Minitron-SSM: Efficient Hybrid Language Model Compression through Group-Aware SSM Pruning
作者: Ali Taghibakhshi, Sharath Turuvekere Sreenivas, Saurav Muralidharan, Marcin Chochowski, Yashaswi Karnati, Raviraj Joshi, Ameya Sunil Mahabaleshwarkar, Zijia Chen, Yoshi Suhara, Oluwatobi Olabiyi, Daniel Korzekwa, Mostofa Patwary, Mohammad Shoeybi, Jan Kautz, Bryan Catanzaro, Ashwath Aithal, Nima Tajbakhsh, Pavlo Molchanov
分类: cs.CL
发布日期: 2025-04-15 (更新: 2025-10-31)
💡 一句话要点
Minitron-SSM:通过分组感知SSM剪枝实现高效混合语言模型压缩
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 混合语言模型 模型压缩 状态空间模型 分组感知剪枝 知识蒸馏 推理加速 Nemotron-H
📋 核心要点
- 现有方法在压缩混合LLM架构时,未能充分考虑SSM模块的结构特性,导致压缩效果不佳。
- 论文提出分组感知剪枝策略,旨在保持SSM块的结构完整性,从而提升序列建模能力和压缩效率。
- 实验结果表明,该方法在压缩Nemotron-H 8B模型至4B参数时,实现了更高的精度和更快的推理速度。
📝 摘要(中文)
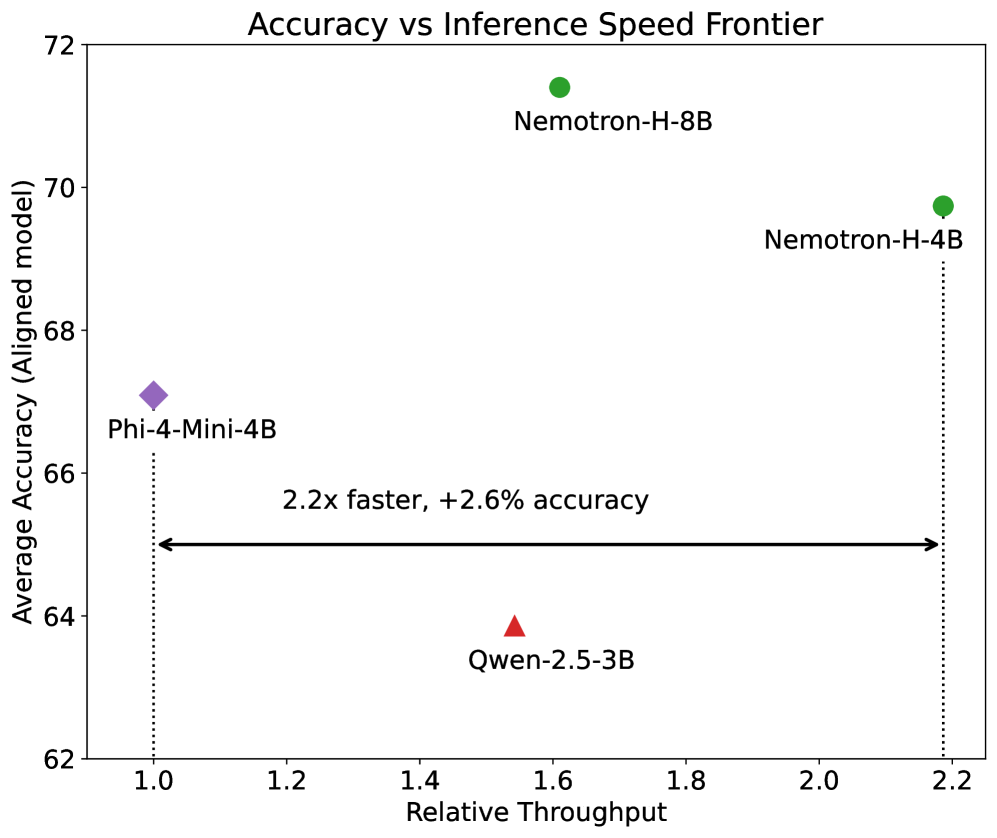
本文提出了一种针对混合LLM架构(结合Attention和状态空间模型SSM)的压缩方法。通过引入一种新的分组感知剪枝策略,该策略能够保持SSM块的结构完整性及其序列建模能力,从而提升压缩效果。研究表明,这种SSM剪枝对于实现优于传统方法的精度和推理速度至关重要。该压缩方案结合了SSM、FFN、嵌入维度和层剪枝,并采用基于知识蒸馏的再训练,类似于MINITRON技术。通过这种方法,可以将Nemotron-H 8B混合模型压缩到4B参数,同时使用减少高达40倍的训练tokens。压缩后的模型在实现2倍更快推理速度的同时,超越了同等规模模型的精度,显著提升了Pareto前沿。
🔬 方法详解
问题定义:论文旨在解决混合语言模型(LLM)的压缩问题,特别是结合了Attention机制和状态空间模型(SSM)的混合架构。现有压缩方法,如直接剪枝或蒸馏,在应用于混合架构时,可能破坏SSM模块的结构完整性,导致性能下降。因此,如何有效地压缩混合LLM,同时保持其精度和推理速度,是一个关键挑战。
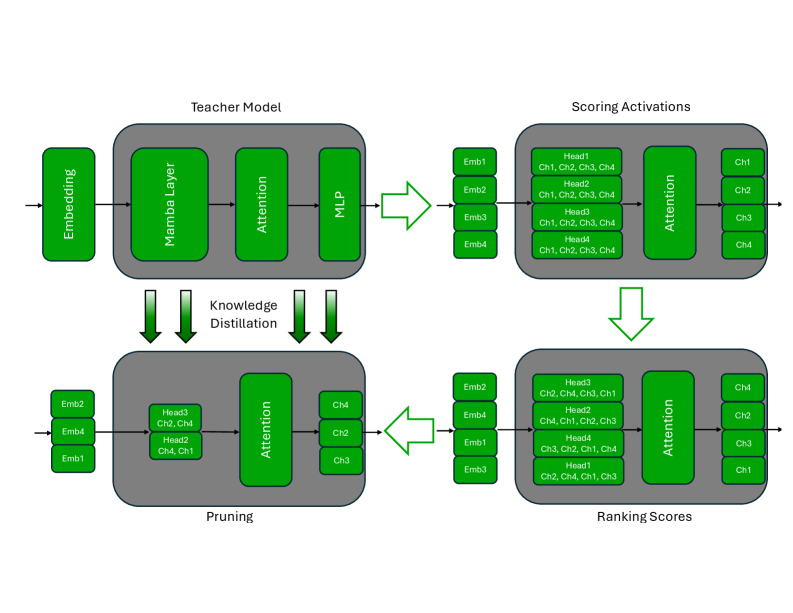
核心思路:论文的核心思路是采用一种分组感知的剪枝策略,专门针对SSM模块进行优化。该策略旨在保留SSM块的结构完整性,确保其序列建模能力不受影响。通过将SSM模块视为一个整体进行剪枝,可以避免破坏其内部依赖关系,从而更好地保持模型的性能。
技术框架:该压缩方案主要包含以下几个阶段:1) 模型分析:分析混合LLM中SSM和Attention模块的贡献,确定剪枝的优先级。2) 分组感知剪枝:对SSM、FFN、嵌入维度和层进行剪枝,采用分组感知策略保证SSM模块的结构完整性。3) 知识蒸馏再训练:利用原始模型作为教师模型,对剪枝后的模型进行知识蒸馏,恢复精度。4) 模型评估:评估压缩后模型的精度和推理速度,并与基线模型进行比较。
关键创新:论文的关键创新在于提出了分组感知SSM剪枝策略。与传统的独立剪枝方法不同,该策略将SSM模块视为一个整体进行剪枝,从而避免破坏其内部结构和序列建模能力。这种分组感知的方法能够更有效地压缩混合LLM,同时保持其性能。
关键设计:论文的关键设计包括:1) 分组策略:定义了SSM模块的分组方式,确保剪枝操作不会破坏其内部连接。2) 剪枝比例:根据模型分析结果,确定不同模块的剪枝比例,以平衡压缩率和性能。3) 知识蒸馏损失函数:设计了合适的知识蒸馏损失函数,用于指导剪枝后模型的再训练,恢复精度。4) 超参数调优:对剪枝和蒸馏过程中的超参数进行调优,以获得最佳的压缩效果。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用该方法可以将Nemotron-H 8B混合模型压缩到4B参数,同时使用减少高达40倍的训练tokens。压缩后的模型在精度上超越了同等规模的模型,并且实现了2倍的推理速度提升。这些结果表明,该方法在压缩混合LLM方面具有显著优势。
🎯 应用场景
该研究成果可应用于各种需要高效部署大型语言模型的场景,例如移动设备、边缘计算和资源受限的环境。通过压缩模型大小和提高推理速度,可以降低部署成本,并使更多用户能够访问先进的AI技术。此外,该方法还可以促进混合架构LLM在实际应用中的普及。
📄 摘要(原文)
Hybrid LLM architectures that combine Attention and State Space Models (SSMs) achieve state-of-the-art accuracy and runtime performance. Recent work has demonstrated that applying compression and distillation to Attention-only models yields smaller, more accurate models at a fraction of the training cost. In this work, we explore the effectiveness of compressing Hybrid architectures. We introduce a novel group-aware pruning strategy that preserves the structural integrity of SSM blocks and their sequence modeling capabilities. Furthermore, we demonstrate the necessity of such SSM pruning to achieve improved accuracy and inference speed compared to traditional approaches. Our compression recipe combines SSM, FFN, embedding dimension, and layer pruning, followed by knowledge distillation-based retraining, similar to the MINITRON technique. Using this approach, we compress the Nemotron-H 8B Hybrid model down to 4B parameters with up to 40x fewer training tokens. The resulting model surpasses the accuracy of similarly-sized models while achieving 2x faster inference, significantly advancing the Pareto frontier.