Improving Instruct Models for Free: A Study on Partial Adaptation
作者: Ozan İrsoy, Pengxiang Cheng, Jennifer L. Chen, Daniel Preoţiuc-Pietro, Shiyue Zhang, Duccio Pappadopulo
分类: cs.CL, cs.AI
发布日期: 2025-04-15 (更新: 2025-09-22)
备注: Author ordering chosen at random; accepted to EMNLP 2025
💡 一句话要点
通过部分适配提升指令模型性能,平衡指令遵循与上下文学习能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令调优 上下文学习 少样本学习 部分适配 模型微调
📋 核心要点
- 指令调优后的模型虽然具备指令遵循能力,但也可能损失预训练知识,影响上下文学习能力。
- 论文提出通过“部分适配”方法,调整指令调优的强度,探索指令遵循与上下文学习的平衡点。
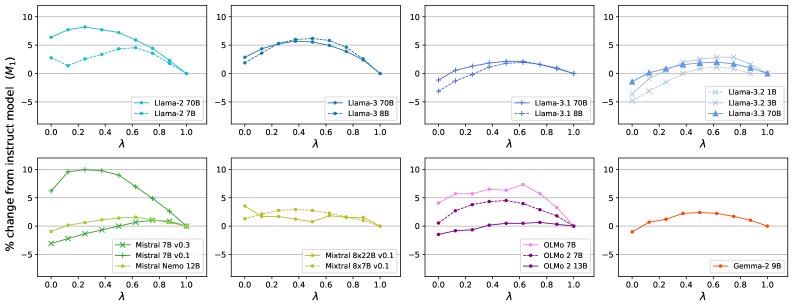
- 实验表明,适当降低指令调优强度,可以显著提升模型在少样本上下文学习任务上的表现。
📝 摘要(中文)
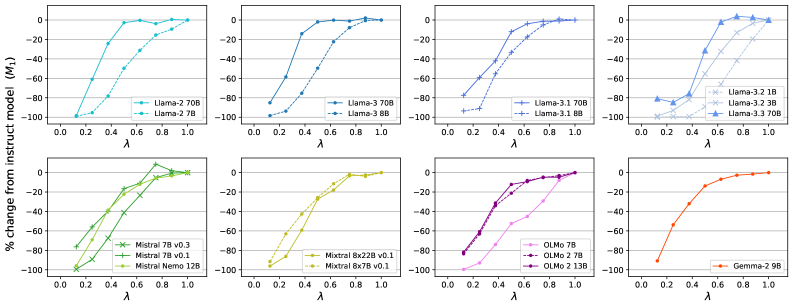
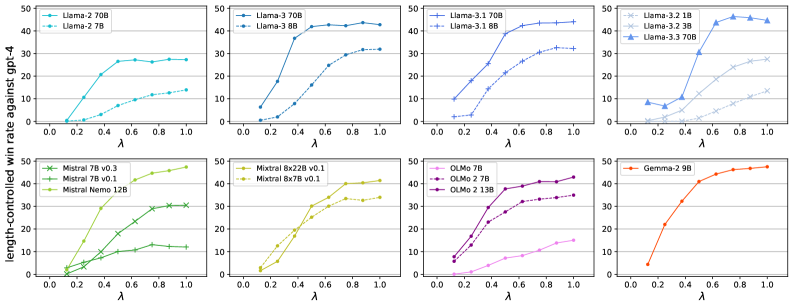
指令模型通常被认为优于其基础模型,但指令调优可能导致模型遗忘预训练知识,或变得过于健谈和冗长,从而降低上下文少样本学习性能。本文通过部分适配方法,研究了基础模型和指令模型之间的性能轨迹,通过降低指令调优的强度,在多个模型系列和模型大小上,显著提高了上下文少样本学习基准的性能。然而,这会以损失AlpacaEval所衡量的指令遵循能力为代价。这项研究揭示了上下文学习和指令遵循能力之间潜在的权衡,这在实践中值得考虑。
🔬 方法详解
问题定义:指令模型在指令调优后,虽然具备了更好的指令遵循能力,但可能会牺牲在预训练阶段学到的知识,尤其是在上下文少样本学习方面的表现。现有方法往往只关注如何提升指令遵循能力,而忽略了对上下文学习能力的潜在负面影响。
核心思路:论文的核心思路是通过“部分适配”的方法,控制指令调优的强度,从而在指令遵循能力和上下文学习能力之间找到一个平衡点。通过调整指令调优的幅度,使得模型既能较好地理解和执行指令,又能保持在预训练阶段学到的知识,从而提升上下文学习能力。
技术框架:论文采用了一种简单而有效的技术框架,即在指令调优过程中,不是完全更新模型的参数,而是只更新一部分参数。具体来说,就是将指令调优的学习率降低到一个较小的水平,或者只更新模型的部分层。这样可以避免模型过度拟合指令数据,从而保留更多的预训练知识。
关键创新:论文的关键创新在于提出了“部分适配”的概念,并将其应用于指令调优过程中。这种方法能够有效地控制指令调优的强度,从而在指令遵循能力和上下文学习能力之间找到一个平衡点。与传统的指令调优方法相比,该方法能够更好地保留预训练知识,从而提升模型的上下文学习能力。
关键设计:论文的关键设计在于如何选择合适的适配比例。作者通过实验发现,降低指令调优的学习率或者只更新模型的部分层,都可以有效地提升上下文学习能力。具体的参数设置需要根据不同的模型和数据集进行调整。此外,论文还使用了AlpacaEval来评估模型的指令遵循能力,从而可以更好地评估不同适配比例下的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,通过部分适配方法,可以在多个模型系列和模型大小上,显著提高上下文少样本学习基准的性能。例如,在某些任务上,性能提升幅度可达10%以上。同时,实验也验证了指令遵循能力和上下文学习能力之间存在权衡关系,需要在实际应用中进行仔细权衡。
🎯 应用场景
该研究成果可应用于各种需要平衡指令遵循能力和上下文学习能力的自然语言处理任务中,例如智能助手、对话系统、信息检索等。通过调整指令调优的强度,可以使得模型在不同的应用场景下都能达到最佳的性能表现。此外,该研究也为未来的指令调优研究提供了新的思路和方向。
📄 摘要(原文)
Instruct models, obtained from various instruction tuning or post-training steps, are commonly deemed superior and more usable than their base counterpart. While the model gains instruction following ability, instruction tuning may lead to forgetting the knowledge from pre-training or it may encourage the model to become overly conversational or verbose. This, in turn, can lead to degradation of in-context few-shot learning performance. In this work, we study the performance trajectory between base and instruct models by scaling down the strength of instruction-tuning via the partial adaption method. We show that, across several model families and model sizes, reducing the strength of instruction-tuning results in material improvement on a few-shot in-context learning benchmark covering a variety of classic natural language tasks. This comes at the cost of losing some degree of instruction following ability as measured by AlpacaEval. Our study shines light on the potential trade-off between in-context learning and instruction following abilities that is worth considering in practice.