Persona-judge: Personalized Alignment of Large Language Models via Token-level Self-judgment
作者: Xiaotian Zhang, Ruizhe Chen, Yang Feng, Zuozhu Liu
分类: cs.CL, cs.AI
发布日期: 2025-04-17 (更新: 2025-06-11)
备注: ACL Finding
💡 一句话要点
提出Persona-judge,通过token级自判别实现大语言模型的个性化对齐。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化对齐 大语言模型 自判别 token级 偏好学习
📋 核心要点
- 现有语言模型对齐方法依赖额外标注数据和奖励信号,成本高昂且难以适应多样化的人类价值观。
- Persona-judge利用模型自身固有的偏好判断能力,通过草稿模型和评判模型的交叉验证实现个性化对齐。
- 实验表明,Persona-judge无需额外训练即可实现个性化对齐,是一种可扩展且计算高效的解决方案。
📝 摘要(中文)
将语言模型与人类偏好对齐面临巨大挑战,尤其是在实现个性化时,计算成本过高。现有方法依赖奖励信号和额外标注数据,限制了其可扩展性和对不同人类价值观的适应性。为了解决这些挑战,我们提出Persona-judge,一种新颖的判别范式,无需训练即可实现对未见偏好的个性化对齐。Persona-judge不通过外部奖励反馈优化策略参数,而是利用模型固有的偏好判断能力。具体而言,草稿模型根据给定的偏好生成候选token,而评判模型则体现另一种偏好,交叉验证预测的token是否被接受。实验结果表明,Persona-judge利用模型固有的偏好评估机制,为个性化对齐提供了一种可扩展且计算高效的解决方案,为更具适应性的定制对齐铺平了道路。
🔬 方法详解
问题定义:现有的大语言模型对齐方法,尤其是个性化对齐,需要大量的标注数据和复杂的奖励模型训练,计算成本高昂,并且难以泛化到未见过的用户偏好。这些方法通常依赖于外部的奖励信号,无法充分利用模型自身所蕴含的知识和偏好判断能力。
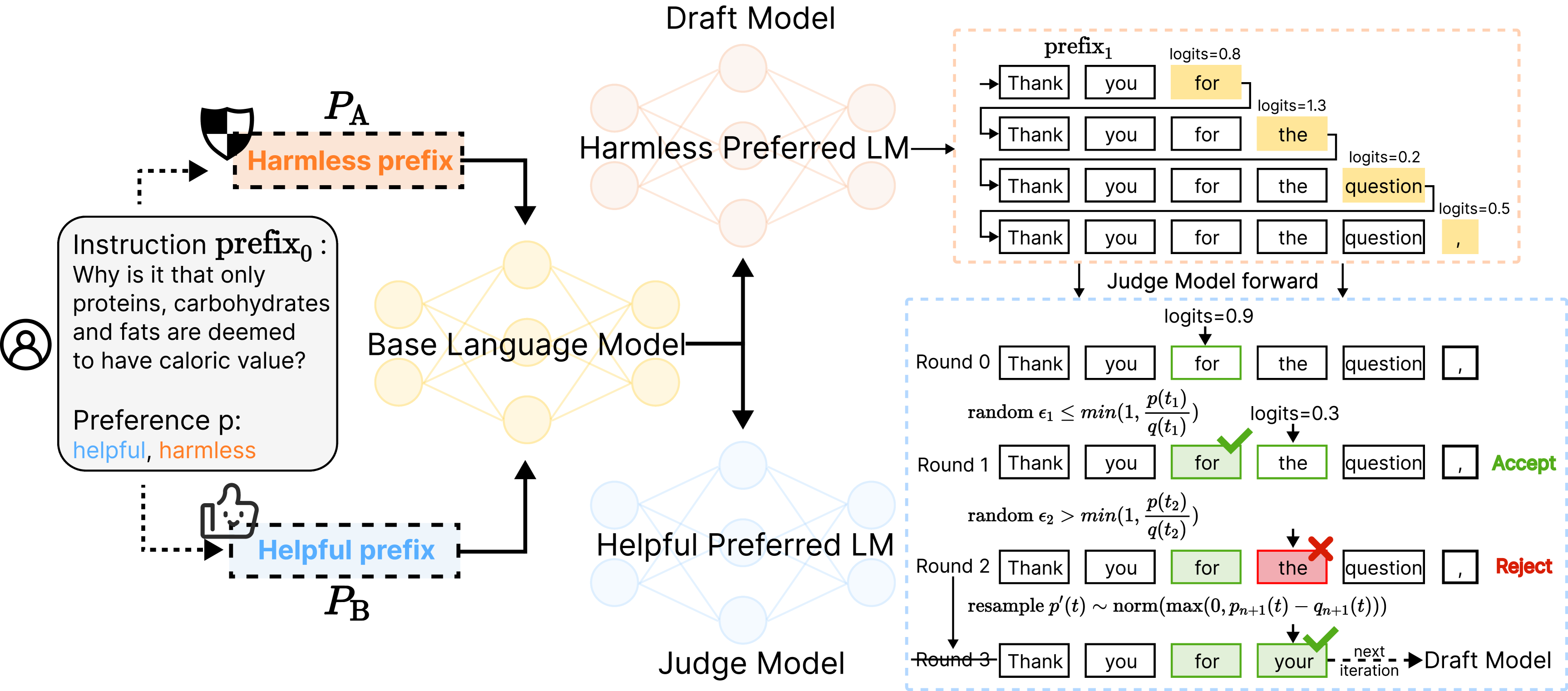
核心思路:Persona-judge的核心在于利用大语言模型自身的能力进行偏好判断,避免了对外部奖励信号的依赖。其基本思想是,一个模型(草稿模型)根据给定的偏好生成候选的token,另一个模型(评判模型)则根据另一种偏好来判断该token是否可以接受。通过这种自判别的方式,实现个性化的对齐。
技术框架:Persona-judge包含两个主要模块:草稿模型和评判模型。草稿模型负责根据给定的用户偏好生成候选的token序列。评判模型则模拟另一种用户偏好,对草稿模型生成的token进行评估,判断其是否符合该偏好。整个过程类似于一个生成对抗网络,但不同之处在于,Persona-judge不需要进行显式的训练,而是直接利用预训练模型的知识和偏好。
关键创新:Persona-judge最重要的创新在于其训练自由的个性化对齐方法。它避免了对额外标注数据和奖励模型的依赖,而是通过模型自身的偏好判断能力来实现个性化。这种方法不仅降低了计算成本,还提高了模型对未见偏好的泛化能力。
关键设计:Persona-judge的关键设计在于草稿模型和评判模型的选择以及token接受的策略。草稿模型和评判模型可以是同一个模型,也可以是不同的模型。token接受的策略可以基于评判模型的输出概率,例如,只有当评判模型认为该token符合其偏好的概率高于某个阈值时,该token才会被接受。
🖼️ 关键图片

📊 实验亮点
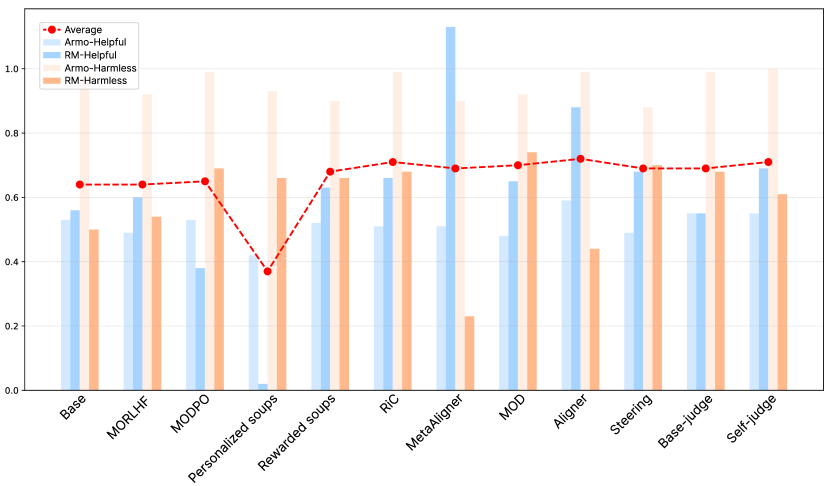
Persona-judge通过token级自判别实现了个性化对齐,无需额外训练。实验结果表明,该方法在未见偏好上的泛化能力优于现有方法,并且计算效率更高。具体的性能数据和对比基线需要在论文中查找。
🎯 应用场景
Persona-judge具有广泛的应用前景,例如个性化推荐系统、定制化对话机器人、以及能够根据用户价值观生成内容的人工智能助手。该方法能够显著降低个性化对齐的成本,并提高模型对用户偏好的适应性,从而实现更加智能和人性化的AI应用。
📄 摘要(原文)
Aligning language models with human preferences presents significant challenges, particularly in achieving personalization without incurring excessive computational costs. Existing methods rely on reward signals and additional annotated data, limiting their scalability and adaptability to diverse human values. To address these challenges, we introduce Persona-judge, a novel discriminative paradigm that enables training-free personalized alignment with unseen preferences. Instead of optimizing policy parameters through external reward feedback, Persona-judge leverages the intrinsic preference judgment capabilities of the model. Specifically, a draft model generates candidate tokens conditioned on a given preference, while a judge model, embodying another preference, cross-validates the predicted tokens whether to be accepted. Experimental results demonstrate that Persona-judge, using the inherent preference evaluation mechanisms of the model, offers a scalable and computationally efficient solution to personalized alignment, paving the way for more adaptive customized alignment. Our code is available here.