Masculine Defaults via Gendered Discourse in Podcasts and Large Language Models
作者: Maria Teleki, Xiangjue Dong, Haoran Liu, James Caverlee
分类: cs.CL, cs.AI, cs.CY, cs.LG, cs.SI
发布日期: 2025-04-15
备注: To appear in ICWSM 2025
💡 一句话要点
提出性别化语篇相关框架与语篇词嵌入关联测试,揭示播客和LLM中的男性默认偏见。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 性别偏见 男性默认 大型语言模型 语篇分析 词嵌入 播客 社会计算
📋 核心要点
- 现有方法缺乏大规模发现和分析口语内容中性别化语篇词汇的有效手段,难以量化LLM中的性别偏见。
- 提出性别化语篇相关框架(GDCF)和语篇词嵌入关联测试(D-WEAT),用于发现性别化语篇词汇并评估LLM中的性别偏见。
- 通过分析15117集播客,发现商业、技术/政治和视频游戏领域存在男性默认偏见,且LLM对男性语篇词汇的表示更稳定。
📝 摘要(中文)
男性默认偏见是一种重要的性别偏见,但由于研究不足,往往难以察觉。它包含三个关键部分:文化背景、男性特征或行为,以及对这些特征或行为的奖励或接受。本文研究了基于语篇的男性默认偏见,并提出了一个双重框架:(i) 通过性别化语篇相关框架(GDCF)大规模发现和分析口语内容中的性别化语篇词汇;(ii) 通过语篇词嵌入关联测试(D-WEAT)测量LLM中与这些性别化语篇词汇相关的性别偏见。研究聚焦于播客,分析了15117集播客。通过LDA和BERTopic分析性别与语篇词汇之间的相关性,自动形成性别化语篇词汇列表。研究发现,在商业、技术/政治和视频游戏领域存在基于性别化语篇的男性默认偏见。进一步研究了OpenAI的先进LLM嵌入模型对这些性别化语篇词汇的表示,发现男性语篇词汇比女性语篇词汇具有更稳定和鲁棒的表示,这可能导致男性在下游任务中获得更好的系统性能。因此,男性因其语篇模式而获得更好的系统性能,这种嵌入差异是一种表征性伤害和男性默认偏见。
🔬 方法详解
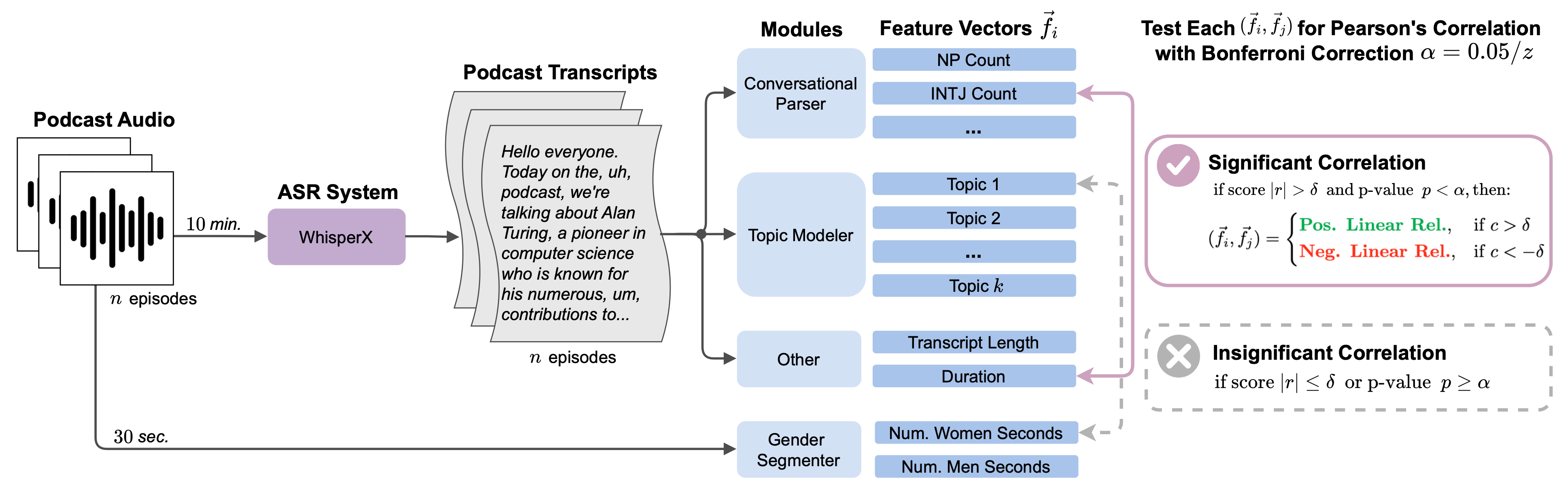
问题定义:论文旨在解决男性默认偏见在播客等口语内容以及大型语言模型(LLM)中难以被发现和量化的问题。现有方法难以大规模地从口语内容中提取性别化的语篇特征,并且缺乏有效的工具来评估LLM中与这些语篇特征相关的性别偏见。
核心思路:论文的核心思路是首先通过分析播客等口语内容,识别出与性别相关的语篇词汇,然后利用这些词汇来评估LLM中存在的性别偏见。通过分析LLM对这些性别化词汇的嵌入表示,可以揭示LLM是否对男性化的语篇模式赋予了更高的权重或更稳定的表示。
技术框架:论文提出了一个双重框架,包含两个主要模块:(1) 性别化语篇相关框架(GDCF):利用LDA和BERTopic等主题模型,分析播客文本中性别与语篇词汇之间的相关性,自动生成性别化语篇词汇列表。(2) 语篇词嵌入关联测试(D-WEAT):利用WEAT方法,评估LLM对性别化语篇词汇的嵌入表示,分析是否存在与性别相关的偏差。
关键创新:论文的关键创新在于提出了一个能够自动发现和分析口语内容中性别化语篇词汇的框架,并将其应用于评估LLM中的性别偏见。与以往的研究主要关注文本数据不同,该研究关注的是口语内容,更贴近日常交流,也更能反映潜在的性别偏见。
关键设计:在GDCF中,使用了LDA和BERTopic两种主题模型来提取语篇词汇,并计算它们与性别之间的相关性。在D-WEAT中,使用了余弦相似度来衡量词汇嵌入之间的关联程度,并计算了效应量来量化性别偏见的程度。论文分析了OpenAI的先进LLM嵌入模型,具体模型名称未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在商业、技术/政治和视频游戏等领域,播客内容中存在明显的男性默认偏见。更重要的是,研究发现OpenAI的LLM对男性语篇词汇的表示比女性语篇词汇更稳定和鲁棒,这意味着男性更容易从LLM中获得更好的性能,从而验证了男性默认偏见的存在。
🎯 应用场景
该研究成果可应用于开发更公平、更公正的AI系统,尤其是在语音识别、对话系统等领域。通过识别和消除LLM中的性别偏见,可以避免AI系统在实际应用中强化现有的性别刻板印象,从而促进性别平等。此外,该方法还可以扩展到其他类型的偏见分析,例如种族偏见、年龄偏见等。
📄 摘要(原文)
Masculine defaults are widely recognized as a significant type of gender bias, but they are often unseen as they are under-researched. Masculine defaults involve three key parts: (i) the cultural context, (ii) the masculine characteristics or behaviors, and (iii) the reward for, or simply acceptance of, those masculine characteristics or behaviors. In this work, we study discourse-based masculine defaults, and propose a twofold framework for (i) the large-scale discovery and analysis of gendered discourse words in spoken content via our Gendered Discourse Correlation Framework (GDCF); and (ii) the measurement of the gender bias associated with these gendered discourse words in LLMs via our Discourse Word-Embedding Association Test (D-WEAT). We focus our study on podcasts, a popular and growing form of social media, analyzing 15,117 podcast episodes. We analyze correlations between gender and discourse words -- discovered via LDA and BERTopic -- to automatically form gendered discourse word lists. We then study the prevalence of these gendered discourse words in domain-specific contexts, and find that gendered discourse-based masculine defaults exist in the domains of business, technology/politics, and video games. Next, we study the representation of these gendered discourse words from a state-of-the-art LLM embedding model from OpenAI, and find that the masculine discourse words have a more stable and robust representation than the feminine discourse words, which may result in better system performance on downstream tasks for men. Hence, men are rewarded for their discourse patterns with better system performance by one of the state-of-the-art language models -- and this embedding disparity is a representational harm and a masculine default.