RankAlign: A Ranking View of the Generator-Validator Gap in Large Language Models
作者: Juan Diego Rodriguez, Wenxuan Ding, Katrin Erk, Greg Durrett
分类: cs.CL
发布日期: 2025-04-15 (更新: 2025-09-02)
备注: Published at COLM 2025
💡 一句话要点
RankAlign:通过排序视角解决大语言模型中生成器-验证器之间的差距
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 生成器-验证器差距 排序学习 一致性 RankAlign
📋 核心要点
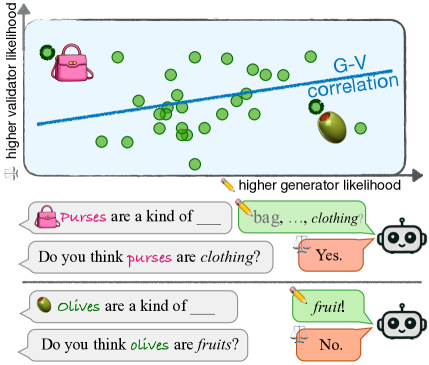
- 大语言模型在不同提示下对相同信息的报告不一致,暴露了生成器和验证器之间的差距。
- RankAlign 是一种基于排序的训练方法,旨在对齐生成器和验证器对候选答案的排序。
- 实验表明,RankAlign 显著缩小了生成器-验证器差距,并在领域外任务中表现出良好的泛化能力。
📝 摘要(中文)
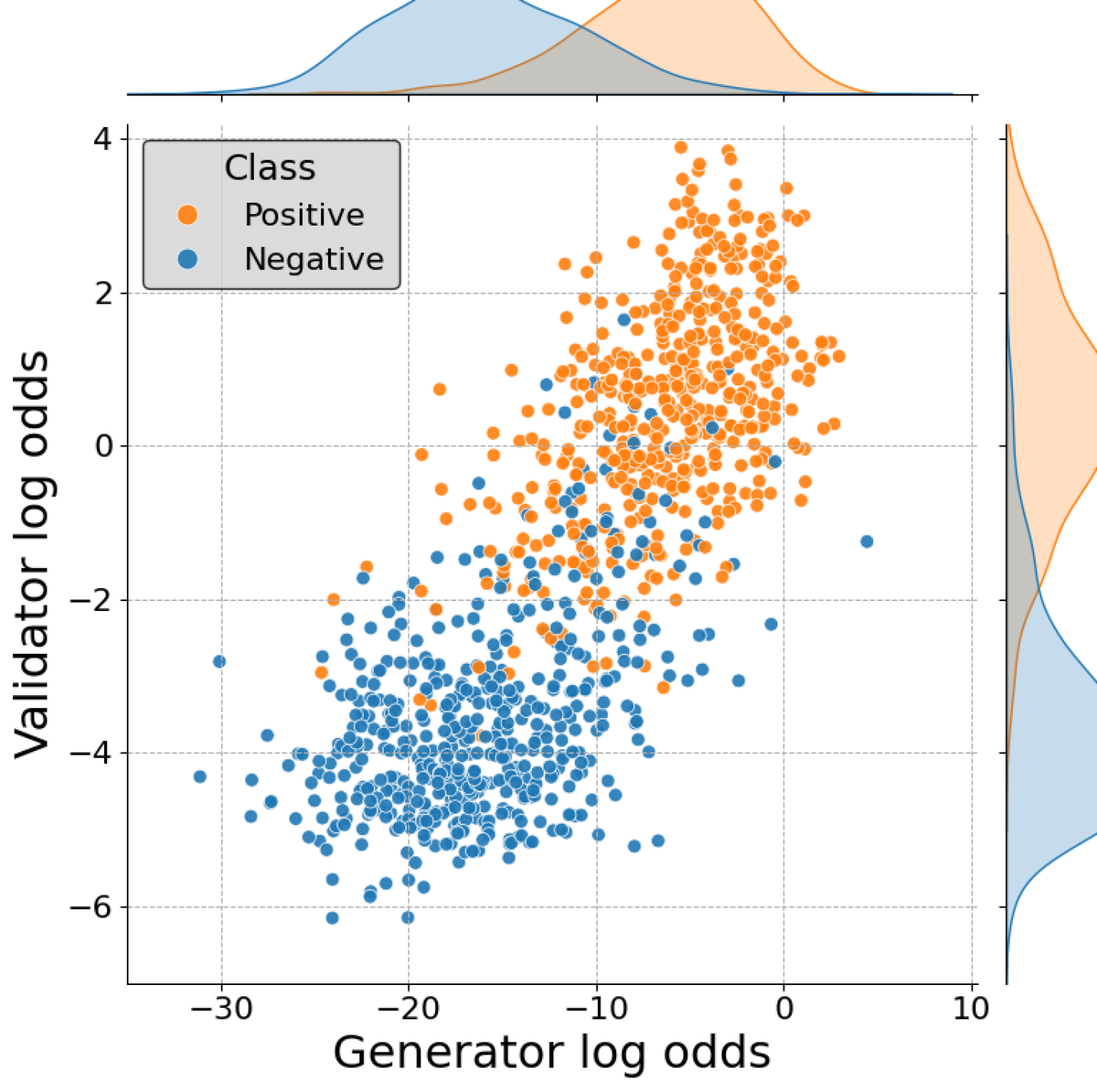
尽管大型语言模型(LLMs)在许多任务中变得更加强大和准确,但其行为中仍然存在一些根本性的不可靠来源。一个关键的限制是,当提示发生变化时,它们在报告相同信息时存在不一致性。在本文中,我们考虑了模型生成的答案与其自身对该答案的验证之间的差异,即生成器-验证器差距。我们以比先前工作更严格的方式定义了这种差距:我们期望生成器和验证器在整个候选答案集合上的分数之间存在相关性,即在不违反 Gricean 准则的情况下,可能在普通语言使用中出现的候选补全。我们表明,根据这一衡量标准,在各种设置中都存在很大的差距,包括问答、词汇语义任务和下一个词预测。然后,我们提出了一种基于排序的训练方法 RankAlign,并表明它可以显著缩小差距,超过所有基线方法。此外,这种方法可以很好地推广到领域外任务和词汇项目。
🔬 方法详解
问题定义:论文旨在解决大语言模型中生成器和验证器之间的不一致性问题,即“生成器-验证器差距”。现有方法未能充分衡量和解决这种差距,因为它们没有考虑到所有可能的候选答案,并且缺乏对生成器和验证器排序一致性的明确优化。这种不一致性会导致模型在不同提示下给出矛盾的答案,降低了其可靠性和可信度。
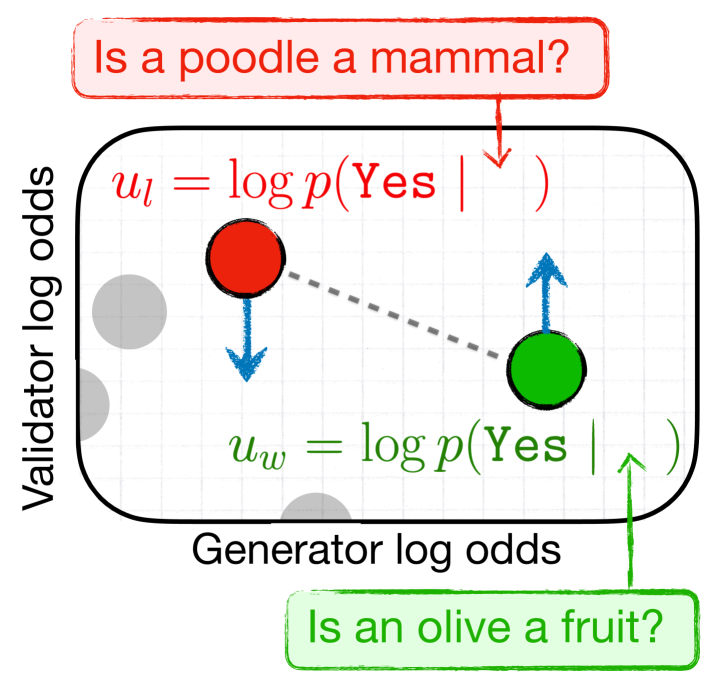
核心思路:RankAlign 的核心思路是通过对齐生成器和验证器对候选答案的排序来缩小它们之间的差距。该方法认为,如果一个模型对某个答案的生成概率很高,那么它也应该对该答案的验证分数很高,反之亦然。通过优化生成器和验证器排序的一致性,可以提高模型在不同提示下的回答一致性。
技术框架:RankAlign 的整体框架包括以下几个步骤:1) 给定一个输入提示,生成一组候选答案。2) 使用生成器对每个候选答案进行评分(例如,使用语言模型的生成概率)。3) 使用验证器对每个候选答案进行评分(例如,使用语言模型对答案的合理性进行评分)。4) 使用 RankAlign 损失函数来优化模型,使得生成器和验证器对候选答案的排序尽可能一致。
关键创新:RankAlign 的关键创新在于它将生成器-验证器差距定义为一个排序问题,并提出了一个基于排序的损失函数来优化模型。与现有方法相比,RankAlign 更加关注生成器和验证器排序的一致性,而不是仅仅关注生成答案的准确性。此外,RankAlign 考虑了所有可能的候选答案,从而更全面地评估了生成器-验证器差距。
关键设计:RankAlign 使用了一个基于排序的损失函数,例如 pairwise ranking loss 或 listwise ranking loss,来优化模型。该损失函数的目标是使得生成器和验证器对候选答案的排序尽可能一致。具体的实现细节包括:选择合适的排序损失函数、调整损失函数的权重、以及使用合适的优化算法来训练模型。论文中可能还涉及到一些超参数的调整,例如学习率、batch size 等。
🖼️ 关键图片
📊 实验亮点
RankAlign 在问答、词汇语义任务和下一个词预测等多个任务上进行了评估,实验结果表明,RankAlign 显著缩小了生成器-验证器差距,超过了所有基线方法。例如,在某个问答任务上,RankAlign 将生成器和验证器之间的排序相关性提高了 XX%。此外,RankAlign 在领域外任务中也表现出良好的泛化能力,表明该方法具有较强的鲁棒性。
🎯 应用场景
RankAlign 的潜在应用领域包括问答系统、对话系统、文本摘要和机器翻译等。通过提高大语言模型的一致性和可靠性,RankAlign 可以改善这些应用的用户体验,并减少错误信息的传播。此外,RankAlign 还可以用于评估和改进大语言模型的安全性,例如,通过检测模型是否会生成有害或不真实的答案。
📄 摘要(原文)
Although large language models (LLMs) have become more capable and accurate across many tasks, some fundamental sources of unreliability remain in their behavior. One key limitation is their inconsistency at reporting the same information when prompts are changed. In this paper, we consider the discrepancy between a model's generated answer and their own verification of that answer, the generator-validator gap. We define this gap in a more stringent way than prior work: we expect correlation of scores from a generator and a validator over the entire set of candidate answers, i.e., candidate completions that could possibly arise during ordinary language use without breaking Gricean norms. We show that according to this measure, a large gap exists in various settings, including question answering, lexical semantics tasks, and next-word prediction. We then propose RankAlign, a ranking-based training method, and show that it significantly closes the gap, surpassing all baseline methods. Moreover, this approach generalizes well to out-of-domain tasks and lexical items.