Better Estimation of the Kullback--Leibler Divergence Between Language Models
作者: Afra Amini, Tim Vieira, Ryan Cotterell
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-04-14 (更新: 2025-10-25)
备注: NeurIPS 2025
💡 一句话要点
提出Rao-Blackwellized估计器,更稳定地估计语言模型间的KL散度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: KL散度估计 语言模型 Rao-Blackwellization 方差缩减 强化学习 情感控制微调 蒙特卡洛方法
📋 核心要点
- 现有基于蒙特卡洛的KL散度估计器方差高,可能导致负值估计,影响模型训练。
- 提出Rao-Blackwellized估计器,利用条件期望降低方差,提供更稳定的KL散度估计。
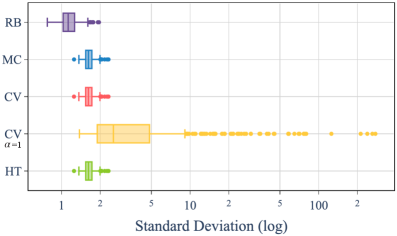
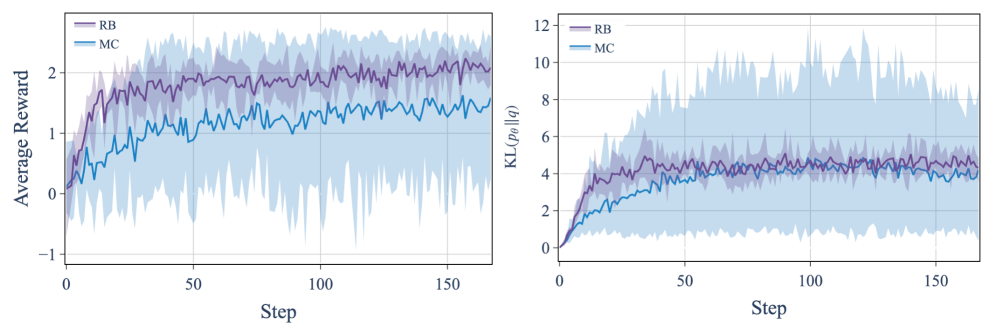
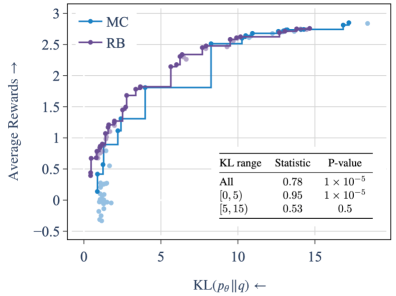
- 实验证明,该估计器能显著降低方差,并使模型在奖励与KL散度的帕累托前沿上表现更佳。
📝 摘要(中文)
本文针对语言模型间 Kullback-Leibler (KL) 散度难以精确计算的问题,提出了一种改进的估计方法。KL散度在强化学习(如基于人类反馈的强化学习RLHF)、可解释性和知识蒸馏等领域有广泛应用。由于精确计算的不可行性,通常采用基于采样的估计器。虽然蒙特卡洛(MC)估计器可以提供KL散度的无偏估计,但其方差过高,甚至可能产生负值的KL散度估计(KL散度应为非负)。本文提出了一种Rao-Blackwellized估计器,该估计器是无偏的,并且理论上证明其方差小于或等于标准蒙特卡洛估计器。在情感控制微调的实验研究中,结果表明该估计器提供了更稳定的KL估计,并显著降低了方差。此外,本文还推导出了KL散度梯度的类似Rao-Blackwellized估计器,从而实现了更稳定的训练,并产生了在奖励与KL散度帕累托前沿上更频繁出现的模型,优于使用MC估计器训练的模型。
🔬 方法详解
问题定义:论文旨在解决语言模型间KL散度估计不准确的问题。现有的蒙特卡洛(MC)估计器虽然是无偏的,但其方差过高,导致估计结果不稳定,甚至可能出现负值,这与KL散度的非负性质相悖。这种不准确的估计会影响下游任务,如强化学习中的奖励函数设计和知识蒸馏中的模型对齐。
核心思路:论文的核心思路是利用Rao-Blackwellization技术来降低KL散度估计的方差。Rao-Blackwellization是一种统计方法,通过计算条件期望来降低估计量的方差。具体来说,就是找到一个与目标变量相关的统计量,并计算在给定该统计量下的条件期望,以此作为新的估计量。由于条件期望的方差小于等于原变量的方差,因此可以有效降低估计的方差。
技术框架:整体框架包括以下几个步骤:1) 使用两个语言模型生成样本;2) 使用蒙特卡洛方法计算KL散度的初始估计;3) 应用Rao-Blackwellization技术,计算条件期望,得到新的KL散度估计;4) (可选) 使用Rao-Blackwellized的KL散度梯度进行模型训练。论文同时推导了KL散度及其梯度的Rao-Blackwellized估计器。
关键创新:最重要的技术创新在于将Rao-Blackwellization技术应用于语言模型KL散度的估计。与传统的蒙特卡洛估计器相比,Rao-Blackwellized估计器在理论上具有更低的方差,从而能够提供更稳定和可靠的KL散度估计。此外,论文还推导了KL散度梯度的Rao-Blackwellized估计器,这使得在训练过程中能够更准确地优化模型。
关键设计:论文的关键设计在于如何选择合适的统计量进行条件期望的计算。具体的技术细节取决于所使用的语言模型和采样方法。论文中可能涉及到特定的参数设置,例如采样数量、模型架构等,这些都会影响最终的估计效果。损失函数方面,如果使用KL散度进行正则化或优化,则会使用Rao-Blackwellized的KL散度或其梯度。
🖼️ 关键图片
📊 实验亮点
实验结果表明,提出的Rao-Blackwellized估计器在情感控制微调任务中,能够提供更稳定的KL散度估计,并显著降低方差。与使用蒙特卡洛估计器训练的模型相比,使用Rao-Blackwellized估计器训练的模型更频繁地出现在奖励与KL散度的帕累托前沿上,表明该方法能够更好地平衡奖励和模型分布的变化。
🎯 应用场景
该研究成果可广泛应用于自然语言处理领域,例如:1) 强化学习:在基于人类反馈的强化学习(RLHF)中,更准确的KL散度估计可以帮助更好地平衡奖励和模型分布的变化。2) 可解释性:KL散度可以用于衡量不同模型之间的差异,从而帮助理解模型的行为。3) 知识蒸馏:更准确的KL散度估计可以提高知识蒸馏的效果,使学生模型更好地学习教师模型的知识。
📄 摘要(原文)
Estimating the Kullback--Leibler (KL) divergence between language models has many applications, e.g., reinforcement learning from human feedback (RLHF), interpretability, and knowledge distillation. However, computing the exact KL divergence between two arbitrary language models is intractable. Thus, practitioners often resort to sampling-based estimators. While it is easy to fashion a simple Monte Carlo (MC) estimator that provides an unbiased estimate of the KL divergence between language models, this estimator notoriously suffers from high variance and can even result in a negative estimate of the KL divergence, a non-negative quantity. In this paper, we introduce a Rao--Blackwellized estimator that is unbiased and provably has variance less than or equal to that of the standard Monte Carlo estimator. In an empirical study on sentiment-controlled fine-tuning, we show that our estimator provides more stable KL estimates and reduces variance substantially. Additionally, we derive an analogous Rao--Blackwellized estimator of the gradient of the KL divergence, which leads to more stable training and produces models that more frequently appear on the Pareto frontier of reward vs. KL compared to the ones trained with the MC estimator of the gradient.