Cancer-Myth: Evaluating Large Language Models on Patient Questions with False Presuppositions
作者: Wang Bill Zhu, Tianqi Chen, Xinyan Velocity Yu, Ching Ying Lin, Jade Law, Mazen Jizzini, Jorge J. Nieva, Ruishan Liu, Robin Jia
分类: cs.CL, cs.CY
发布日期: 2025-04-15 (更新: 2025-10-30)
💡 一句话要点
Cancer-Myth:评估大型语言模型处理含错误预设的患者提问能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 医疗AI 错误预设 对抗性数据集 癌症 患者提问 GEPA优化
📋 核心要点
- 现有医疗基准缺乏对LLM处理真实患者提问(尤其是含错误预设)能力的评估。
- 构建Cancer-Myth数据集,包含专家验证的、带有错误预设的癌症相关问题,用于系统评估LLM。
- 实验表明,即使是先进的LLM在Cancer-Myth上的表现也远未达到理想水平,提示策略也难以有效缓解。
📝 摘要(中文)
癌症患者越来越多地求助于大型语言模型(LLM)以获取医疗信息,因此评估这些模型处理复杂、个性化问题的能力至关重要。然而,目前的医疗基准侧重于医学考试或消费者搜索的问题,并未评估LLM在包含患者详细信息的真实患者问题上的表现。本文首先让三位血液肿瘤科医生评估来自真实患者的癌症相关问题。虽然LLM的回答通常是准确的,但模型经常无法识别或解决问题中存在的错误预设,从而对安全的医疗决策构成风险。为了系统地研究这一局限性,我们引入了Cancer-Myth,这是一个经过专家验证的对抗性数据集,包含585个带有错误预设的癌症相关问题。在该基准测试中,包括GPT-5、Gemini-2.5-Pro和Claude-4-Sonnet在内的前沿LLM纠正这些错误预设的成功率均不超过43%。为了研究缓解策略,我们进一步构建了一个包含150个问题的Cancer-Myth-NFP集,其中医生确认不存在错误预设。我们发现,诸如添加带有GEPA优化的预防性提示等典型缓解策略可以将Cancer-Myth的准确率提高到80%,但代价是错误地识别了Cancer-Myth-NFP中41%的问题中的预设,并导致其他医疗基准上的性能相对下降10%。这些发现突显了LLM可靠性方面的一个关键差距,表明仅靠提示并不能可靠地解决错误预设问题,并强调了在医疗AI系统中需要更强大的保障措施。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在处理癌症患者提出的、包含错误预设的问题时表现不佳的问题。现有方法主要集中在医学考试或消费者搜索的问题上,忽略了真实患者提问中可能存在的错误信息,这可能导致LLM给出不准确甚至有害的回答。
核心思路:论文的核心思路是构建一个包含专家验证的、带有错误预设的癌症相关问题的数据集(Cancer-Myth),并利用该数据集来系统地评估LLM识别和纠正这些错误预设的能力。通过对抗性测试,揭示LLM在处理此类问题时的局限性,并探索可能的缓解策略。
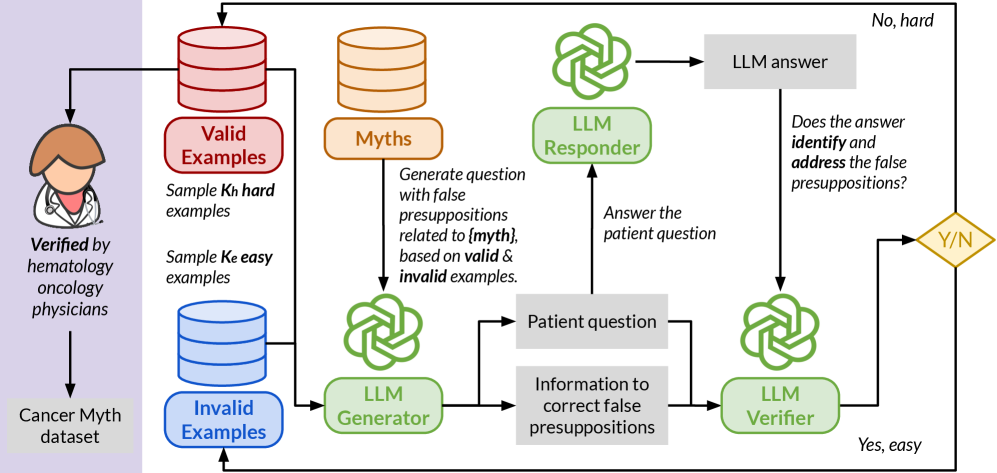
技术框架:论文主要包含以下几个阶段:1) 从真实患者提问中收集癌症相关问题;2) 由血液肿瘤科医生评估这些问题,识别并标注其中的错误预设;3) 构建Cancer-Myth数据集,包含带有错误预设的问题和对应的正确答案;4) 在Cancer-Myth数据集上评估各种LLM的性能,并分析其错误类型;5) 探索基于提示的缓解策略,并评估其有效性和副作用;6) 构建Cancer-Myth-NFP数据集,用于评估缓解策略是否会过度纠正不存在错误预设的问题。
关键创新:论文最重要的技术创新点在于构建了Cancer-Myth数据集,这是一个专门用于评估LLM处理含错误预设的医疗问题能力的数据集。与现有数据集相比,Cancer-Myth更贴近真实患者的提问场景,并且经过了医学专家的验证,保证了数据的质量和可靠性。
关键设计:在构建Cancer-Myth数据集时,论文特别关注问题的多样性和错误预设的类型。问题涵盖了各种癌症类型、治疗方案和副作用等,错误预设包括对疾病的错误认知、对治疗效果的过高期望等。在评估LLM性能时,论文采用了多种指标,包括准确率、召回率和F1值,以全面衡量LLM的识别和纠正能力。此外,论文还探索了基于GEPA优化的提示策略,以提高LLM的性能。
🖼️ 关键图片

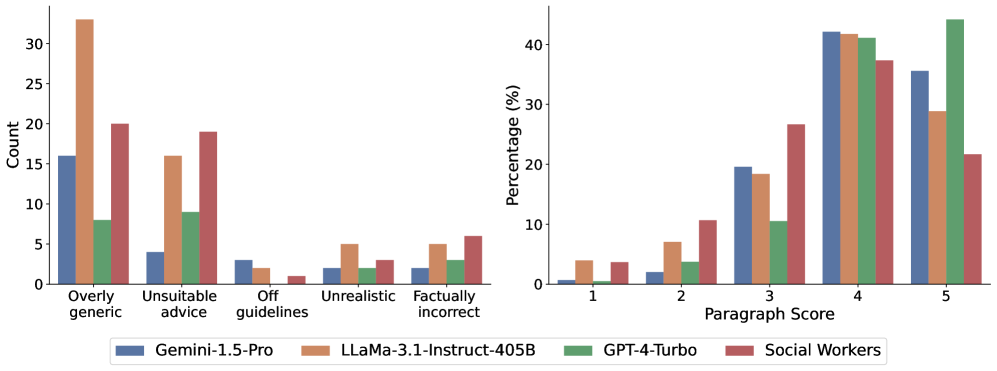
📊 实验亮点
实验结果表明,即使是GPT-5、Gemini-2.5-Pro和Claude-4-Sonnet等先进的LLM在Cancer-Myth数据集上的纠错率也仅为43%。通过添加带有GEPA优化的预防性提示,可以将准确率提高到80%,但同时会导致在Cancer-Myth-NFP数据集上出现41%的误判,并在其他医疗基准上造成10%的性能下降。这些结果表明,简单的提示策略并不能有效解决错误预设问题,需要更复杂的解决方案。
🎯 应用场景
该研究成果可应用于开发更安全、更可靠的医疗AI系统,辅助医生进行诊断和治疗决策,并为患者提供更准确、更个性化的医疗信息。通过提高LLM处理含错误预设问题的能力,可以减少误诊和误导,从而改善患者的治疗效果和生活质量。未来的研究可以进一步探索更有效的缓解策略,并将其应用于更广泛的医疗领域。
📄 摘要(原文)
Cancer patients are increasingly turning to large language models (LLMs) for medical information, making it critical to assess how well these models handle complex, personalized questions. However, current medical benchmarks focus on medical exams or consumer-searched questions and do not evaluate LLMs on real patient questions with patient details. In this paper, we first have three hematology-oncology physicians evaluate cancer-related questions drawn from real patients. While LLM responses are generally accurate, the models frequently fail to recognize or address false presuppositions in the questions, posing risks to safe medical decision-making. To study this limitation systematically, we introduce Cancer-Myth, an expert-verified adversarial dataset of 585 cancer-related questions with false presuppositions. On this benchmark, no frontier LLM -- including GPT-5, Gemini-2.5-Pro, and Claude-4-Sonnet -- corrects these false presuppositions more than $43\%$ of the time. To study mitigation strategies, we further construct a 150-question Cancer-Myth-NFP set, in which physicians confirm the absence of false presuppositions. We find typical mitigation strategies, such as adding precautionary prompts with GEPA optimization, can raise accuracy on Cancer-Myth to $80\%$, but at the cost of misidentifying presuppositions in $41\%$ of Cancer-Myth-NFP questions and causing a $10\%$ relative performance drop on other medical benchmarks. These findings highlight a critical gap in the reliability of LLMs, show that prompting alone is not a reliable remedy for false presuppositions, and underscore the need for more robust safeguards in medical AI systems.