Measuring LLM Novelty As The Frontier Of Original And High-Quality Output
作者: Vishakh Padmakumar, Chen Yueh-Han, Jane Pan, Valerie Chen, He He
分类: cs.CL
发布日期: 2025-04-13 (更新: 2025-10-06)
备注: Updated results with higher coverage of open-data models and better quality judgments
💡 一句话要点
提出一种新颖性指标,通过平衡原创性和质量来评估LLM的创造性输出能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 新颖性评估 原创性 质量评估 创造性任务 调和平均数 模型规模 后训练
📋 核心要点
- 现有LLM新颖性评估方法要么只关注原创性而忽略质量,要么依赖人类评估易受记忆性内容影响。
- 提出一种新颖性指标,通过计算模型生成文本中未见n-gram比例和质量分数的调和平均数来平衡原创性和质量。
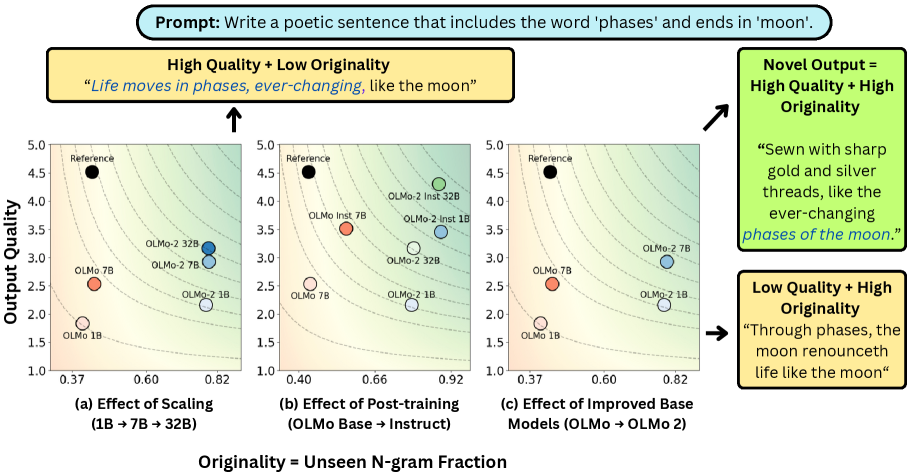
- 实验表明,增大模型规模和后训练能有效提升新颖性,但推理时prompting方法提升有限,甚至会牺牲质量。
📝 摘要(中文)
大型语言模型(LLM)越来越多地被用于创意和科学发现,评估它们生成新颖输出的能力至关重要。以往的研究主要关注相对于模型训练数据的原创性,但原创输出的质量可能较低。另一方面,非专业人士的质量评分更可靠,但可能偏爱记忆性输出,从而限制了人类偏好作为指标的可靠性。本文提出了一种新的LLM生成文本新颖性指标,它平衡了原创性和质量——即训练期间未见n-gram比例与特定任务质量分数的调和平均数。基于此框架,我们研究了三个开源模型系列(OLMo、OLMo-2和Pythia)在故事续写、诗歌创作和创造性工具使用三个创意任务中,影响生成文本新颖性的因素。研究发现,一些基础LLM生成的文本的新颖性低于互联网上的人类文本。然而,增加模型规模和后训练能够可靠地提高新颖性,这归功于输出质量的提升。此外,在相同规模下改进基础模型(例如,OLMo 7B到OLMo-2 7B)由于更高的原创性而带来更高的新颖性。最后,我们观察到推理时方法,如提示和提供新颖的上下文示例,对新颖性的影响较小,通常以牺牲质量为代价来提高原创性。这突显了在将模型用于创造性应用时,需要进一步研究更有效的启发策略。
🔬 方法详解
问题定义:现有评估LLM生成文本新颖性的方法存在局限性。单纯关注原创性(例如,与训练数据的差异)可能导致低质量的“新颖”输出。而依赖人类评估又容易受到人类偏见的影响,例如,人类可能更喜欢他们已经熟悉的、高质量的记忆性内容,从而低估了真正新颖但可能不完美的输出。因此,如何准确衡量LLM生成文本的新颖性,同时兼顾原创性和质量,是一个亟待解决的问题。
核心思路:本文的核心思路是,将新颖性定义为原创性和质量的平衡。具体来说,一个好的新颖性指标应该能够区分出既具有原创性(即与训练数据不同),又具有高质量(即符合任务要求)的生成文本。为了实现这一目标,作者提出了一个基于调和平均数的新颖性指标,该指标同时考虑了生成文本的原创性和质量。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择LLM模型和创意任务;2) 使用LLM生成文本;3) 计算生成文本的原创性得分(基于未见n-gram的比例);4) 计算生成文本的质量得分(使用任务特定的质量评估方法);5) 使用调和平均数将原创性得分和质量得分结合起来,得到最终的新颖性得分。
关键创新:该研究的关键创新在于提出了一个平衡原创性和质量的新颖性指标。与以往只关注原创性的方法相比,该指标能够更准确地反映LLM生成文本的真实新颖性。此外,该研究还通过实验验证了该指标的有效性,并发现了一些影响LLM生成文本新颖性的重要因素,例如模型规模、后训练和推理时prompting。
关键设计:该研究的关键设计包括:1) 使用未见n-gram的比例来衡量原创性,这是一种简单而有效的衡量方法;2) 使用任务特定的质量评估方法来衡量质量,这可以确保质量评估与具体任务相关;3) 使用调和平均数来平衡原创性和质量,这可以避免其中一个指标过高而掩盖另一个指标过低的情况。具体来说,调和平均数公式为:Novelty = 2 / (1/Originality + 1/Quality)。
🖼️ 关键图片


📊 实验亮点
实验结果表明,增大模型规模和进行后训练能够显著提升LLM生成文本的新颖性。例如,OLMo-2 7B模型相比OLMo 7B模型,在相同规模下实现了更高的新颖性。此外,研究还发现,推理时prompting方法对新颖性的提升效果有限,甚至可能以牺牲质量为代价。这些发现为LLM的开发和应用提供了有价值的指导。
🎯 应用场景
该研究成果可应用于评估和改进LLM在创意写作、科学发现等领域的应用。通过使用该新颖性指标,可以更好地了解不同模型和训练方法对LLM创造性能力的影响,从而指导模型设计和训练,提升LLM在实际应用中的表现。此外,该指标还可以用于评估不同prompting策略的效果,帮助用户更好地利用LLM进行创意生成。
📄 摘要(原文)
As large language models (LLMs) are increasingly used for ideation and scientific discovery, it is important to evaluate their ability to generate novel output. Prior work evaluates novelty as originality with respect to model training data, but original outputs may be of low quality. In contrast, non-expert judges more reliably score quality but may favor memorized outputs, limiting the reliability of human preference as a metric. We introduce a new novelty metric for LLM generations that balances originality and quality -- the harmonic mean of the fraction of \ngrams unseen during training and a task-specific quality score. Using this framework, we identify trends that affect the novelty of generations from three families of open-data models (OLMo, OLMo-2, and Pythia) on three creative tasks: story completion, poetry writing, and creative tool use. We find that model-generated text from some base LLMs is less novel than human-written text from the internet. However, increasing model scale and post-training reliably improves novelty due to improvements in output quality. We also find that improving the base model at the same scale (\eg OLMo 7B to OLMo-2 7B) leads to higher novelty due to higher originality. Finally, we observe that inference-time methods, such as prompting and providing novel in-context examples, have a much smaller effect on novelty, often increasing originality at the expense of quality. This highlights the need for further research into more effective elicitation strategies as we use models for creative applications.