HELIOS: Adaptive Model And Early-Exit Selection for Efficient LLM Inference Serving
作者: Avinash Kumar, Shashank Nag, Jason Clemons, Lizy John, Poulami Das
分类: cs.CL, cs.LG
发布日期: 2025-04-14 (更新: 2025-10-31)
💡 一句话要点
HELIOS:面向高效LLM推理服务的自适应模型与提前退出选择框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 提前退出 模型选择 高效推理 自适应模型加载
📋 核心要点
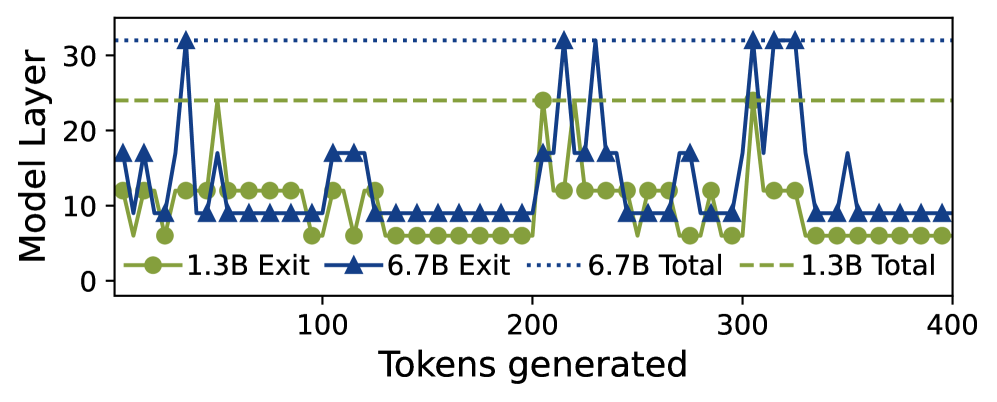
- 现有提前退出LLM框架依赖单一模型,未充分利用模型间的互补性,导致部分token延迟较高。
- HELIOS通过动态切换多个模型,并结合贪婪提前退出策略,最大化提前退出token数量,降低延迟。
- 实验结果表明,HELIOS显著提升了EE-LLM的吞吐量和batch size,优于现有框架。
📝 摘要(中文)
本文提出HELIOS框架,旨在提升提前退出的大语言模型(EE-LLM)的推理吞吐量。现有EE-LLM框架受限于单一模型,导致token生成延迟受制于未能提前退出的token。此外,提前退出仅在运行时可知,且依赖于请求,因此现有框架加载所有模型层的权重,即使大部分层在token提前退出时未被使用,内存利用率低,限制了batch size的扩展。HELIOS通过利用模型间的提前退出互补性,动态切换模型以最大化提前退出的token数量,并最小化token生成延迟。同时,HELIOS允许置信度较低但后续层输出不变的token提前退出,并仅加载最可能使用的层权重,节省内存以扩大batch size。HELIOS采用实时分析来准确识别提前退出分布,并自适应地切换模型,以最小化贪婪模型加载和退出带来的性能下降。实验表明,HELIOS相比现有EE-LLM框架,吞吐量提升1.48倍,batch size扩大15.14倍。
🔬 方法详解
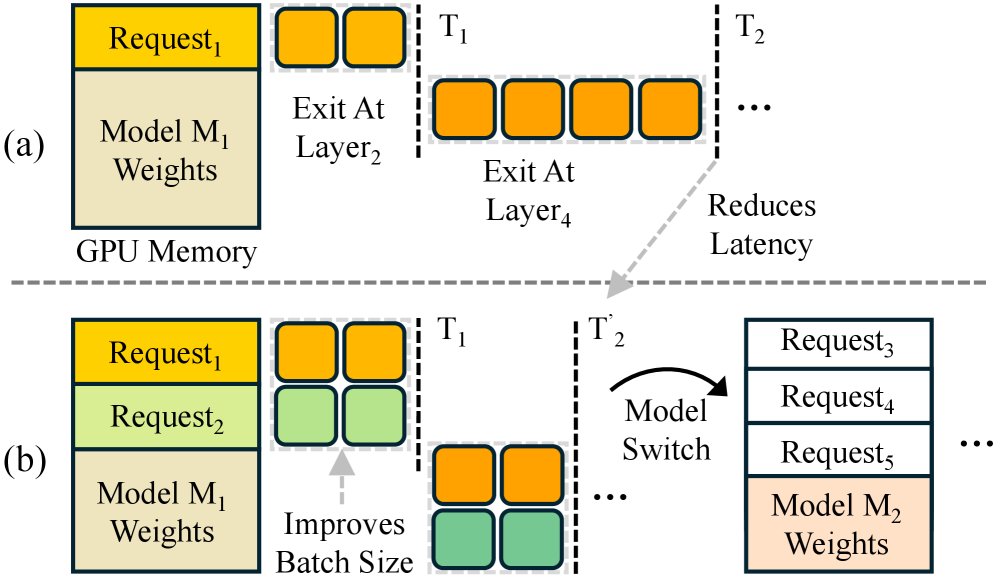
问题定义:现有提前退出大语言模型(EE-LLM)框架的推理效率受限于两个主要问题:一是单一模型无法充分利用所有token的提前退出机会,导致部分token需要经过更多层计算,增加了延迟;二是即使token可以提前退出,框架仍然需要加载所有模型层的权重,造成内存浪费,限制了batch size的扩展。因此,如何充分利用模型间的互补性,并减少不必要的内存占用,是提升EE-LLM推理效率的关键挑战。
核心思路:HELIOS的核心思路是利用多个EE-LLM模型之间的互补性,以及token在不同层之间的输出稳定性。具体来说,HELIOS首先维护一个模型池,并根据token的特性动态地选择最合适的模型进行推理,从而最大化提前退出的token数量。其次,HELIOS采用一种贪婪的提前退出策略,允许置信度较低但后续层输出不变的token提前退出,并只加载最可能被使用的模型层权重,从而节省内存。
技术框架:HELIOS框架主要包含以下几个模块:1) 模型池:存储多个EE-LLM模型,这些模型可能具有不同的结构或训练数据,从而提供不同的提前退出特性。2) 实时分析器:实时监控token的提前退出分布,并根据历史数据预测不同模型在不同token上的提前退出概率。3) 模型选择器:根据实时分析器的预测结果,动态地选择最合适的模型进行推理。4) 贪婪提前退出模块:允许置信度较低但后续层输出不变的token提前退出,并只加载最可能被使用的模型层权重。5) 自适应模型加载器:根据模型选择器的决策,动态地加载和卸载模型层权重,从而节省内存。
关键创新:HELIOS的关键创新在于:1) 动态模型切换:通过实时分析和模型选择,充分利用了模型间的互补性,最大化了提前退出的token数量。2) 贪婪提前退出:允许置信度较低但后续层输出不变的token提前退出,进一步降低了延迟。3) 自适应模型加载:只加载最可能被使用的模型层权重,节省了内存,从而可以扩大batch size。与现有方法相比,HELIOS能够更有效地利用计算资源和内存资源,从而显著提升EE-LLM的推理效率。
关键设计:HELIOS的关键设计包括:1) 模型选择策略:采用基于概率的策略,根据实时分析器的预测结果,选择提前退出概率最高的模型。2) 贪婪提前退出阈值:需要仔细调整置信度阈值,以避免过早退出导致精度下降。3) 模型层权重加载策略:采用基于预测的策略,只加载最可能被使用的模型层权重,并根据实际情况动态调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,HELIOS相比于现有的EE-LLM框架,在吞吐量上提升了1.48倍,同时batch size扩大了15.14倍。这些显著的性能提升表明HELIOS能够更有效地利用计算资源和内存资源,从而实现更高的推理效率。这些结果验证了HELIOS框架的有效性和优越性。
🎯 应用场景
HELIOS框架可应用于各种需要高效LLM推理服务的场景,例如在线问答系统、对话机器人、文本摘要等。通过提高吞吐量和降低延迟,HELIOS可以显著提升用户体验,并降低服务成本。未来,HELIOS可以进一步扩展到支持更多类型的LLM模型和硬件平台,并与其他优化技术相结合,以实现更高的推理效率。
📄 摘要(原文)
Early-Exit Large Language Models (EE-LLMs) enable high throughput inference by allowing tokens to exit early at intermediate layers. However, their throughput is limited by the computational and memory savings. Existing EE-LLM frameworks rely on a single model and therefore, their token generation latencies are bottlenecked by tokens that do not exit early and traverse additional layers. Moreover, early exits are only known at runtime and depend on the request. Therefore, these frameworks load the weights of all model layers even though large portions remain unused when tokens exit early. The lack of memory savings limit us from scaling the batch sizes. We propose $\textit{HELIOS}$, a framework that improves both token generation latency and batch sizes to enable high-throughput in EE-LLMs. HELIOS exploits two insights. $\textit{First}$, early exits are often complimentary across models, tokens that do not exit early on one model often take an early-exit on another. HELIOS employs multiple models and dynamically switches between them to collectively maximize the number of tokens that exit early, and minimize token generation latencies. $\textit{Second}$, even when a predicted token does not exit early due to poor confidence, it often remains unchanged even after additional layer traversal. HELIOS greedily allows such tokens to exit early and only loads the weights of the most likely to be used layers, yielding memory savings which is then re-purposed to increase batch sizes. HELIOS employs real-time profiling to accurately identify the early-exit distributions, and adaptively switches between models by tracking tokens in real-time to minimize the performance degradation caused by greedy model loading and exiting. Our evaluations show that HELIOS achieves $1.48\times$ higher throughput and $15.14\times$ larger batch size compared to existing EE-LLM frameworks.