DataPuzzle: Breaking Free from the Hallucinated Promise of LLMs in Data Analysis
作者: Zhengxuan Zhang, Zhuowen Liang, Yin Wu, Teng Lin, Yuyu Luo, Nan Tang
分类: cs.CL
发布日期: 2025-04-14 (更新: 2025-09-28)
💡 一句话要点
DataPuzzle:提出多智能体框架,解决LLM在数据分析中幻觉问题,提升可信度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多智能体系统 数据分析 可解释性 可验证性
📋 核心要点
- 现有LLM在数据分析中采用“提示到答案”模式,将推理过程隐藏,导致结果不可靠、难以验证,存在幻觉问题。
- DataPuzzle提出多智能体框架,将复杂问题分解,结构化信息,协调智能体角色,实现透明可验证的分析流程。
- DataPuzzle旨在将LLM从黑盒预言机转变为可协作的智能体,专注于提取、翻译和链接等特定任务,提升分析系统的可信度。
📝 摘要(中文)
大型语言模型(LLM)越来越多地应用于多模态数据分析,这并非因为它们能提供最精确的答案,而是因为它们为解释复杂输入提供了流畅、灵活的界面。然而,这种流畅性常常掩盖了更深层次的结构性缺陷:流行的“提示到答案”范式将LLM视为黑盒分析师,将证据、推理和结论压缩成一个单一、不透明的响应。这导致结果脆弱、不可验证且经常具有误导性。我们主张进行根本性的转变:从生成到结构化提取,从单一提示到模块化、基于代理的工作流程。LLM不应充当预言机,而应充当协作器——专门从事提取、翻译和链接等任务——嵌入到透明的工作流程中,从而实现逐步推理和验证。我们提出了DataPuzzle,一个概念性的多智能体框架,它分解复杂的问题,将信息结构化为可解释的形式(例如,表格、图),并协调智能体的角色以支持透明和可验证的分析。该框架为在LLM驱动的分析中恢复可见性和控制提供了一个理想的蓝图——将不透明的答案转化为可追溯的过程,并将脆弱的流畅性转化为可问责的洞察力。这不是一个边缘的改进;而是一个呼吁,即重新构想我们如何在大型语言模型的时代构建可信、可审计的分析系统。结构不是约束,而是通往清晰的道路。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在多模态数据分析中存在的“黑盒”问题。现有的“提示到答案”范式将LLM视为黑盒分析器,直接生成结论,缺乏透明的推理过程,导致结果脆弱、不可验证,容易产生幻觉。这种方式阻碍了用户对LLM分析结果的信任和有效利用。
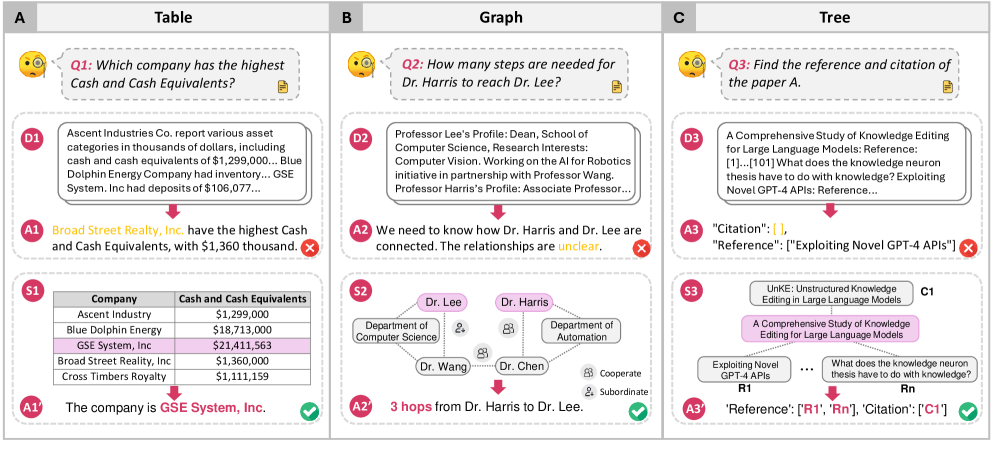
核心思路:论文的核心思路是将复杂的分析任务分解为多个可管理的子任务,并分配给不同的智能体(Agent)执行。每个智能体负责特定的任务,例如数据提取、信息翻译、关系链接等。通过智能体之间的协作,构建一个透明、可追溯的分析流程,从而提高结果的可信度和可解释性。
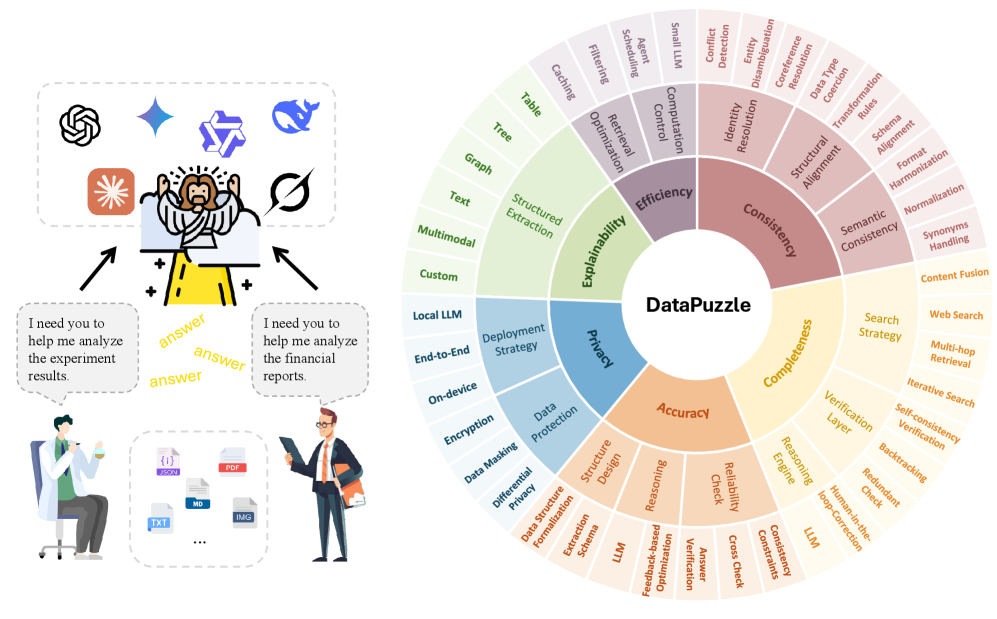
技术框架:DataPuzzle框架包含以下主要模块:1) 问题分解模块:将复杂问题分解为多个子问题。2) 智能体分配模块:为每个子问题分配合适的智能体。3) 智能体执行模块:每个智能体执行其分配的任务,并生成结构化的中间结果(例如,表格、图)。4) 结果整合模块:将各个智能体的结果整合起来,生成最终的分析结果。5) 验证模块:对分析结果进行验证,确保其准确性和可靠性。
关键创新:DataPuzzle的关键创新在于将LLM从一个黑盒的“预言机”转变为一个可协作的“智能体”。通过多智能体的协作,构建一个透明、可追溯的分析流程。这种方法与现有的“提示到答案”范式有着本质的区别,它强调过程的可解释性和结果的可验证性。
关键设计:DataPuzzle框架的具体实现细节(例如,智能体的类型、智能体之间的通信协议、结果整合算法等)取决于具体的应用场景。论文中并未提供具体的参数设置、损失函数或网络结构等技术细节,这些需要根据实际情况进行设计和调整。框架的关键在于模块化和可扩展性,以便适应不同的分析任务和数据类型。
🖼️ 关键图片
📊 实验亮点
论文提出了DataPuzzle框架,但摘要中没有明确提及具体的实验结果或性能数据。因此,无法总结实验亮点。论文主要贡献在于提出了一个概念性的框架,并阐述了其潜在的优势和应用前景。未来的工作需要通过实验验证DataPuzzle框架的有效性。
🎯 应用场景
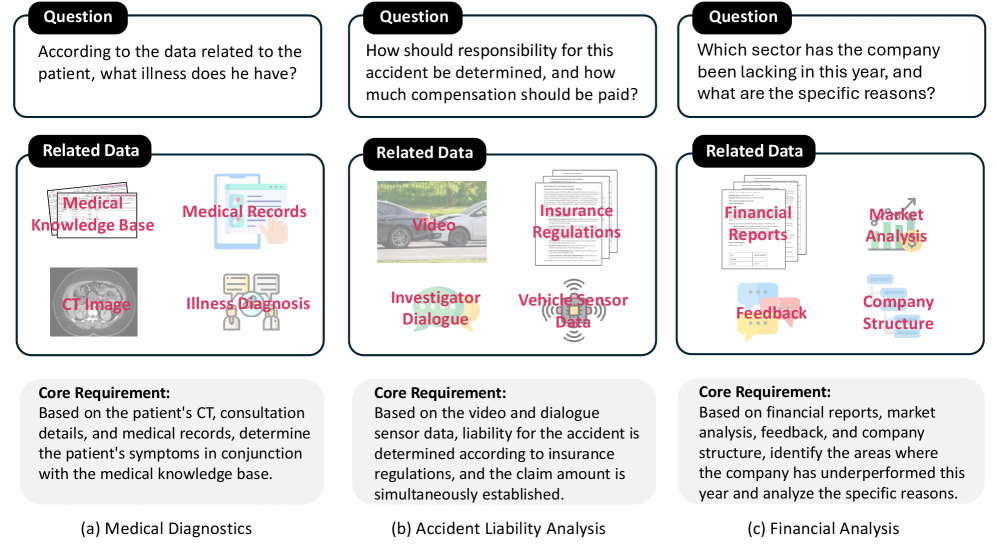
DataPuzzle框架可应用于各种需要可信数据分析的领域,例如金融风险评估、医疗诊断、市场趋势分析等。通过提供透明、可验证的分析流程,DataPuzzle可以帮助用户更好地理解数据,做出更明智的决策。未来,该框架有望成为构建可信AI系统的基础组件。
📄 摘要(原文)
Large language models (LLMs) are increasingly applied to multi-modal data analysis -- not necessarily because they offer the most precise answers, but because they provide fluent, flexible interfaces for interpreting complex inputs. Yet this fluency often conceals a deeper structural failure: the prevailing ``Prompt-to-Answer'' paradigm treats LLMs as black-box analysts, collapsing evidence, reasoning, and conclusions into a single, opaque response. The result is brittle, unverifiable, and frequently misleading. We argue for a fundamental shift: from generation to structured extraction, from monolithic prompts to modular, agent-based workflows. LLMs should not serve as oracles, but as collaborators -- specialized in tasks like extraction, translation, and linkage -- embedded within transparent workflows that enable step-by-step reasoning and verification. We propose DataPuzzle, a conceptual multi-agent framework that decomposes complex questions, structures information into interpretable forms (e.g. tables, graphs), and coordinates agent roles to support transparent and verifiable analysis. This framework serves as an aspirational blueprint for restoring visibility and control in LLM-driven analytics -- transforming opaque answers into traceable processes, and brittle fluency into accountable insight. This is not a marginal refinement; it is a call to reimagine how we build trustworthy, auditable analytic systems in the era of large language models. Structure is not a constraint -- it is the path to clarity.