LLM-SRBench: A New Benchmark for Scientific Equation Discovery with Large Language Models
作者: Parshin Shojaee, Ngoc-Hieu Nguyen, Kazem Meidani, Amir Barati Farimani, Khoa D Doan, Chandan K Reddy
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-04-14 (更新: 2025-06-07)
备注: ICML 2025 Oral. Project page: https://github.com/deep-symbolic-mathematics/llm-srbench , Benchmark page: https://huggingface.co/datasets/nnheui/llm-srbench
💡 一句话要点
提出LLM-SRBench以解决科学方程发现评估问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 科学方程发现 大型语言模型 基准测试 推理能力 数据驱动
📋 核心要点
- 现有方法在科学方程发现中面临评估困难,常见方程易被LLMs记忆,导致性能虚高。
- 本文提出LLM-SRBench基准,设计239个问题,分为LSR-Transform和LSR-Synth,旨在测试LLMs的推理能力。
- 实验结果显示,当前最佳系统的符号准确率仅为31.5%,揭示了科学方程发现的复杂性和挑战。
📝 摘要(中文)
科学方程发现是科学进步中的一项基础任务,能够推导自然现象的规律。近年来,因其潜力,基于大型语言模型(LLMs)的方程发现受到关注。然而,现有基准往往依赖于常见方程,导致LLMs可能通过记忆而非真正发现来提高性能。为此,本文提出了LLM-SRBench,一个包含239个具有挑战性问题的综合基准,旨在评估LLM在科学方程发现中的能力。该基准分为两大类:LSR-Transform和LSR-Synth,前者测试推理能力,后者引入合成问题以促进数据驱动的推理。通过对多种先进方法的评估,发现最佳系统的符号准确率仅为31.5%,突显了科学方程发现的挑战。
🔬 方法详解
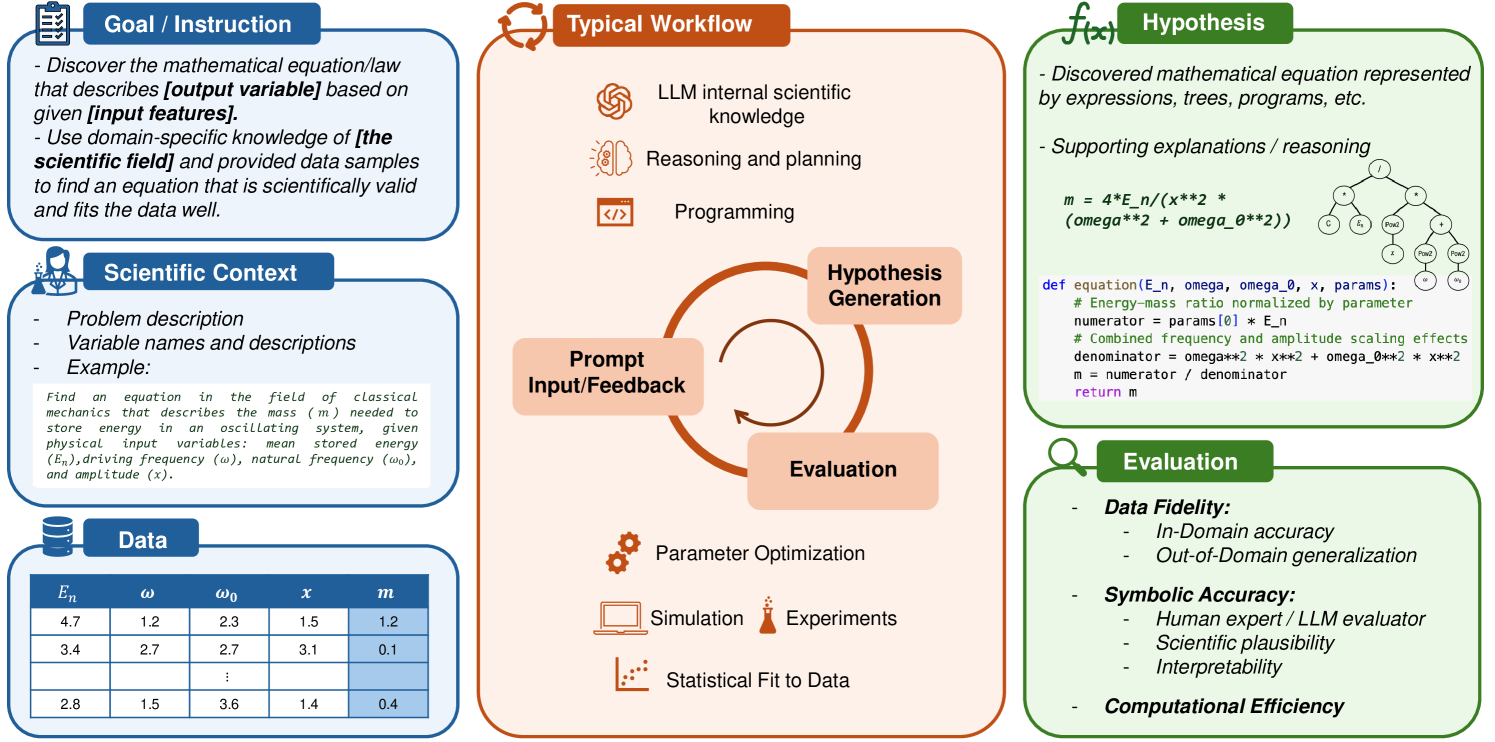
问题定义:本文旨在解决科学方程发现的评估问题,现有方法常依赖于易于记忆的方程,导致性能评估不准确。
核心思路:提出LLM-SRBench基准,通过设计具有挑战性的科学问题,避免LLMs通过记忆获得虚高的性能,真正考察其推理能力。
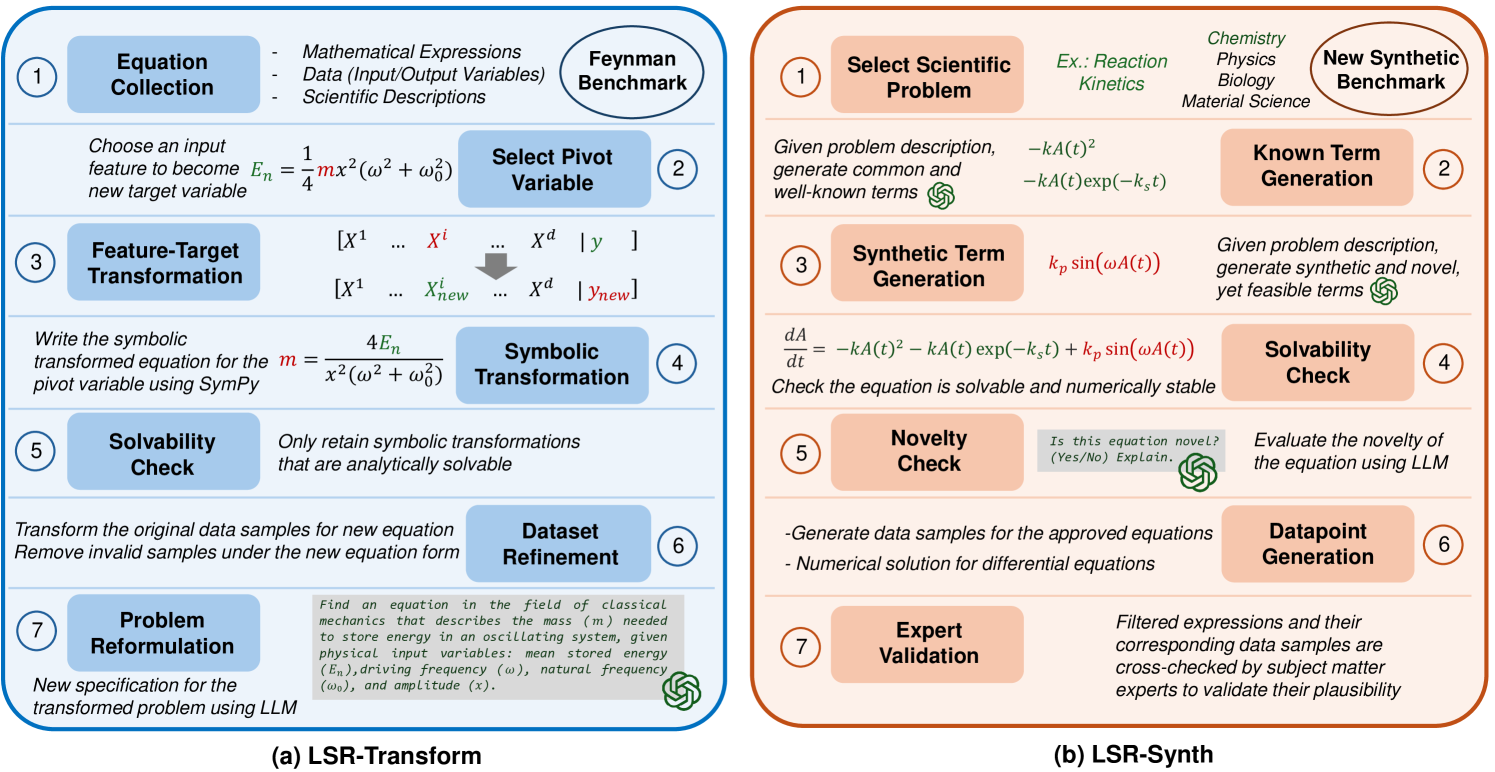
技术框架:LLM-SRBench包含两个主要模块:LSR-Transform将常见物理模型转化为不常见的数学表示,LSR-Synth引入合成问题,要求数据驱动的推理。
关键创新:LLM-SRBench的创新在于其设计的239个问题,能够有效防止记忆效应,真正考察LLMs的科学方程发现能力。
关键设计:在实验中,使用了多种先进的LLM,包括开放和封闭模型,评估过程中关注符号准确率等指标,确保评估的全面性和准确性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,当前最佳的LLM系统在LLM-SRBench基准上的符号准确率仅为31.5%,显示出科学方程发现的复杂性和挑战性,为后续研究提供了重要的参考。
🎯 应用场景
该研究的潜在应用领域包括科学研究、教育和工程等,能够帮助研究人员更好地理解和发现自然规律。LLM-SRBench为未来的研究提供了一个重要的评估工具,推动科学方程发现的进步。
📄 摘要(原文)
Scientific equation discovery is a fundamental task in the history of scientific progress, enabling the derivation of laws governing natural phenomena. Recently, Large Language Models (LLMs) have gained interest for this task due to their potential to leverage embedded scientific knowledge for hypothesis generation. However, evaluating the true discovery capabilities of these methods remains challenging, as existing benchmarks often rely on common equations that are susceptible to memorization by LLMs, leading to inflated performance metrics that do not reflect discovery. In this paper, we introduce LLM-SRBench, a comprehensive benchmark with 239 challenging problems across four scientific domains specifically designed to evaluate LLM-based scientific equation discovery methods while preventing trivial memorization. Our benchmark comprises two main categories: LSR-Transform, which transforms common physical models into less common mathematical representations to test reasoning beyond memorized forms, and LSR-Synth, which introduces synthetic, discovery-driven problems requiring data-driven reasoning. Through extensive evaluation of several state-of-the-art methods, using both open and closed LLMs, we find that the best-performing system so far achieves only 31.5% symbolic accuracy. These findings highlight the challenges of scientific equation discovery, positioning LLM-SRBench as a valuable resource for future research.