Understanding LLMs' Cross-Lingual Context Retrieval: How Good It Is And Where It Comes From
作者: Changjiang Gao, Hankun Lin, Xin Huang, Xue Han, Junlan Feng, Chao Deng, Jiajun Chen, Shujian Huang
分类: cs.CL
发布日期: 2025-04-15 (更新: 2025-10-18)
💡 一句话要点
评估并解析大语言模型跨语言上下文检索能力及其形成机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨语言上下文检索 大型语言模型 机器阅读理解 多语言学习 预训练 后训练 模型评估 性能分析
📋 核心要点
- 现有LLM跨语言上下文检索能力评估不足,其性能和内在机制尚不明确,阻碍了跨语言应用的发展。
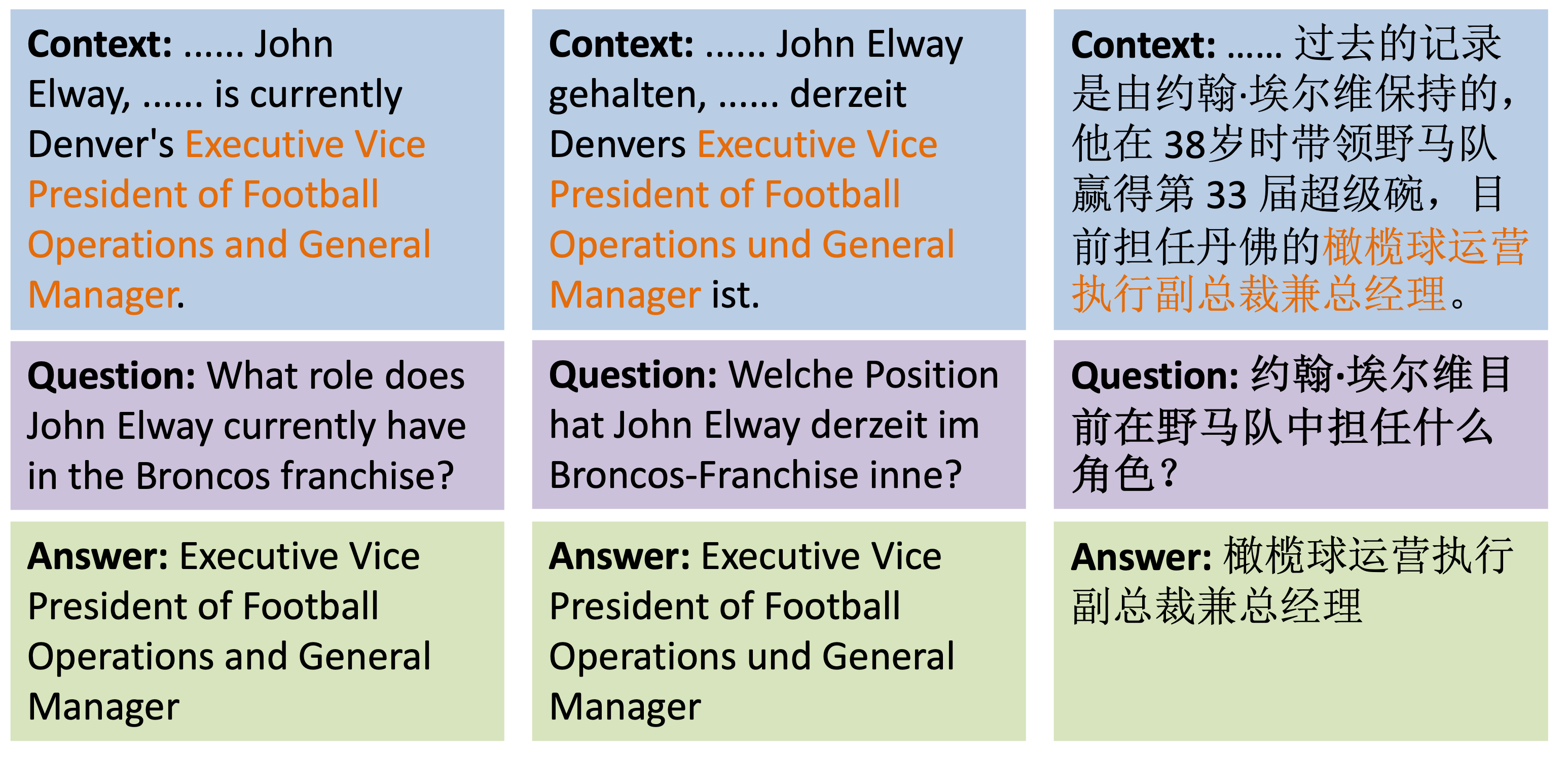
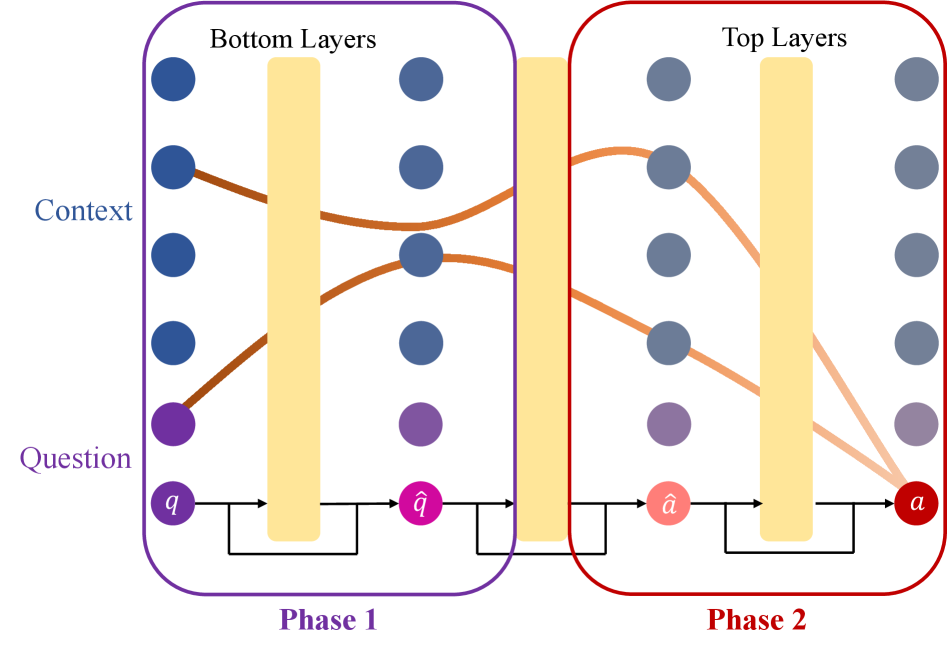
- 通过跨语言机器阅读理解任务,将跨语言上下文检索过程分解为问题编码和答案检索两个阶段进行分析。
- 实验结果表明,后训练的开源LLM表现出色,且更大规模的预训练不一定能提升跨语言检索能力,需要后训练激发潜力。
📝 摘要(中文)
本文旨在评估和分析大型语言模型(LLMs)的跨语言上下文检索能力,这是跨语言对齐的一个基本方面。研究以跨语言机器阅读理解(xMRC)为代表性场景,评估了超过40个LLM在12种语言上的表现。结果表明,经过后训练的开源LLM展现出强大的跨语言上下文检索能力,可与GPT-4o等闭源LLM相媲美,并且后训练显著提升了其预估的oracle性能。机制分析表明,跨语言上下文检索过程可分为问题编码和答案检索两个主要阶段,分别在预训练和后训练中形成。阶段稳定性与xMRC性能相关,xMRC瓶颈位于第二阶段的最后模型层,后训练的效果在此处尤为明显。研究还表明,更大规模的预训练并不能提高xMRC性能,相反,更大的LLM需要进一步的多语言后训练才能充分释放其跨语言上下文检索潜力。
🔬 方法详解
问题定义:论文旨在深入理解和评估大型语言模型(LLMs)在跨语言环境下的上下文检索能力。现有方法缺乏对LLMs跨语言检索能力的系统性评估,以及对其内在机制的深入理解,这限制了LLMs在多语言场景下的应用。
核心思路:论文的核心思路是将跨语言上下文检索过程分解为两个主要阶段:问题编码和答案检索。通过分析这两个阶段的性能和稳定性,来理解LLMs如何进行跨语言上下文检索,以及预训练和后训练分别在其中扮演的角色。这种分解有助于识别性能瓶颈和优化方向。
技术框架:整体框架包括以下几个主要步骤:1) 选择跨语言机器阅读理解(xMRC)作为评估场景。2) 选取40多个LLMs,覆盖开源和闭源模型。3) 在12种语言上进行xMRC任务评估。4) 分析模型在问题编码和答案检索两个阶段的表现。5) 研究预训练和后训练对这两个阶段的影响。6) 通过实验数据分析性能瓶颈和优化方向。
关键创新:论文的关键创新在于:1) 系统性地评估了大量LLMs的跨语言上下文检索能力。2) 将跨语言检索过程分解为问题编码和答案检索两个阶段,并分析了它们分别在预训练和后训练中的形成过程。3) 揭示了xMRC的性能瓶颈位于答案检索阶段的最后模型层,并证明了后训练对该阶段的显著影响。4) 发现更大规模的预训练不一定能提高xMRC性能,需要后训练来激发潜力。
关键设计:论文的关键设计包括:1) 使用TyDi QA数据集进行xMRC评估。2) 设计实验来评估问题编码和答案检索两个阶段的性能。3) 使用oracle性能评估来估计模型的理论上限。4) 分析不同模型层在两个阶段中的作用。5) 比较不同规模和训练方式的LLMs的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,经过后训练的开源LLM在跨语言机器阅读理解任务中表现出色,与GPT-4o等闭源模型相当。后训练显著提升了LLM的oracle性能,表明其具有更大的潜力。研究还发现,更大规模的预训练并不一定能提高xMRC性能,需要进一步的多语言后训练。
🎯 应用场景
该研究成果可应用于跨语言信息检索、多语言机器翻译、全球化客户服务、国际新闻分析等领域。通过提升LLM的跨语言上下文检索能力,可以更好地理解和利用不同语言的信息,促进跨文化交流和合作,并为全球用户提供更优质的服务。
📄 摘要(原文)
Cross-lingual context retrieval (extracting contextual information in one language based on requests in another) is a fundamental aspect of cross-lingual alignment, but the performance and mechanism of it for large language models (LLMs) remains unclear. In this paper, we evaluate the cross-lingual context retrieval of over 40 LLMs across 12 languages, using cross-lingual machine reading comprehension (xMRC) as a representative scenario. Our results show that post-trained open LLMs show strong cross-lingual context retrieval ability, comparable to closed-source LLMs such as GPT-4o, and their estimated oracle performances greatly improve after post-training. Our mechanism analysis shows that the cross-lingual context retrieval process can be divided into two main phases: question encoding and answer retrieval, which are formed in pre-training and post-training respectively. The phasing stability correlates with xMRC performance, and the xMRC bottleneck lies at the last model layers in the second phase, where the effect of post-training can be evidently observed. Our results also indicate that larger-scale pretraining cannot improve the xMRC performance. Instead, larger LLMs need further multilingual post-training to fully unlock their cross-lingual context retrieval potential.