Memorization vs. Reasoning: Updating LLMs with New Knowledge
作者: Aochong Oliver Li, Tanya Goyal
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-04-16
备注: 9 pages, 3 figures
💡 一句话要点
提出KUP基准与MCT训练方法,提升LLM对新知识的记忆与推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识更新 持续学习 记忆条件训练 推理能力 KUP基准 自回归模型
📋 核心要点
- 现有LLM知识更新方法主要关注实体替换,无法全面应对复杂现实世界的知识动态变化。
- 论文提出记忆条件训练(MCT)方法,通过在训练时将更新语料库的token以自生成的“记忆”token为条件,提升LLM的推理能力。
- 实验表明,MCT在KUP基准测试中显著优于持续预训练(CPT)基线,直接探测(记忆)结果提升高达25.4%。
📝 摘要(中文)
大型语言模型(LLM)在其参数中编码了大量的预训练知识,但随着现实世界信息的演变而更新它们仍然是一个挑战。现有的方法和基准主要针对实体替换,未能捕捉到复杂现实世界动态的全部广度。在本文中,我们介绍Knowledge Update Playground(KUP),这是一个自动管道,用于模拟反映在证据语料库中的真实知识更新。KUP的评估框架包括直接和间接探针,用于测试更新事实的记忆和基于它们的推理,适用于任何更新学习方法。接下来,我们提出了一种轻量级方法,称为记忆条件训练(MCT),该方法在训练期间将更新语料库中的token以自生成的“记忆”token为条件。我们的策略鼓励LLM在推理时呈现和推理新记忆的知识。我们在两个强大的LLM上的结果表明:(1)KUP基准极具挑战性,最佳CPT模型在间接探测设置(推理)中实现了<2%的准确率;(2)MCT训练显着优于先前的持续预训练(CPT)基线,将直接探测(记忆)结果提高了高达25.4%。
🔬 方法详解
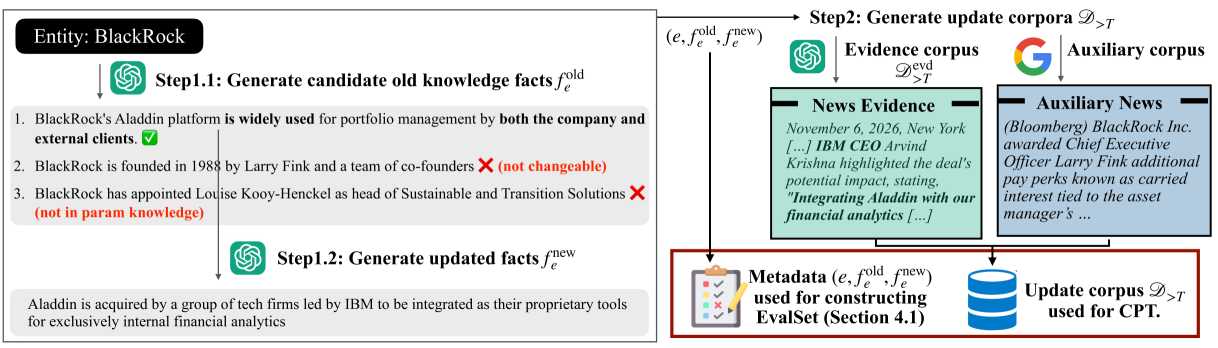
问题定义:现有大型语言模型(LLM)虽然存储了大量预训练知识,但难以有效更新并利用这些知识。现有知识更新方法和基准测试主要集中在简单的实体替换上,无法模拟现实世界中复杂且动态的知识变化,导致LLM在实际应用中无法及时适应新信息并进行有效推理。
核心思路:论文的核心思路是提出一种名为“记忆条件训练”(MCT)的轻量级训练方法,该方法通过在训练过程中显式地引入“记忆”token,引导LLM更好地记忆和推理新知识。MCT鼓励模型在推理时主动检索并利用这些记忆token,从而提高模型对更新知识的利用率。
技术框架:MCT训练方法主要包含以下几个步骤:1)构建知识更新语料库,包含更新后的事实和相关证据;2)在训练过程中,对于更新语料库中的每个token,模型首先生成相应的“记忆”token;3)然后,模型以这些自生成的“记忆”token为条件,预测下一个token。这种条件训练方式鼓励模型学习将新知识与记忆token关联起来。
关键创新:MCT的关键创新在于引入了“记忆”token的概念,并将其作为训练过程中的显式条件。与传统的持续预训练(CPT)方法相比,MCT能够更有效地引导模型关注和利用新知识,从而提高模型的记忆和推理能力。
关键设计:MCT的关键设计包括:1)记忆token的生成方式:论文中使用了自回归的方式生成记忆token,即基于之前的token预测当前的记忆token;2)条件训练的方式:论文中使用了交叉熵损失函数,目标是最大化在给定记忆token的条件下,正确预测下一个token的概率;3)超参数的选择:论文中对记忆token的长度、训练轮数等超参数进行了调整,以获得最佳性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在KUP基准测试中,MCT训练方法显著优于传统的持续预训练(CPT)基线。具体而言,MCT在直接探测(记忆)任务中取得了高达25.4%的性能提升,表明MCT能够更有效地帮助LLM记忆新知识。此外,MCT在间接探测(推理)任务中也取得了显著的性能提升,证明了MCT不仅能够提高LLM的记忆能力,还能提升其基于新知识进行推理的能力。
🎯 应用场景
该研究成果可应用于各种需要持续学习和知识更新的LLM应用场景,例如智能客服、知识问答、新闻摘要等。通过提升LLM对新知识的记忆和推理能力,可以使其更好地适应快速变化的信息环境,提供更准确、更可靠的服务。该研究也为未来LLM的知识更新和终身学习提供了新的思路。
📄 摘要(原文)
Large language models (LLMs) encode vast amounts of pre-trained knowledge in their parameters, but updating them as real-world information evolves remains a challenge. Existing methodologies and benchmarks primarily target entity substitutions, failing to capture the full breadth of complex real-world dynamics. In this paper, we introduce Knowledge Update Playground (KUP), an automatic pipeline for simulating realistic knowledge updates reflected in an evidence corpora. KUP's evaluation framework includes direct and indirect probes to both test memorization of updated facts and reasoning over them, for any update learning methods. Next, we present a lightweight method called memory conditioned training (MCT), which conditions tokens in the update corpus on self-generated "memory" tokens during training. Our strategy encourages LLMs to surface and reason over newly memorized knowledge at inference. Our results on two strong LLMs show that (1) KUP benchmark is highly challenging, with the best CPT models achieving $<2\%$ in indirect probing setting (reasoning) and (2) MCT training significantly outperforms prior continued pre-training (CPT) baselines, improving direct probing (memorization) results by up to $25.4\%$.