The Mirage of Performance Gains: Why Contrastive Decoding Fails to Mitigate Object Hallucinations in MLLMs?
作者: Hao Yin, Guangzong Si, Zilei Wang
分类: cs.CL, cs.AI, cs.CV
发布日期: 2025-04-14 (更新: 2025-10-07)
💡 一句话要点
揭示对比解码的局限性:无法有效缓解多模态大语言模型中的对象幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 对象幻觉 对比解码 性能评估 虚假改进
📋 核心要点
- 多模态大语言模型(MLLM)存在对象幻觉问题,现有对比解码方法试图通过对比学习抑制幻觉,但效果不佳。
- 该论文的核心思想是揭示现有对比解码方法在缓解对象幻觉方面的无效性,并指出其性能提升是虚假的。
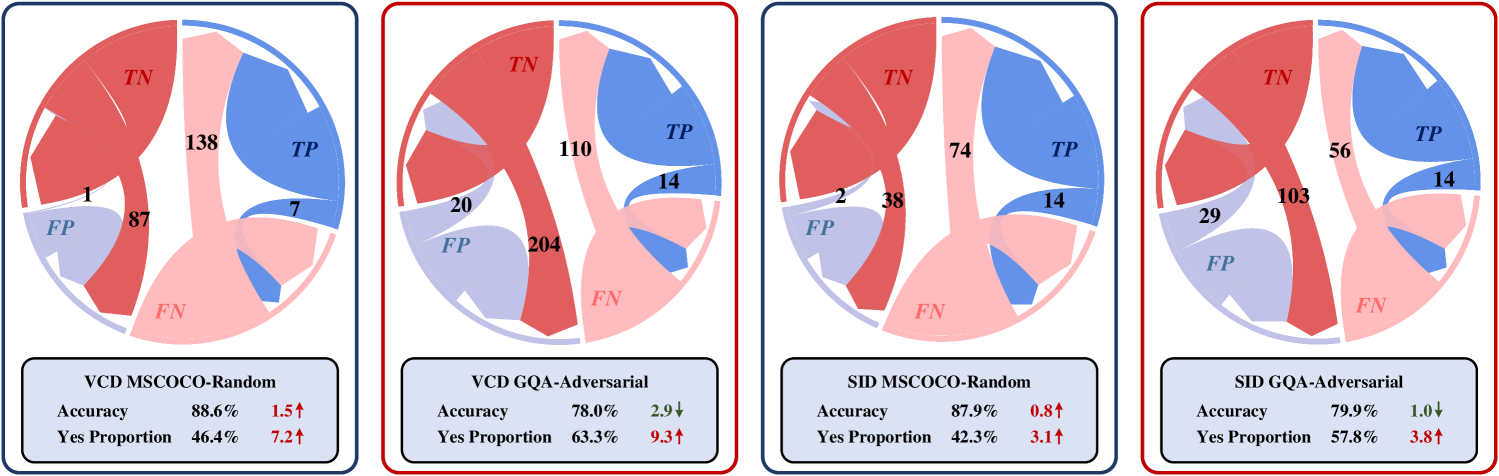
- 实验表明,对比解码在POPE基准上的性能提升并非源于缓解幻觉,而是由于其他因素导致的,例如贪婪搜索。
📝 摘要(中文)
对比解码策略被广泛应用于减少多模态大语言模型(MLLM)中的对象幻觉。这些方法通过构建对比样本来诱导幻觉,然后在输出分布中抑制它们。然而,本文证明了这种方法未能有效缓解幻觉问题。在POPE基准测试中观察到的性能提升主要由两个误导性因素驱动:(1)对模型输出分布的粗略、单向调整;(2)自适应合理性约束,它将采样策略简化为贪婪搜索。为了进一步说明这些问题,我们引入了一系列虚假的改进方法,并评估了它们相对于对比解码技术的性能。实验结果表明,对比解码中观察到的性能提升与其旨在缓解幻觉的初衷完全无关。我们的发现挑战了关于对比解码策略有效性的常见假设,并为开发真正有效的MLLM幻觉解决方案铺平了道路。
🔬 方法详解
问题定义:多模态大语言模型(MLLM)在生成文本时,会产生与图像内容不符的对象幻觉。现有的对比解码方法试图通过构建对比样本并抑制幻觉来解决这个问题,但实际效果并不理想,其性能提升的真正原因尚不明确。
核心思路:该论文的核心思路是质疑现有对比解码方法缓解对象幻觉的有效性。通过分析对比解码的机制,指出其性能提升并非源于缓解幻觉,而是由于对输出分布的粗略调整以及将采样策略简化为贪婪搜索。
技术框架:该论文没有提出新的技术框架,而是对现有对比解码方法进行了深入的分析和实验验证。主要通过设计一系列虚假的改进方法,并与对比解码进行对比实验,来揭示对比解码的局限性。
关键创新:该论文的关键创新在于揭示了对比解码在缓解MLLM对象幻觉方面的无效性,并指出了其性能提升的虚假性。这挑战了领域内的普遍认知,为未来研究方向提供了新的视角。
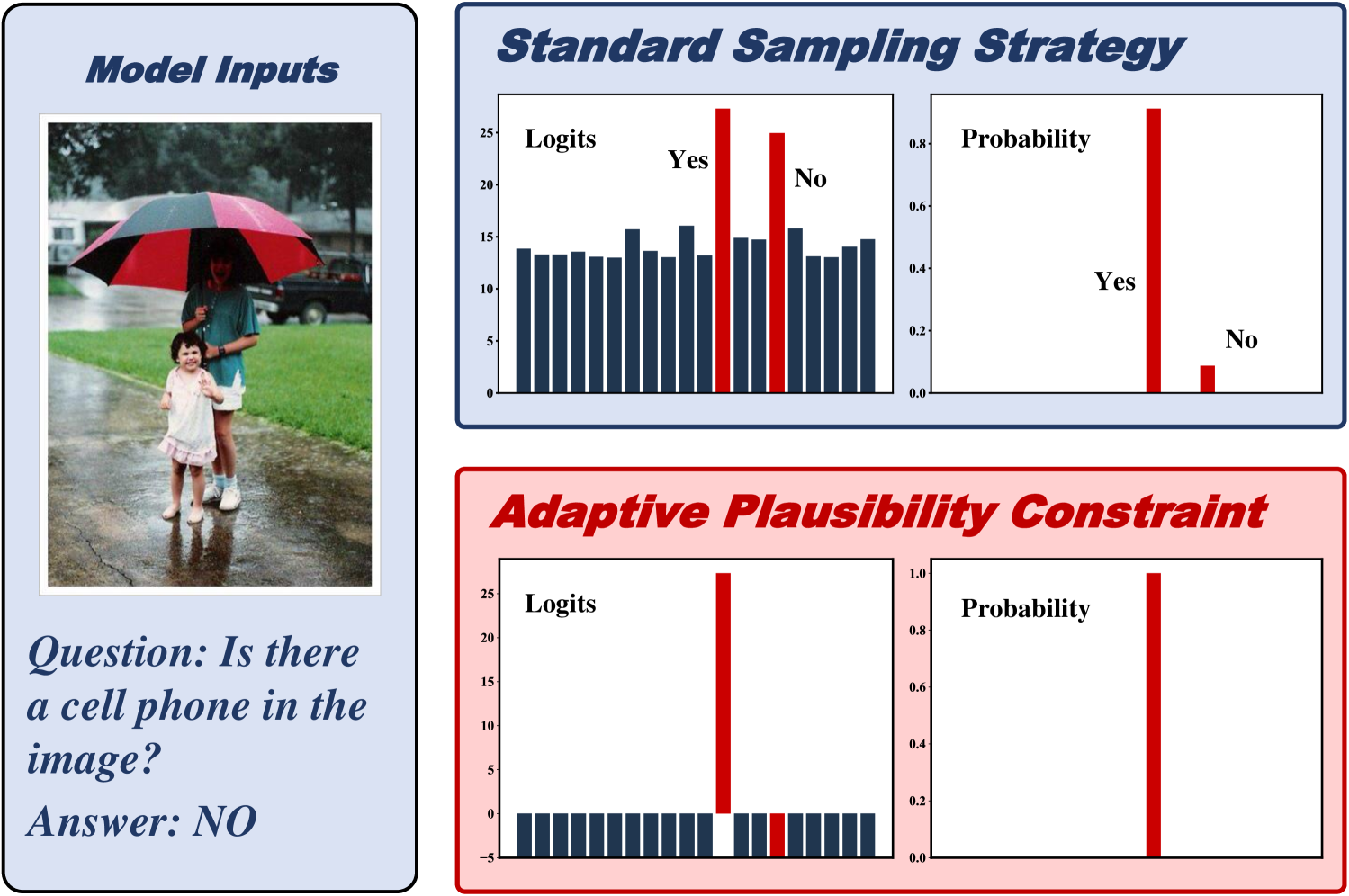
关键设计:论文的关键设计在于构建了一系列“虚假的改进方法”,这些方法在设计上与缓解幻觉无关,但却能在POPE基准上取得与对比解码相似甚至更好的性能。这些方法包括:对输出分布进行单向调整,以及采用自适应合理性约束(本质上是贪婪搜索)。通过对比这些方法的表现,论文证明了对比解码的性能提升并非源于其缓解幻觉的能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,对比解码在POPE基准测试中观察到的性能提升,与缓解对象幻觉的目标无关。通过引入一系列虚假的改进方法,并与对比解码进行对比,发现这些方法也能取得相似甚至更好的性能。这表明对比解码的性能提升主要归因于对输出分布的粗略调整和贪婪搜索,而非其缓解幻觉的能力。
🎯 应用场景
该研究成果对多模态大语言模型的研究具有重要意义,可以指导研究人员重新审视现有缓解幻觉的方法,并探索更有效的解决方案。其潜在应用领域包括图像描述生成、视觉问答等,有助于提高MLLM在实际应用中的可靠性和准确性,减少错误信息的产生。
📄 摘要(原文)
Contrastive decoding strategies are widely used to reduce object hallucinations in multimodal large language models (MLLMs). These methods work by constructing contrastive samples to induce hallucinations and then suppressing them in the output distribution. However, this paper demonstrates that such approaches fail to effectively mitigate the hallucination problem. The performance improvements observed on POPE Benchmark are largely driven by two misleading factors: (1) crude, unidirectional adjustments to the model's output distribution and (2) the adaptive plausibility constraint, which reduces the sampling strategy to greedy search. To further illustrate these issues, we introduce a series of spurious improvement methods and evaluate their performance against contrastive decoding techniques. Experimental results reveal that the observed performance gains in contrastive decoding are entirely unrelated to its intended goal of mitigating hallucinations. Our findings challenge common assumptions about the effectiveness of contrastive decoding strategies and pave the way for developing genuinely effective solutions to hallucinations in MLLMs.