GeoSense: Evaluating Identification and Application of Geometric Principles in Multimodal Reasoning
作者: Liangyu Xu, Yingxiu Zhao, Jingyun Wang, Yingyao Wang, Bu Pi, Chen Wang, Mingliang Zhang, Jihao Gu, Xiang Li, Xiaoyong Zhu, Jun Song, Bo Zheng
分类: cs.CL
发布日期: 2025-04-17 (更新: 2025-04-24)
备注: 10 pages, 8 figures
💡 一句话要点
GeoSense:提出用于评估多模态LLM几何推理能力的新基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 几何推理 多模态学习 大型语言模型 基准测试 视觉理解
📋 核心要点
- 现有几何问题求解基准未能充分评估多模态LLM在几何原理识别和应用方面的综合能力。
- GeoSense通过构建分层几何原理框架和精细标注的数据集,系统评估MLLM的几何推理能力。
- 实验表明,即使是最先进的MLLM在几何原理的识别和应用方面仍存在瓶颈,影响整体推理性能。
📝 摘要(中文)
几何问题求解(GPS)是一项具有挑战性的任务,它需要视觉理解和符号推理能力,能够有效地衡量多模态大型语言模型(MLLM)的推理能力。人类通过准确识别和自适应地应用视觉环境中的几何原理,在该任务中表现出强大的推理能力。然而,现有的基准测试未能共同评估MLLM类人几何推理机制的这两个维度,这仍然是评估其解决GPS能力的关键差距。为此,我们推出了GeoSense,这是第一个全面的双语基准,旨在通过几何原理的视角系统地评估MLLM的几何推理能力。GeoSense具有一个涵盖平面和立体几何的五级分层几何原理框架、一个精心注释的包含1,789个问题的数据集以及一种创新的评估策略。通过对各种开源和闭源MLLM在GeoSense上进行的大量实验,我们观察到Gemini-2.0-pro-flash表现最佳,总体得分为65.3。我们的深入分析表明,几何原理的识别和应用仍然是领先MLLM的瓶颈,共同阻碍了它们的推理能力。这些发现强调了GeoSense在指导未来MLLM几何推理能力发展方面的潜力,为人工智能中更强大、更类人的推理铺平了道路。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)在几何问题求解(GPS)中,对几何原理的识别和应用能力不足的问题。现有基准测试通常只关注最终的求解结果,而忽略了对模型理解和运用几何知识的细粒度评估,无法有效诊断模型推理能力的瓶颈。
核心思路:论文的核心思路是构建一个更全面的基准测试,不仅评估MLLM的解题准确率,更重要的是评估其对几何原理的识别和应用能力。通过细粒度的标注和评估,可以更深入地了解MLLM在几何推理方面的优势和不足,从而指导未来的模型改进。
技术框架:GeoSense基准测试包含以下几个主要组成部分:1) 五级分层几何原理框架,涵盖平面和立体几何的各种原理;2) 精心标注的数据集,包含1789个几何问题,每个问题都标注了相关的几何原理;3) 创新的评估策略,不仅评估解题准确率,还评估模型对几何原理的识别和应用能力。
关键创新:GeoSense的关键创新在于其对几何推理能力的细粒度评估。与以往的基准测试不同,GeoSense不仅关注最终的解题结果,更关注模型在解题过程中对几何原理的理解和运用。这种细粒度的评估可以更准确地反映模型的推理能力,并为模型改进提供更有效的指导。
关键设计:GeoSense的数据集包含多种类型的几何问题,涵盖平面和立体几何的各个方面。每个问题都经过精心标注,标注信息包括问题类型、几何图形、已知条件、求解目标以及相关的几何原理。评估策略包括多个指标,用于评估模型在解题准确率、几何原理识别准确率和几何原理应用准确率等方面的表现。
🖼️ 关键图片
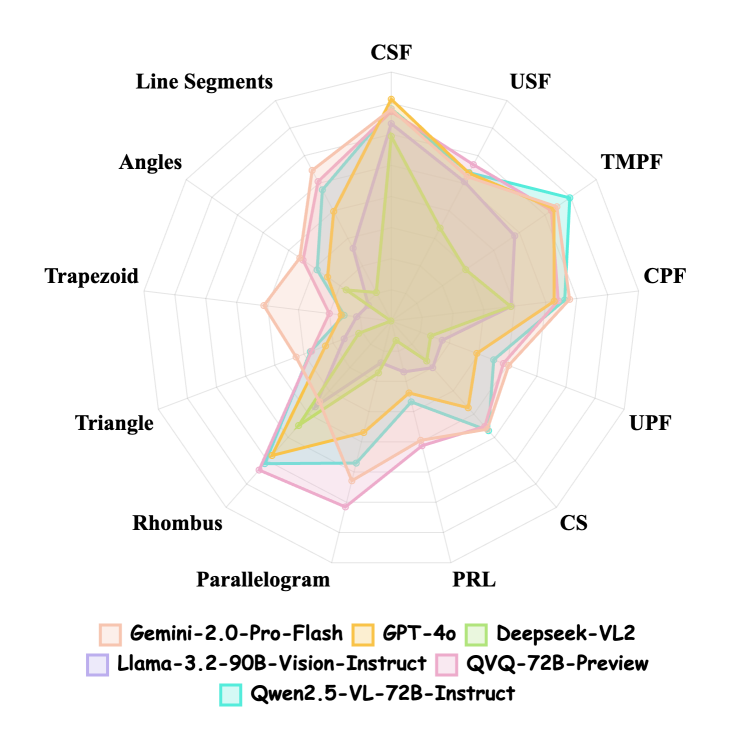


📊 实验亮点
实验结果表明,Gemini-2.0-pro-flash在GeoSense基准测试中取得了最佳性能,总体得分为65.3。然而,深入分析表明,即使是最先进的MLLM在几何原理的识别和应用方面仍然存在显著的不足,这严重影响了它们的整体推理能力。这表明GeoSense能够有效揭示现有MLLM在几何推理方面的瓶颈。
🎯 应用场景
GeoSense的研究成果可应用于提升多模态大型语言模型在几何、物理等领域的推理能力。通过更准确地评估和诊断模型的推理瓶颈,可以指导模型设计和训练,使其在需要视觉理解和符号推理的实际场景中表现更佳,例如机器人导航、自动驾驶、智能设计等。
📄 摘要(原文)
Geometry problem-solving (GPS), a challenging task requiring both visual comprehension and symbolic reasoning, effectively measures the reasoning capabilities of multimodal large language models (MLLMs). Humans exhibit strong reasoning ability in this task through accurate identification and adaptive application of geometric principles within visual contexts. However, existing benchmarks fail to jointly assess both dimensions of the human-like geometric reasoning mechanism in MLLMs, remaining a critical gap in assessing their ability to tackle GPS. To this end, we introduce GeoSense, the first comprehensive bilingual benchmark designed to systematically evaluate the geometric reasoning abilities of MLLMs through the lens of geometric principles. GeoSense features a five-level hierarchical framework of geometric principles spanning plane and solid geometry, an intricately annotated dataset of 1,789 problems, and an innovative evaluation strategy. Through extensive experiments on GeoSense with various open-source and closed-source MLLMs, we observe that Gemini-2.0-pro-flash performs best, achieving an overall score of $65.3$. Our in-depth analysis reveals that the identification and application of geometric principles remain a bottleneck for leading MLLMs, jointly hindering their reasoning abilities. These findings underscore GeoSense's potential to guide future advancements in MLLMs' geometric reasoning capabilities, paving the way for more robust and human-like reasoning in artificial intelligence.