Finding Flawed Fictions: Evaluating Complex Reasoning in Language Models via Plot Hole Detection
作者: Kabir Ahuja, Melanie Sclar, Yulia Tsvetkov
分类: cs.CL
发布日期: 2025-04-16 (更新: 2025-12-18)
备注: CoLM 2025 Camera Ready
💡 一句话要点
提出FlawedFictions基准,用于评估语言模型在故事情节漏洞检测中的复杂推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 情节漏洞检测 语言模型评估 复杂推理 叙事一致性 FlawedFictions基准
📋 核心要点
- 现有语言模型评估基准主要关注表面理解,缺乏对深层叙事一致性和复杂推理能力的有效评估。
- 提出FlawedFictionsMaker算法,用于在人类编写的故事中可控地合成情节漏洞,构建高质量的评估基准。
- 实验表明,即使是最先进的LLM在情节漏洞检测任务中表现不佳,且故事越长,性能下降越明显。
📝 摘要(中文)
故事是人类经验的基本组成部分。深入理解故事并发现情节漏洞——故事情节中打破故事内部逻辑或规则的不一致之处——需要细致的推理能力,包括跟踪实体和事件及其相互作用、抽象思维、务实的叙事理解、常识和社会推理以及心智理论。随着大型语言模型(LLM)越来越多地生成、解释和修改文本,严格评估其叙事一致性和更深层次的语言理解变得至关重要。然而,现有的基准主要侧重于表面层面的理解。在这项工作中,我们提出在故事中进行情节漏洞检测,以此来评估LLM中的语言理解和推理能力。我们引入了FlawedFictionsMaker,一种新颖的算法,用于可控且仔细地在人类编写的故事中合成情节漏洞。使用该算法,我们构建了一个基准来评估LLM在故事中检测情节漏洞的能力——FlawedFictions——它对污染具有鲁棒性,并通过人工过滤确保高质量。我们发现,最先进的LLM在准确解决FlawedFictions方面表现不佳,无论允许多少推理努力,并且随着故事长度的增加,性能显着下降。最后,我们表明,基于LLM的故事摘要和故事生成容易引入情节漏洞,相对于人类编写的原始故事,情节漏洞检测率分别提高了50%以上和100%以上。
🔬 方法详解
问题定义:论文旨在解决现有语言模型评估基准无法有效评估模型在复杂推理和叙事一致性方面的能力的问题。现有方法主要关注表面理解,忽略了对故事内部逻辑和规则的理解,以及对情节漏洞的检测能力。
核心思路:论文的核心思路是将情节漏洞检测作为评估语言模型复杂推理能力的代理任务。通过在故事中引入情节漏洞,并要求模型识别这些漏洞,可以有效地评估模型对故事内部逻辑、实体关系和事件发展的理解能力。这样设计的目的是为了更全面地评估语言模型的深层语言理解能力。
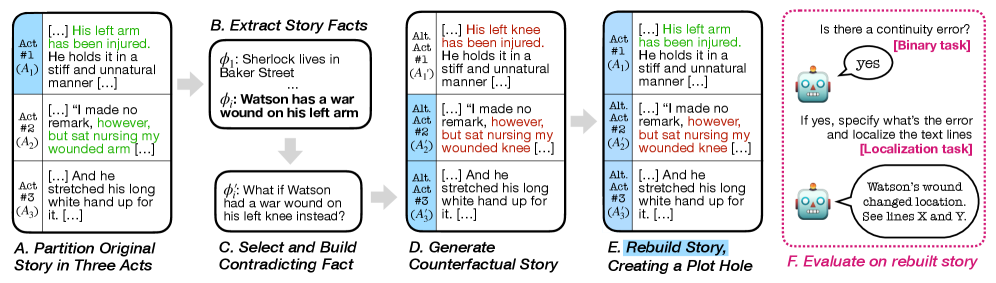
技术框架:论文的技术框架主要包括两个部分:FlawedFictionsMaker算法和FlawedFictions基准。FlawedFictionsMaker算法用于在人类编写的故事中可控地合成情节漏洞。FlawedFictions基准则用于评估LLM在故事中检测情节漏洞的能力。整个流程包括:1)收集人类编写的故事;2)使用FlawedFictionsMaker算法在故事中引入情节漏洞;3)人工过滤,确保故事质量;4)使用LLM进行情节漏洞检测;5)评估LLM的性能。
关键创新:论文最重要的技术创新点在于提出了FlawedFictionsMaker算法,该算法能够可控且仔细地在人类编写的故事中合成情节漏洞。与现有方法相比,该算法能够生成高质量、具有挑战性的情节漏洞,从而更有效地评估语言模型的推理能力。此外,构建的FlawedFictions基准也具有抗污染性,并通过人工过滤确保了高质量。
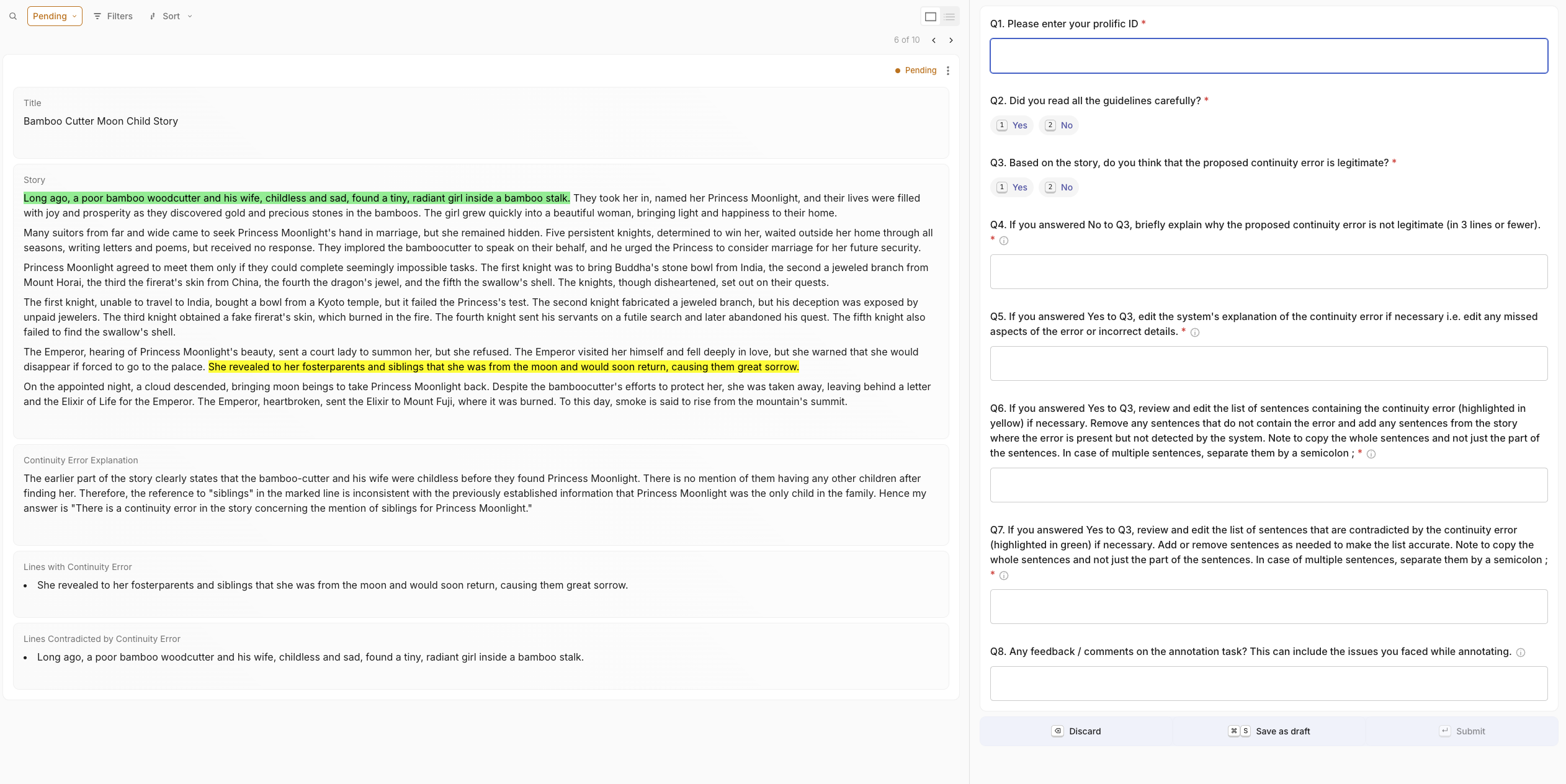
关键设计:FlawedFictionsMaker算法的关键设计包括:1)选择合适的故事片段作为插入情节漏洞的候选位置;2)根据预定义的规则,生成不同类型的情节漏洞,例如时间矛盾、地点矛盾、人物矛盾等;3)确保生成的情节漏洞与故事的整体逻辑相冲突,但又不会过于明显,以增加检测的难度。基准构建的关键设计包括:1)收集来自不同来源的故事,以增加多样性;2)人工过滤,确保故事的质量和情节漏洞的合理性;3)设计评估指标,例如准确率、召回率等,以评估LLM的性能。
🖼️ 关键图片
📊 实验亮点
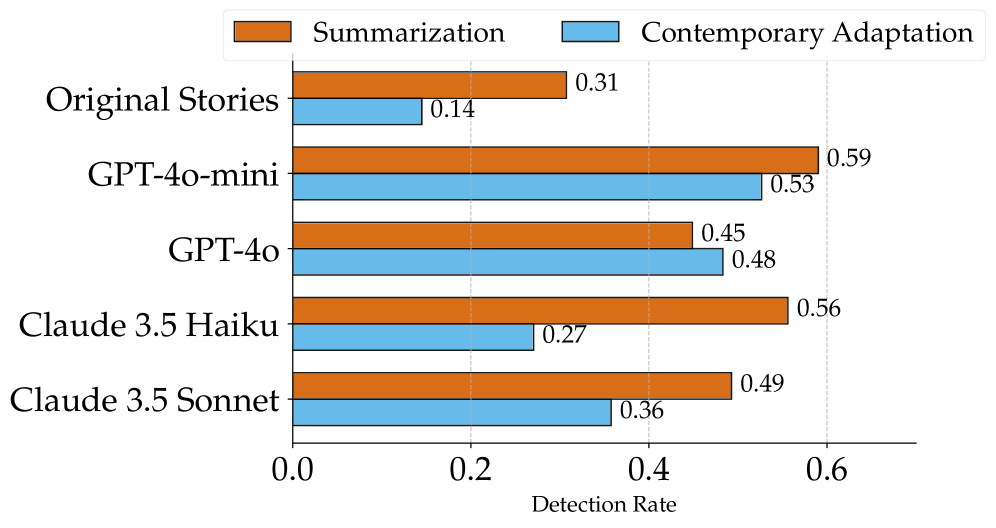
实验结果表明,即使是最先进的LLM在FlawedFictions基准上表现不佳,情节漏洞检测准确率显著低于人类水平。随着故事长度的增加,LLM的性能进一步下降。此外,LLM生成的故事比人类编写的故事更容易出现情节漏洞,情节漏洞检测率提高了50%以上。
🎯 应用场景
该研究成果可应用于评估和提升语言模型在故事理解、文本生成和对话系统等领域的性能。通过情节漏洞检测,可以提高语言模型生成文本的连贯性和逻辑性,减少错误和矛盾。此外,该研究还可以用于开发更智能的阅读理解系统和故事创作工具。
📄 摘要(原文)
Stories are a fundamental aspect of human experience. Engaging deeply with stories and spotting plot holes -- inconsistencies in a storyline that break the internal logic or rules of a story's world -- requires nuanced reasoning skills, including tracking entities and events and their interplay, abstract thinking, pragmatic narrative understanding, commonsense and social reasoning, and theory of mind. As Large Language Models (LLMs) increasingly generate, interpret, and modify text, rigorously assessing their narrative consistency and deeper language understanding becomes critical. However, existing benchmarks focus mainly on surface-level comprehension. In this work, we propose plot hole detection in stories as a proxy to evaluate language understanding and reasoning in LLMs. We introduce FlawedFictionsMaker, a novel algorithm to controllably and carefully synthesize plot holes in human-written stories. Using this algorithm, we construct a benchmark to evaluate LLMs' plot hole detection abilities in stories -- FlawedFictions -- , which is robust to contamination, with human filtering ensuring high quality. We find that state-of-the-art LLMs struggle in accurately solving FlawedFictions regardless of the reasoning effort allowed, with performance significantly degrading as story length increases. Finally, we show that LLM-based story summarization and story generation are prone to introducing plot holes, with more than 50% and 100% increases in plot hole detection rates with respect to human-written originals.