Efficient Reasoning Models: A Survey
作者: Sicheng Feng, Gongfan Fang, Xinyin Ma, Xinchao Wang
分类: cs.CL, cs.AI
发布日期: 2025-04-15 (更新: 2025-09-29)
备注: TMLR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
综述高效推理模型,加速Chain-of-Thoughts范式在复杂逻辑任务中的应用。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 高效推理 思维链 模型压缩 知识蒸馏 解码策略 语言模型 计算效率
📋 核心要点
- 现有推理模型依赖冗长的思维链(CoT),导致计算开销巨大,限制了实际应用。
- 该综述从缩短CoT长度、减小模型尺寸和加速解码三个方面,系统性地回顾了高效推理的研究进展。
- 论文整理了大量相关文献,并开源了GitHub仓库,方便研究者快速了解该领域的研究现状。
📝 摘要(中文)
推理模型通过生成扩展的思维链(CoT)在解决复杂和逻辑密集型任务方面取得了显著进展,然而,这种“慢思考”模式由于顺序生成大量tokens,不可避免地带来了巨大的计算开销。因此,迫切需要有效的加速方法。本综述旨在全面概述高效推理的最新进展,将现有工作分为三个关键方向:(1)更短:将冗长的CoT压缩成简洁而有效的推理链;(2)更小:通过知识蒸馏、模型压缩和强化学习等技术,开发具有强大推理能力的紧凑型语言模型;(3)更快:设计高效的解码策略来加速推理模型的推断。本综述中讨论的论文集合可在GitHub存储库中找到:https://github.com/fscdc/Awesome-Efficient-Reasoning-Models。
🔬 方法详解
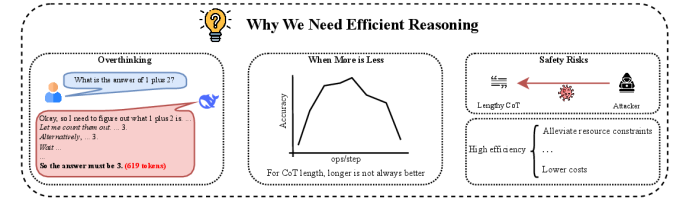
问题定义:论文旨在解决推理模型中由于生成过长的Chain-of-Thoughts (CoT) 而导致的计算效率低下问题。现有方法,虽然在复杂逻辑任务上表现出色,但其“慢思考”模式,即顺序生成大量tokens,造成了显著的计算负担,阻碍了其在资源受限环境下的应用。
核心思路:论文的核心思路是将现有研究分为三个主要方向,分别从缩短CoT长度、减小模型尺寸和加速解码过程入手,以提升推理效率。这种分类方式有助于研究者系统性地理解和比较不同的优化策略。
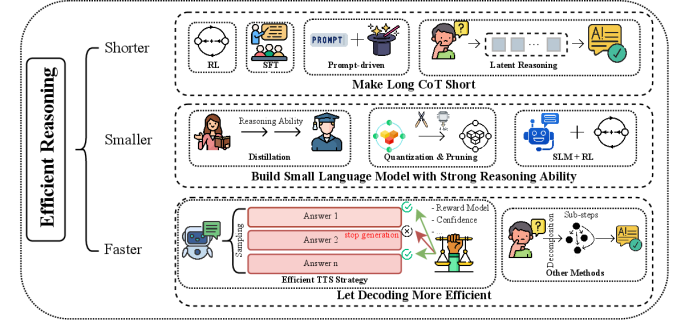
技术框架:该综述没有提出新的技术框架,而是对现有文献进行整理和分类。其整体框架围绕着“高效推理”这一主题,将相关研究划分为三个主要类别: 1. Shorter CoTs: 关注如何压缩CoT,使其在保持推理能力的同时减少token数量。 2. Smaller Models: 探索如何通过模型压缩技术(如知识蒸馏)构建更小但推理能力强的模型。 3. Faster Decoding: 研究如何设计更高效的解码算法,以加速推理过程。
关键创新:该综述的关键创新在于其系统性的分类和总结。它将大量关于高效推理的研究工作整合到一个统一的框架下,为研究者提供了一个清晰的路线图,方便他们了解该领域的研究现状和未来发展方向。此外,开源的GitHub仓库也方便了研究者获取相关资源。
关键设计:由于是综述文章,没有具体的参数设置、损失函数或网络结构等技术细节。其关键设计在于对现有文献的分类标准和组织方式,以及GitHub仓库的维护。
🖼️ 关键图片
📊 实验亮点
该综述整理了大量关于高效推理模型的论文,并将其分为三个主要方向:缩短CoT长度、减小模型尺寸和加速解码过程。通过对这些方法的总结和比较,为研究者提供了一个全面的视角,有助于他们了解该领域的研究现状和未来发展方向。开源的GitHub仓库也方便了研究者获取相关资源。
🎯 应用场景
该研究对开发低延迟、低功耗的推理系统具有重要意义。其潜在应用领域包括移动设备上的智能助手、边缘计算环境下的实时决策系统、以及资源受限的嵌入式设备。通过提升推理效率,可以使复杂的逻辑推理能力在更广泛的场景中得到应用。
📄 摘要(原文)
Reasoning models have demonstrated remarkable progress in solving complex and logic-intensive tasks by generating extended Chain-of-Thoughts (CoTs) prior to arriving at a final answer. Yet, the emergence of this "slow-thinking" paradigm, with numerous tokens generated in sequence, inevitably introduces substantial computational overhead. To this end, it highlights an urgent need for effective acceleration. This survey aims to provide a comprehensive overview of recent advances in efficient reasoning. It categorizes existing works into three key directions: (1) shorter - compressing lengthy CoTs into concise yet effective reasoning chains; (2) smaller - developing compact language models with strong reasoning capabilities through techniques such as knowledge distillation, other model compression techniques, and reinforcement learning; and (3) faster - designing efficient decoding strategies to accelerate inference of reasoning models. A curated collection of papers discussed in this survey is available in our GitHub repository: https://github.com/fscdc/Awesome-Efficient-Reasoning-Models.