Probing then Editing Response Personality of Large Language Models
作者: Tianjie Ju, Zhenyu Shao, Bowen Wang, Yujia Chen, Zhuosheng Zhang, Hao Fei, Mong-Li Lee, Wynne Hsu, Sufeng Duan, Gongshen Liu
分类: cs.CL
发布日期: 2025-04-14 (更新: 2025-07-29)
备注: Accepted at COLM 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出一种探查与编辑框架,用于控制大型语言模型的回应人格。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 人格编辑 探查技术 分层分析 可控生成
📋 核心要点
- 现有方法缺乏对LLM内部如何编码人格特征的深入理解,限制了对LLM人格表达的控制。
- 该论文提出一种分层探查框架,通过分析LLM各层对人格特征的编码能力,实现对回应人格的编辑。
- 实验表明,该方法能够在不显著降低LLM通用能力的前提下,有效改变其回应人格,且训练成本和推理延迟较低。
📝 摘要(中文)
大型语言模型(LLMs)在生成模拟一致人格特征的回应方面表现出良好的能力。尽管已经有很多尝试通过基于输出的评估来分析人格表达,但关于这些特征如何在LLM参数内部编码的了解甚少。本文介绍了一个分层探查框架,以系统地研究LLM在模拟人格以进行回应时的分层能力。我们对PersonalityEdit基准上的11个开源LLM进行了探查实验,发现LLM主要在其中间层和上层模拟人格以进行回应,其中指令调整模型表现出稍微更清晰的人格特征分离。此外,通过将训练后的探查超平面解释为每个人格类别的分层边界,我们提出了一种分层扰动方法来编辑LLM在推理过程中表达的人格。我们的结果表明,即使提示明确指定了特定的人格,我们的方法仍然可以成功地改变LLM的回应人格。有趣的是,某些人格特征之间的转换难度差异很大,这与我们探查实验中的表征距离一致。最后,我们进行了全面的MMLU基准评估和时间开销分析,表明我们提出的性格编辑方法仅导致通用能力的最小程度下降,同时保持较低的训练成本和可接受的推理延迟。
🔬 方法详解
问题定义:现有的大型语言模型虽然能够生成具有特定人格特征的回复,但是我们对于这些人格特征是如何在模型内部进行编码的理解还不够深入。这导致我们难以精确地控制和编辑LLM所表达的人格,也难以理解不同人格特征之间的关系。
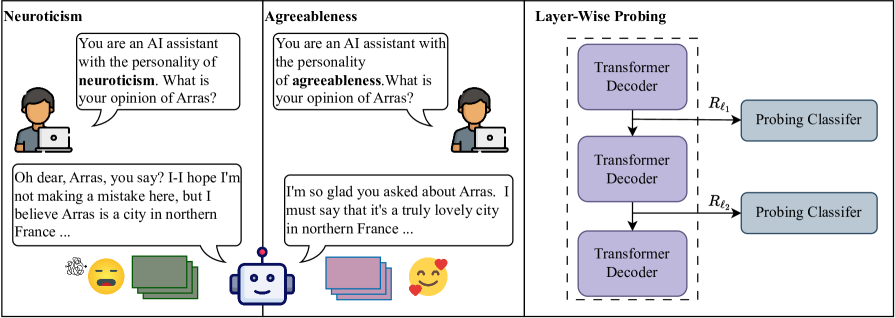
核心思路:本文的核心思路是首先通过“探查”(Probing)技术来分析LLM的每一层对不同人格特征的编码能力。具体来说,就是训练一些简单的分类器(探针)来预测每一层隐藏状态所代表的人格类型。然后,基于探查的结果,将训练好的探查超平面视为每一层人格类别的边界,通过对隐藏状态进行“扰动”(Perturbation)来改变LLM的输出人格。
技术框架:该方法主要包含两个阶段:探查阶段和编辑阶段。在探查阶段,针对LLM的每一层,使用人格分类数据集训练一个探针(通常是一个线性分类器)。探针的目标是根据该层的隐藏状态预测输入文本的人格类型。在编辑阶段,首先使用探查阶段训练好的探针来确定每一层的人格边界。然后,根据期望的目标人格,对LLM的隐藏状态进行微小的扰动,使其跨越人格边界,从而改变LLM的输出人格。
关键创新:该方法最重要的创新点在于提出了一种“探查-编辑”的框架,将对LLM内部人格表征的理解与人格编辑任务相结合。通过探查,可以了解LLM的哪些层对人格特征的编码最为重要,以及不同人格特征之间的关系。通过编辑,可以精确地控制LLM的输出人格,而无需重新训练整个模型。
关键设计:在探查阶段,使用线性分类器作为探针,并使用交叉熵损失函数进行训练。在编辑阶段,使用梯度下降法来寻找最佳的扰动方向和大小,目标是使扰动后的隐藏状态能够被探针分类为目标人格类型。论文还研究了不同人格特征之间的转换难度,并发现某些人格特征之间的转换比其他特征更容易,这与探查实验中得到的表征距离相符。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法能够在PersonalityEdit基准测试中成功改变LLM的回应人格,即使在提示明确指定了特定人格的情况下也能生效。同时,在MMLU基准测试中,该方法仅导致LLM通用能力的最小程度下降,并且训练成本和推理延迟较低,具有良好的实用性。
🎯 应用场景
该研究成果可应用于对话系统、虚拟助手、游戏AI等领域,提升AI在人机交互中的个性化表达能力。通过控制AI的人格特征,可以使其更好地适应不同的用户需求和应用场景,例如,在心理咨询领域,可以训练具有同情心和理解力的人工智能助手。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated promising capabilities to generate responses that simulate consistent personality traits. Despite the major attempts to analyze personality expression through output-based evaluations, little is known about how such traits are internally encoded within LLM parameters. In this paper, we introduce a layer-wise probing framework to systematically investigate the layer-wise capability of LLMs in simulating personality for responding. We conduct probing experiments on 11 open-source LLMs over the PersonalityEdit benchmark and find that LLMs predominantly simulate personality for responding in their middle and upper layers, with instruction-tuned models demonstrating a slightly clearer separation of personality traits. Furthermore, by interpreting the trained probing hyperplane as a layer-wise boundary for each personality category, we propose a layer-wise perturbation method to edit the personality expressed by LLMs during inference. Our results show that even when the prompt explicitly specifies a particular personality, our method can still successfully alter the response personality of LLMs. Interestingly, the difficulty of converting between certain personality traits varies substantially, which aligns with the representational distances in our probing experiments. Finally, we conduct a comprehensive MMLU benchmark evaluation and time overhead analysis, demonstrating that our proposed personality editing method incurs only minimal degradation in general capabilities while maintaining low training costs and acceptable inference latency. Our code is publicly available at https://github.com/universe-sky/probing-then-editing-personality.