AdaSteer: Your Aligned LLM is Inherently an Adaptive Jailbreak Defender
作者: Weixiang Zhao, Jiahe Guo, Yulin Hu, Yang Deng, An Zhang, Xingyu Sui, Xinyang Han, Yanyan Zhao, Bing Qin, Tat-Seng Chua, Ting Liu
分类: cs.CR, cs.CL
发布日期: 2025-04-13 (更新: 2025-09-19)
备注: 19 pages, 6 figures, 10 tables
💡 一句话要点
AdaSteer:提出自适应激活Steering方法,增强LLM的越狱防御能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 越狱攻击 激活Steering 自适应防御 安全对齐
📋 核心要点
- 现有激活steering防御方法依赖固定系数,导致防御效果不佳,且容易误判正常输入。
- AdaSteer通过学习自适应系数,动态调整steering强度,区分恶意和良性输入,提升防御效果。
- 实验表明,AdaSteer在多个LLM上优于现有方法,有效防御越狱攻击,同时保持模型可用性。
📝 摘要(中文)
尽管在安全对齐方面投入了大量精力,大型语言模型(LLMs)仍然容易受到越狱攻击。激活Steering提供了一种无需训练的防御方法,但依赖于固定的Steering系数,导致次优的保护效果和对良性输入的误判增加。为了解决这个问题,我们提出了AdaSteer,一种自适应激活Steering方法,可以根据输入特征动态调整模型行为。我们确定了两个关键属性:拒绝定律(R-Law),表明对于与拒绝方向相反的越狱输入,需要更强的Steering;以及有害性定律(H-Law),区分对抗性和良性输入。AdaSteer沿着拒绝方向(RD)和有害性方向(HD)Steering输入表示,通过逻辑回归学习自适应系数,确保强大的越狱防御,同时保留良性输入处理。在LLaMA-3.1、Gemma-2和Qwen2.5上的实验表明,AdaSteer在多种越狱攻击中优于基线方法,并且对效用的影响最小。我们的结果突出了可解释模型内部结构在LLM中实现实时、灵活安全执行的潜力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)容易受到越狱攻击的问题。现有的激活steering防御方法依赖于固定的steering系数,无法根据输入自适应调整,导致防御效果不佳,并且容易将正常的、良性的输入错误地识别为攻击,造成误判。
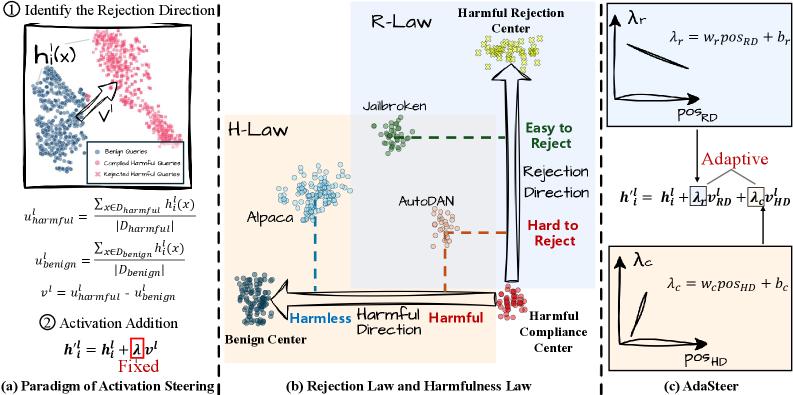
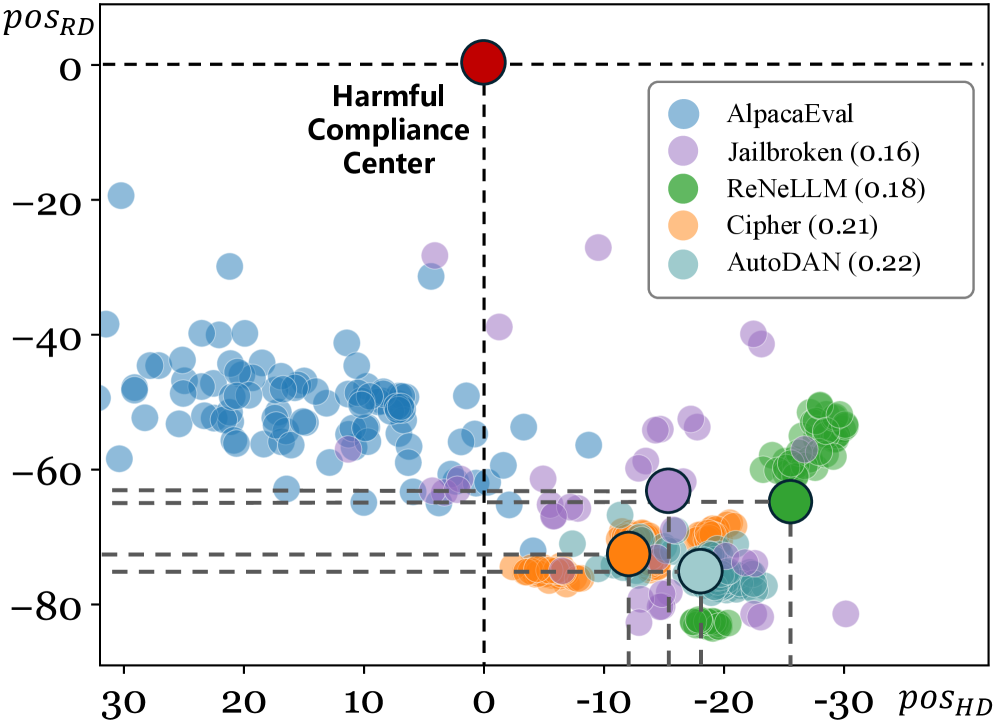
核心思路:AdaSteer的核心思路是根据输入特征动态调整激活steering的强度。它基于两个关键观察:一是“拒绝定律”(R-Law),即对于与拒绝方向相反的越狱攻击,需要更强的steering;二是“有害性定律”(H-Law),即需要区分对抗性输入和良性输入。通过学习自适应的steering系数,AdaSteer能够更有效地防御越狱攻击,同时减少对正常输入的误判。
技术框架:AdaSteer的技术框架主要包括以下几个步骤:1) 确定拒绝方向(RD)和有害性方向(HD);2) 提取输入特征,这些特征能够反映输入与RD和HD的关联程度;3) 使用逻辑回归模型学习自适应的steering系数,该系数用于控制沿着RD和HD进行steering的强度;4) 将学习到的steering系数应用于输入表示,从而调整模型的行为。
关键创新:AdaSteer的关键创新在于其自适应性。与传统的激活steering方法不同,AdaSteer不是使用固定的steering系数,而是根据输入特征动态调整。这种自适应性使得AdaSteer能够更有效地防御越狱攻击,同时减少对正常输入的误判。此外,论文提出的R-Law和H-Law为理解和设计有效的越狱防御方法提供了新的视角。
关键设计:AdaSteer的关键设计包括:1) 使用逻辑回归模型学习自适应系数,这使得模型能够根据输入特征灵活地调整steering强度;2) 引入拒绝方向(RD)和有害性方向(HD),这两个方向分别用于抑制越狱攻击和区分对抗性输入与良性输入;3) 特征工程,选择合适的输入特征,这些特征能够有效反映输入与RD和HD的关联程度。具体的特征选择和逻辑回归模型的参数设置可能需要根据具体的LLM和攻击类型进行调整。
🖼️ 关键图片
📊 实验亮点
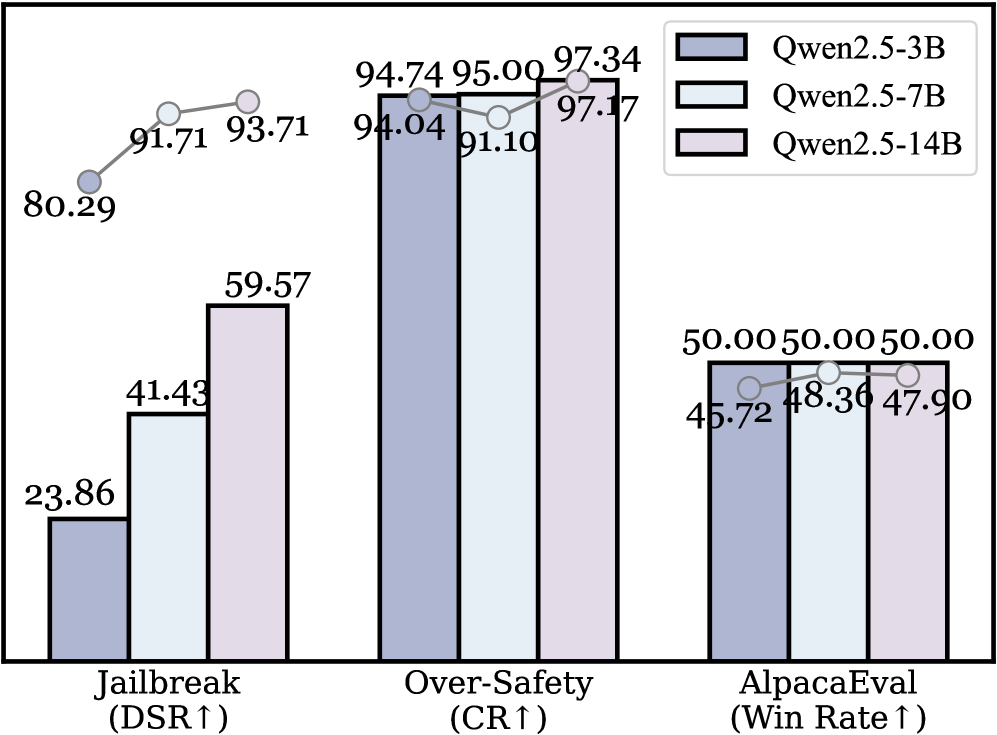
实验结果表明,AdaSteer在LLaMA-3.1、Gemma-2和Qwen2.5等多个LLM上显著优于基线方法。在防御多种越狱攻击的同时,AdaSteer对模型效用的影响极小。具体而言,AdaSteer在防御成功率方面取得了显著提升,同时保持了较高的良性输入通过率,证明了其在安全性和可用性之间的良好平衡。
🎯 应用场景
AdaSteer具有广泛的应用前景,可用于增强各种LLM的安全性,例如聊天机器人、智能助手等。通过实时、灵活地调整模型行为,AdaSteer可以有效防御各种越狱攻击,保护用户免受恶意信息的侵害。此外,AdaSteer的自适应性使其能够适应不同的应用场景和用户需求,提供更加个性化的安全保护。未来,AdaSteer有望成为LLM安全领域的重要组成部分。
📄 摘要(原文)
Despite extensive efforts in safety alignment, large language models (LLMs) remain vulnerable to jailbreak attacks. Activation steering offers a training-free defense method but relies on fixed steering coefficients, resulting in suboptimal protection and increased false rejections of benign inputs. To address this, we propose AdaSteer, an adaptive activation steering method that dynamically adjusts model behavior based on input characteristics. We identify two key properties: Rejection Law (R-Law), which shows that stronger steering is needed for jailbreak inputs opposing the rejection direction, and Harmfulness Law (H-Law), which differentiates adversarial and benign inputs. AdaSteer steers input representations along both the Rejection Direction (RD) and Harmfulness Direction (HD), with adaptive coefficients learned via logistic regression, ensuring robust jailbreak defense while preserving benign input handling. Experiments on LLaMA-3.1, Gemma-2, and Qwen2.5 show that AdaSteer outperforms baseline methods across multiple jailbreak attacks with minimal impact on utility. Our results highlight the potential of interpretable model internals for real-time, flexible safety enforcement in LLMs.