Rethinking LLM-Based Recommendations: A Personalized Query-Driven Parallel Integration
作者: Donghee Han, Hwanjun Song, Mun Yong Yi
分类: cs.IR, cs.CL
发布日期: 2025-04-16 (更新: 2025-09-14)
💡 一句话要点
提出Query-to-Recommendation框架,解决LLM推荐系统中的偏差和串行瓶颈问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推荐系统 并行计算 零样本学习 自适应重排序
📋 核心要点
- 现有基于LLM的推荐系统存在训练偏差和串行架构瓶颈,限制了其性能和效率。
- Query-to-Recommendation框架通过并行连接LLM和推荐模型,实现独立优化和优势互补。
- 实验结果表明,该框架在推荐性能、新颖性和多样性方面均有显著提升,最高达57%。
📝 摘要(中文)
最近的研究探索了将大型语言模型(LLM)集成到推荐系统中,但面临着一些挑战,包括训练引起的偏差和串行架构带来的瓶颈。为了有效解决这些问题,我们提出了一种名为Query-to-Recommendation的并行推荐框架,该框架将LLM与候选预选分离,从而能够直接在整个项目池上进行检索。我们的框架以并行方式连接LLM和推荐模型,允许每个组件独立利用其优势而不相互干扰。在该框架中,LLM用于生成特征丰富的项目描述和个性化的用户查询,从而能够以零样本方式捕获多样化的偏好并实现丰富的语义匹配。为了有效地结合LLM和协同信号的互补优势,我们引入了一种自适应重排序策略。大量的实验表明,性能提高了高达57%,同时也提高了推荐的新颖性和多样性。
🔬 方法详解
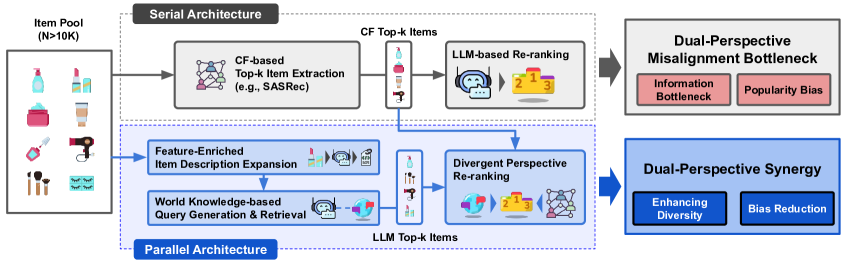
问题定义:现有基于LLM的推荐系统通常采用串行架构,即LLM先进行候选预选,然后推荐模型进行排序。这种方式存在两个主要问题:一是LLM的训练偏差会影响最终的推荐结果;二是串行架构导致计算效率低下,难以处理大规模项目池。
核心思路:Query-to-Recommendation框架的核心思路是将LLM与候选预选解耦,采用并行架构。LLM负责生成特征丰富的项目描述和个性化的用户查询,推荐模型直接在整个项目池上进行检索。通过这种方式,可以避免LLM的训练偏差,并提高计算效率。
技术框架:Query-to-Recommendation框架主要包含三个模块:1) LLM模块:负责生成特征丰富的项目描述和个性化的用户查询;2) 推荐模型模块:负责在整个项目池上进行检索,并生成候选推荐列表;3) 自适应重排序模块:负责结合LLM和协同信号的互补优势,对候选推荐列表进行重排序。
关键创新:该论文的关键创新在于提出了并行推荐框架,将LLM与候选预选解耦,从而避免了LLM的训练偏差,并提高了计算效率。此外,该论文还提出了自适应重排序策略,有效地结合了LLM和协同信号的互补优势。
关键设计:LLM模块使用预训练的LLM,通过微调或提示工程来生成特征丰富的项目描述和个性化的用户查询。推荐模型模块可以使用各种现有的推荐模型,如矩阵分解、神经协同过滤等。自适应重排序模块使用一个可学习的权重,来平衡LLM和协同信号的贡献。损失函数的设计目标是最大化推荐列表的准确性、新颖性和多样性。
🖼️ 关键图片

📊 实验亮点
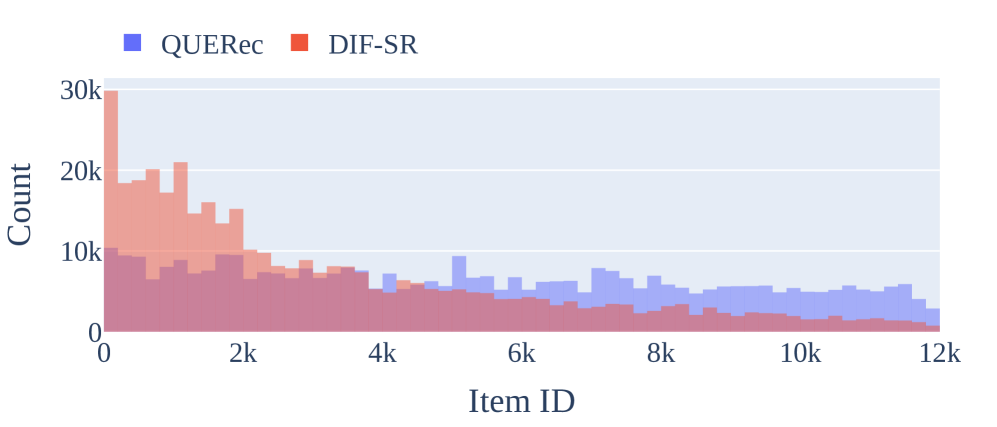
实验结果表明,Query-to-Recommendation框架在多个数据集上均取得了显著的性能提升,最高达57%。与传统的串行推荐系统相比,该框架在推荐的新颖性和多样性方面也有显著改善。此外,自适应重排序策略能够有效地结合LLM和协同信号的互补优势,进一步提升推荐性能。
🎯 应用场景
该研究成果可应用于各种推荐系统,尤其是在需要处理大规模项目池和捕捉用户多样化偏好的场景下,例如电商推荐、新闻推荐、视频推荐等。该框架能够提升推荐系统的性能、新颖性和多样性,从而提高用户满意度和平台收益。
📄 摘要(原文)
Recent studies have explored integrating large language models (LLMs) into recommendation systems but face several challenges, including training-induced bias and bottlenecks from serialized architecture. To effectively address these issues, we propose a Query-toRecommendation, a parallel recommendation framework that decouples LLMs from candidate pre-selection and instead enables direct retrieval over the entire item pool. Our framework connects LLMs and recommendation models in a parallel manner, allowing each component to independently utilize its strengths without interfering with the other. In this framework, LLMs are utilized to generate feature-enriched item descriptions and personalized user queries, allowing for capturing diverse preferences and enabling rich semantic matching in a zero-shot manner. To effectively combine the complementary strengths of LLM and collaborative signals, we introduce an adaptive reranking strategy. Extensive experiments demonstrate an improvement in performance up to 57%, while also improving the novelty and diversity of recommendations.