Reconstructing Sepsis Trajectories from Clinical Case Reports using LLMs: the Textual Time Series Corpus for Sepsis
作者: Shahriar Noroozizadeh, Jeremy C. Weiss
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-04-12 (更新: 2025-08-04)
💡 一句话要点
利用LLM从临床病例报告重建脓毒症轨迹,构建脓毒症文本时间序列语料库
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 临床病例报告 时间序列分析 脓毒症 自然语言处理
📋 核心要点
- 现有临床数据存在时间信息不完整或滞后的问题,阻碍了对疾病发展过程的深入理解和建模。
- 该论文提出利用大型语言模型(LLM)从临床病例报告中提取时间局部性的临床发现,重建疾病轨迹。
- 实验表明,该方法在临床发现的恢复率和时间顺序一致性方面表现良好,验证了LLM在时间定位方面的潜力。
📝 摘要(中文)
临床病例报告和出院总结可能是患者就诊最完整和准确的总结,但它们是在就诊后才最终确定并带有时间戳的。互补的结构化数据流可以更快地获得,但存在不完整的问题。为了在更完整和时间粒度更细的数据上训练模型和算法,我们构建了一个流程,使用大型语言模型对病例报告中的时间局部性发现进行表型分析、提取和注释。我们将我们的流程应用于生成一个开放访问的脓毒症-3文本时间序列语料库,该语料库包含来自Pubmed-Open Access (PMOA)子集的2,139份病例报告。为了验证我们的系统,我们将其应用于PMOA和来自I2B2/MIMIC-IV的时间线注释,并将结果与医生专家的注释进行比较。我们展示了临床发现的高恢复率(事件匹配率:O1-preview--0.755,Llama 3.3 70B Instruct--0.753)和强大的时间顺序(一致性:O1-preview--0.932,Llama 3.3 70B Instruct--0.932)。我们的工作描述了LLM在文本中时间定位临床发现的能力,说明了LLM用于时间重建的局限性,并提供了通过多模态集成改进的几种潜在途径。
🔬 方法详解
问题定义:现有临床数据,如电子病历,虽然包含丰富的患者信息,但往往存在时间信息不完整、数据滞后等问题。临床病例报告虽然信息完整,但通常在事件发生后才最终确定,无法提供实时的时间信息。这限制了对疾病发展轨迹的准确建模和分析。
核心思路:该论文的核心思路是利用大型语言模型(LLM)的自然语言理解能力,从临床病例报告的文本中提取时间相关的临床发现。通过对文本进行分析,确定事件发生的时间顺序和时间局部性,从而重建患者的疾病发展轨迹。这种方法旨在弥补现有临床数据在时间信息方面的不足。
技术框架:该论文构建了一个包含以下主要阶段的流程:1) 病例报告收集:从Pubmed-Open Access (PMOA)子集中收集脓毒症病例报告。2) LLM驱动的表型分析、提取和注释:使用LLM对病例报告进行处理,提取临床发现,并标注其对应的时间信息。3) 时间序列语料库构建:将提取的临床发现和时间信息整合,构建脓毒症文本时间序列语料库。4) 系统验证:将LLM提取的结果与医生专家的注释进行比较,评估系统的性能。
关键创新:该论文的关键创新在于利用LLM从非结构化的临床文本中提取时间信息,并将其转化为结构化的时间序列数据。这使得可以利用病例报告中包含的丰富信息,构建更完整和时间粒度更细的疾病发展轨迹模型。与传统的手工标注方法相比,LLM驱动的方法可以大大提高效率和可扩展性。
关键设计:论文中使用了O1-preview和Llama 3.3 70B Instruct等LLM模型进行实验。评估指标包括事件匹配率(衡量临床发现的恢复率)和时间顺序一致性(衡量时间顺序的准确性)。具体参数设置和损失函数等技术细节在论文中可能未详细描述,属于未知信息。
🖼️ 关键图片

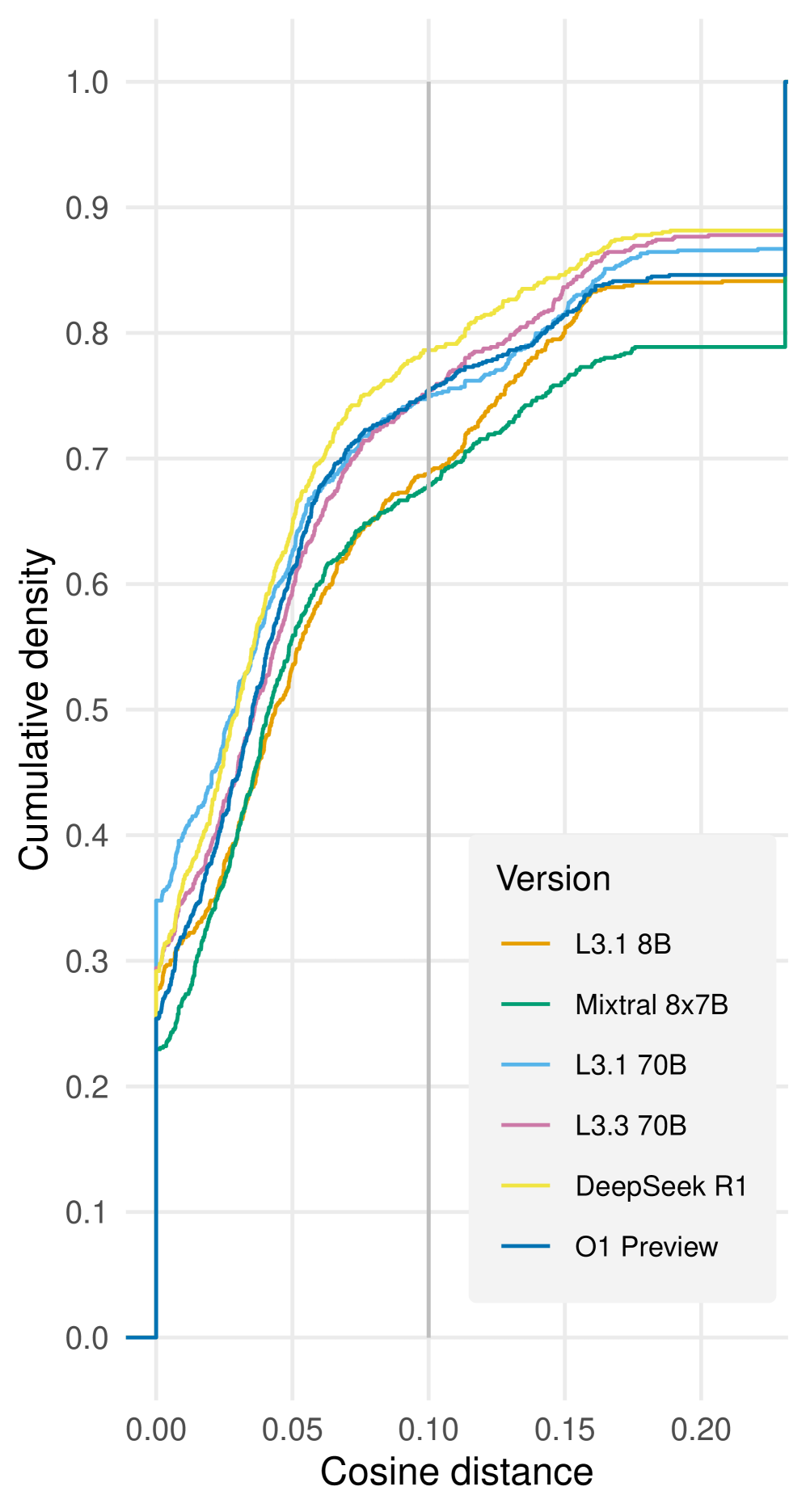

📊 实验亮点
实验结果表明,该方法在临床发现的恢复率和时间顺序一致性方面表现良好。具体而言,使用O1-preview模型和Llama 3.3 70B Instruct模型分别达到了0.755和0.753的事件匹配率,以及0.932和0.932的时间顺序一致性。这些结果表明LLM在时间定位临床发现方面具有潜力。
🎯 应用场景
该研究成果可应用于构建更准确的疾病发展模型,辅助临床决策,例如早期预警、个性化治疗方案制定等。此外,构建的脓毒症文本时间序列语料库可作为研究资源,促进相关领域的研究进展。未来可扩展到其他疾病领域,具有广泛的应用前景。
📄 摘要(原文)
Clinical case reports and discharge summaries may be the most complete and accurate summarization of patient encounters, yet they are finalized, i.e., timestamped after the encounter. Complementary data structured streams become available sooner but suffer from incompleteness. To train models and algorithms on more complete and temporally fine-grained data, we construct a pipeline to phenotype, extract, and annotate time-localized findings within case reports using large language models. We apply our pipeline to generate an open-access textual time series corpus for Sepsis-3 comprising 2,139 case reports from the Pubmed-Open Access (PMOA) Subset. To validate our system, we apply it on PMOA and timeline annotations from I2B2/MIMIC-IV and compare the results to physician-expert annotations. We show high recovery rates of clinical findings (event match rates: O1-preview--0.755, Llama 3.3 70B Instruct--0.753) and strong temporal ordering (concordance: O1-preview--0.932, Llama 3.3 70B Instruct--0.932). Our work characterizes the ability of LLMs to time-localize clinical findings in text, illustrating the limitations of LLM use for temporal reconstruction and providing several potential avenues of improvement via multimodal integration.