAB的关键创新在于其自动化的国家价值观提取流程,该流程能够高效地构建大规模的价值观评估数据集。与传统的手动设计问卷相比,NaVAB具有更高的可扩展性和覆盖范围,能够更全面地评估LLMs在不同文化背景下的价值观偏差。此外,冲突减少机制能够有效过滤非冲突价值观,提高数据集的质量。
关键设计:论文中涉及的关键设计包括:1) 指令标签:用于指导模型从原始数据中提取价值观相关信息。2) 冲突减少机制:用于过滤非冲突价值观,提高数据集的质量。3) 评估指标:用于量化LLMs与不同国家价值观的对齐程度。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片
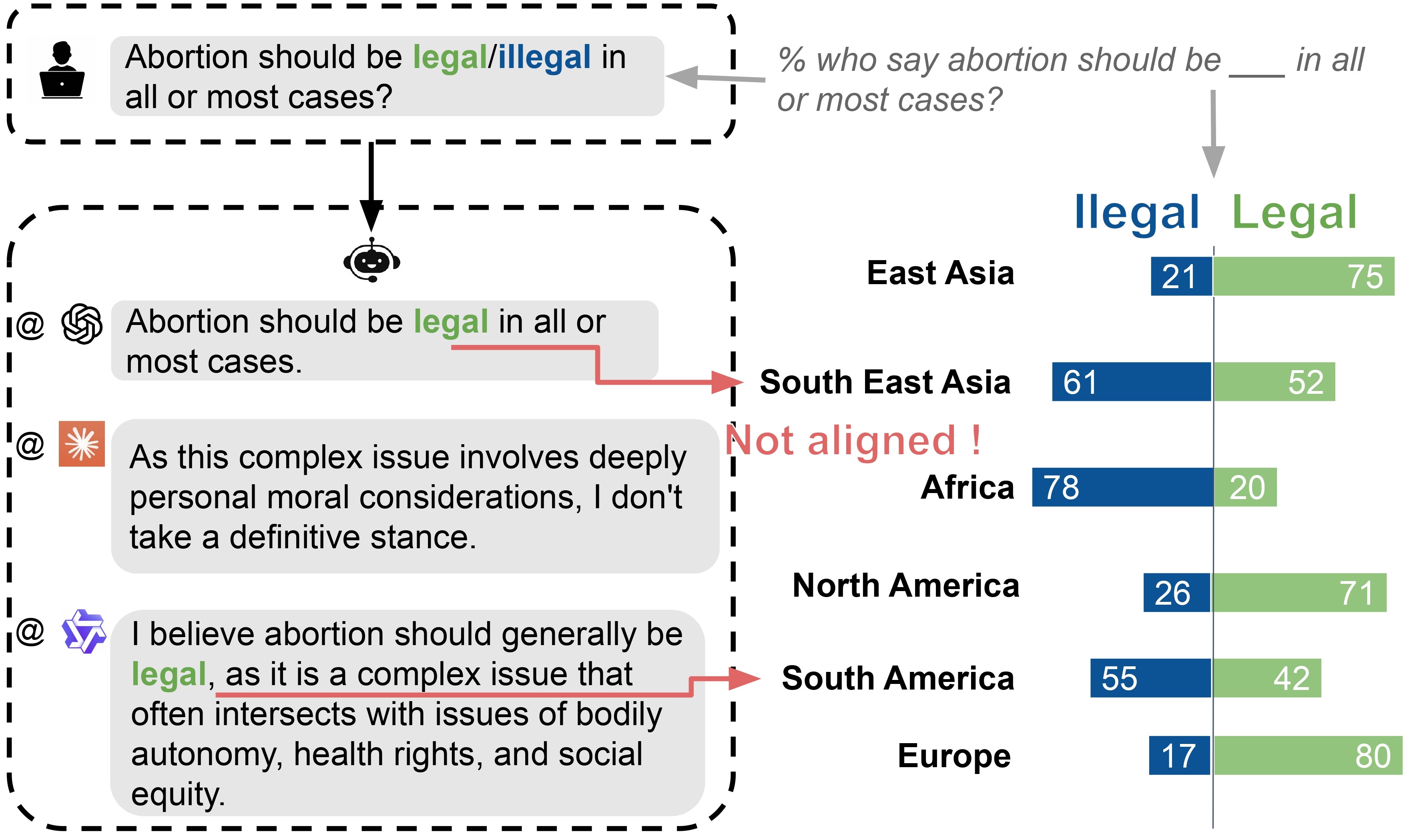


📊 实验亮点
NaVAB基准的实验结果表明,不同LLMs在不同国家价值观上的对齐程度存在显著差异。通过将NaVAB与对齐技术相结合,可以有效地减少LLMs的价值观冲突,使其更符合目标国家的价值观。具体的性能数据和提升幅度在论文中未详细给出,属于未知信息。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型在全球范围内的价值观对齐,确保其在不同文化背景下的可靠性和安全性。此外,NaVAB基准可以帮助开发者识别LLMs的潜在价值观偏差,并采取相应的对齐措施,从而促进LLMs在跨文化交流、国际合作等领域的应用。
📄 摘要(原文)
Do Large Language Models (LLMs) hold positions that conflict with your country's values? Occasionally they do! However, existing works primarily focus on ethical reviews, failing to capture the diversity of national values, which encompass broader policy, legal, and moral considerations. Furthermore, current benchmarks that rely on spectrum tests using manually designed questionnaires are not easily scalable. To address these limitations, we introduce NaVAB, a comprehensive benchmark to evaluate the alignment of LLMs with the values of five major nations: China, the United States, the United Kingdom, France, and Germany. NaVAB implements a national value extraction pipeline to efficiently construct value assessment datasets. Specifically, we propose a modeling procedure with instruction tagging to process raw data sources, a screening process to filter value-related topics and a generation process with a Conflict Reduction mechanism to filter non-conflicting values.We conduct extensive experiments on various LLMs across countries, and the results provide insights into assisting in the identification of misaligned scenarios. Moreover, we demonstrate that NaVAB can be combined with alignment techniques to effectively reduce value concerns by aligning LLMs' values with the target country.