Read Before You Think: Mitigating LLM Comprehension Failures with Step-by-Step Reading
作者: Feijiang Han, Hengtao Cui, Licheng Guo, Zelong Wang, Zhiyuan Lyu
分类: cs.CL, cs.AI
发布日期: 2025-04-13 (更新: 2025-09-18)
备注: Done in November 2024
💡 一句话要点
提出Step-by-Step Reading (SSR)系列提示方法,提升LLM在复杂推理任务中的问题理解能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 问题理解 推理能力 提示工程 逐步阅读
📋 核心要点
- 现有LLM在复杂推理任务中表现不佳,问题理解不足是关键瓶颈,而非单纯的逻辑推理缺陷。
- 论文提出Step-by-Step Reading (SSR)系列提示方法,通过多阶段阅读过程提升LLM的问题理解能力。
- 实验表明,SSR++在多个推理基准测试中取得了state-of-the-art的结果,有效缓解了语义误解。
📝 摘要(中文)
大型语言模型(LLMs)在复杂推理任务中常常失败,这不仅是因为逻辑推理能力不足,更是由于对问题的理解存在缺陷。本文对这些理解失败进行了系统性研究,并提出了三个关键见解:(1)适用于计算的逐步原则可以迁移到阅读过程中,以增强理解能力;(2)增加与问题相关的token比例(例如,通过重复)可以通过重新聚焦注意力来成功,这是一种可以显式控制的机制;(3)即使使用像Chain-of-Thought这样的强大方法,后向依赖关系仍然是仅解码器模型的瓶颈。基于这些发现,我们引入了Step-by-Step Reading (SSR)系列提示方法。这种多阶段方法最终形成了SSR++,该方法专门设计用于通过引导模型以更精细的粒度解析问题、将注意力集中在关键token上以及通过迭代重新上下文化来解决后向依赖关系,从而加深模型理解。SSR++在多个推理基准测试中创造了新的state-of-the-art,我们的分析证实它通过直接减轻语义误解来发挥作用。这些结果表明,引导模型如何阅读是提高其推理能力的一种强大而有效的方法。
🔬 方法详解
问题定义:大型语言模型在复杂推理任务中表现欠佳,一个主要原因是模型对问题的理解存在偏差或不足,导致后续的推理过程基于错误的前提。现有方法,如Chain-of-Thought,主要关注如何提升模型的推理能力,而忽略了问题理解的重要性。因此,如何提升LLM对复杂问题的理解能力,避免语义误解,是本文要解决的核心问题。
核心思路:论文的核心思路是将计算领域的“逐步”原则迁移到阅读理解领域,通过引导模型逐步解析问题,加深对问题的理解。此外,论文还发现,增加问题相关token的比例可以有效提升模型对关键信息的关注度。最后,论文针对decoder-only模型在处理后向依赖关系时的瓶颈,提出了迭代重构上下文的方法。
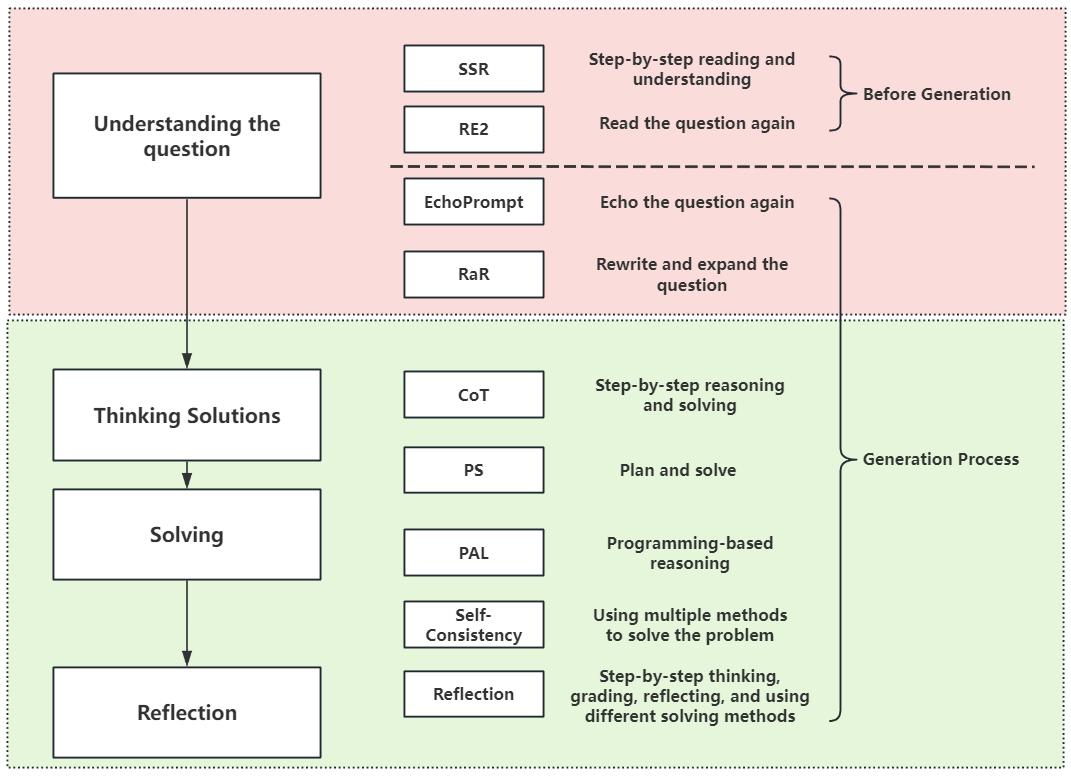
技术框架:Step-by-Step Reading (SSR) 是一种多阶段提示方法,旨在提升LLM的问题理解能力。该方法包含多个变体,其中SSR++是最终版本,也是性能最佳的版本。SSR++的核心流程包括:首先,引导模型以更精细的粒度解析问题;其次,通过增加关键token的关注度,使模型聚焦于重要信息;最后,通过迭代重构上下文,解决后向依赖关系。
关键创新:论文的关键创新在于将“逐步”原则应用于阅读理解,并提出了SSR系列提示方法。与传统的提示方法相比,SSR更加注重引导模型逐步解析问题,从而加深对问题的理解。此外,论文还创新性地提出了通过增加问题相关token的比例来提升模型关注度的方法,以及通过迭代重构上下文来解决后向依赖关系的方法。
关键设计:SSR++的具体实现细节未知,但根据论文描述,其关键设计包括:(1) 精细粒度的解析策略,引导模型逐步分解问题;(2) 注意力聚焦机制,通过增加关键token的比例来提升模型关注度;(3) 迭代重构上下文机制,解决后向依赖关系。具体的参数设置、损失函数、网络结构等技术细节未在论文中详细描述。
🖼️ 关键图片

📊 实验亮点
SSR++在多个推理基准测试中取得了state-of-the-art的结果,证明了其有效性。论文分析表明,SSR++通过直接减轻语义误解来提升模型性能。具体的性能数据和对比基线未在摘要中给出,需要查阅原文。
🎯 应用场景
该研究成果可广泛应用于需要复杂推理能力的自然语言处理任务中,例如问答系统、阅读理解、文本摘要等。通过提升LLM的问题理解能力,可以显著提高这些应用系统的性能和可靠性。此外,该研究还可以为LLM的prompt工程提供新的思路和方法。
📄 摘要(原文)
Large Language Models (LLMs) often fail on complex reasoning tasks due to flawed question comprehension, not just flawed logic. This paper presents a systematic investigation into these comprehension failures. Our work yields three key insights: (1) the step-by-step principle, effective for calculation, can be migrated to the reading process to enhance comprehension; (2) increasing the proportion of question-related tokens (e.g., via repetition) succeeds by refocusing attention, a mechanism that can be explicitly controlled; and (3) backward dependencies represent a core bottleneck for decoder-only models that persists even with strong methods like Chain-of-Thought. Based on these findings, we introduce the Step-by-Step Reading (SSR) family of prompts. This multi-stage approach culminates in SSR++, a method specifically engineered to deepen model comprehension by guiding it to parse questions with finer granularity, focus attention on critical tokens, and resolve backward dependencies through iterative re-contextualization. SSR++ sets a new state-of-the-art on multiple reasoning benchmarks, and our analysis confirms it works by directly mitigating semantic misunderstanding. These results demonstrate that guiding how a model reads is a powerful and efficient method for improving its reasoning ability.