Feature-Aware Malicious Output Detection and Mitigation
作者: Weilong Dong, Peiguang Li, Yu Tian, Xinyi Zeng, Fengdi Li, Sirui Wang
分类: cs.CL
发布日期: 2025-04-12
💡 一句话要点
提出特征感知恶意输出检测与缓解方法,提升大语言模型安全性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 恶意输出检测 特征感知 安全防御 越狱攻击
📋 核心要点
- 大型语言模型面临越狱攻击的挑战,现有方法难以有效识别和防御恶意内容。
- 提出特征感知恶意输出检测与缓解方法(FMM),通过检测恶意特征并自适应调整拒绝机制来增强安全性。
- 实验表明,FMM在多种模型和攻击下有效,并能保持模型的标准生成能力。
📝 摘要(中文)
大型语言模型(LLMs)的快速发展在各个领域带来了显著的益处,同时也引入了巨大的风险。尽管通过强化学习进行了微调,LLMs仍然缺乏辨别恶意内容的能力,限制了它们对越狱攻击的防御。为了解决这些安全问题,我们提出了一种用于有害响应拒绝的特征感知方法(FMM),该方法检测模型特征空间中恶意特征的存在,并自适应地调整模型的拒绝机制。通过使用一个简单的判别器,我们在解码阶段检测潜在的恶意特征。一旦检测到指示有害token的特征,FMM会重新生成当前的token。通过采用激活修补,在后续的token生成过程中引入额外的拒绝向量,引导模型产生拒绝响应。实验结果表明,我们的方法在多种语言模型和不同的攻击技术中都有效,同时关键的是,它保持了模型的标准生成能力。
🔬 方法详解
问题定义:大型语言模型(LLMs)容易受到对抗性攻击(例如越狱攻击),导致生成有害或不当内容。现有的防御方法通常依赖于人工规则或数据集,泛化能力有限,并且难以适应不断演变的攻击手段。因此,如何使LLM具备更强的恶意内容识别和防御能力是一个关键问题。
核心思路:该论文的核心思路是在LLM的特征空间中检测恶意特征,并利用这些特征自适应地调整模型的拒绝机制。具体来说,通过训练一个判别器来识别指示有害token的特征,并在生成过程中,如果检测到恶意特征,则重新生成token,并引入额外的拒绝向量,引导模型生成拒绝响应。这种方法的核心在于利用模型自身的特征空间来识别恶意内容,从而提高防御的鲁棒性和泛化能力。
技术框架:FMM方法主要包含以下几个模块:1) 特征提取:从LLM的中间层提取特征向量。2) 恶意特征判别器:训练一个判别器,用于识别特征向量中是否存在恶意特征。3) Token重生成:如果判别器检测到恶意特征,则重新生成当前的token。4) 激活修补:在后续的token生成过程中,引入额外的拒绝向量,引导模型生成拒绝响应。整体流程是在解码阶段,对每个生成的token进行恶意特征检测,如果检测到恶意特征,则进行token重生成和激活修补,从而避免生成有害内容。
关键创新:该论文的关键创新在于提出了一种特征感知的恶意输出检测与缓解方法。与以往的方法不同,该方法不是直接对输入文本进行过滤或修改,而是深入到LLM的特征空间中,利用模型自身的特征来识别恶意内容。这种方法具有更强的鲁棒性和泛化能力,能够有效地防御各种越狱攻击。此外,通过token重生成和激活修补,该方法能够在不影响模型标准生成能力的前提下,有效地缓解恶意输出。
关键设计:恶意特征判别器可以使用简单的神经网络结构,例如多层感知机(MLP)。训练判别器时,可以使用二元交叉熵损失函数,将有害token的特征向量标记为正样本,将正常token的特征向量标记为负样本。激活修补可以通过在LLM的隐藏层中添加一个额外的拒绝向量来实现。拒绝向量可以通过训练得到,也可以手动设计。关键参数包括判别器的网络结构、学习率、拒绝向量的大小和方向等。
🖼️ 关键图片


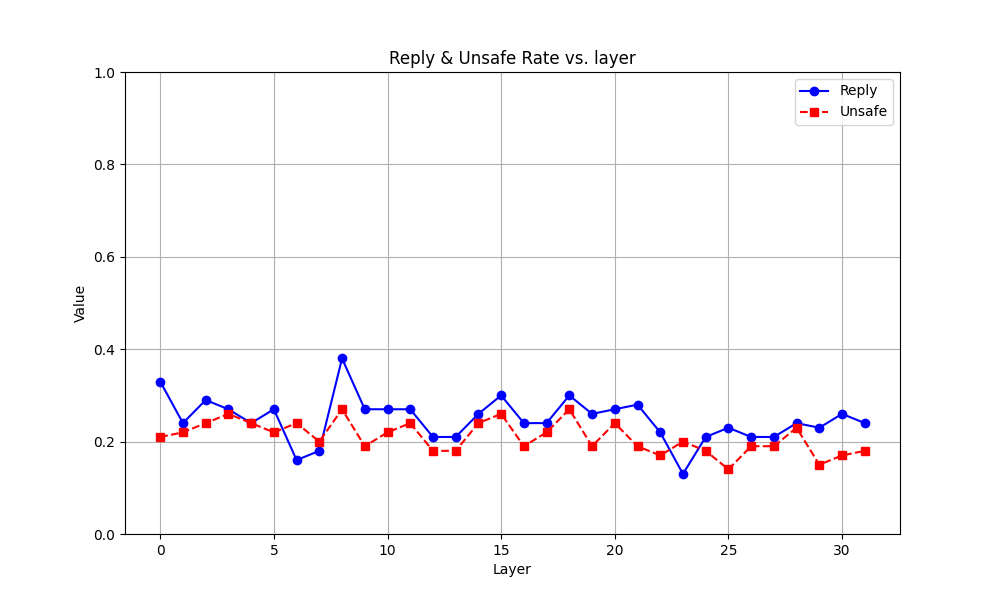
📊 实验亮点
实验结果表明,FMM方法在多种语言模型(包括LLaMA和GPT系列)和不同的攻击技术(例如提示注入、对抗性后缀等)中都表现出良好的效果。与现有的防御方法相比,FMM能够更有效地检测和缓解恶意输出,同时保持模型的标准生成能力。具体性能数据未知,但摘要强调了其有效性。
🎯 应用场景
该研究成果可应用于各种需要安全保障的大型语言模型应用场景,例如智能客服、内容生成、代码生成等。通过提高模型对恶意输入的防御能力,可以有效防止模型生成有害、不当或具有误导性的内容,从而提升用户体验,降低安全风险,并促进LLM在更多领域的应用。
📄 摘要(原文)
The rapid advancement of large language models (LLMs) has brought significant benefits to various domains while introducing substantial risks. Despite being fine-tuned through reinforcement learning, LLMs lack the capability to discern malicious content, limiting their defense against jailbreak. To address these safety concerns, we propose a feature-aware method for harmful response rejection (FMM), which detects the presence of malicious features within the model's feature space and adaptively adjusts the model's rejection mechanism. By employing a simple discriminator, we detect potential malicious traits during the decoding phase. Upon detecting features indicative of toxic tokens, FMM regenerates the current token. By employing activation patching, an additional rejection vector is incorporated during the subsequent token generation, steering the model towards a refusal response. Experimental results demonstrate the effectiveness of our approach across multiple language models and diverse attack techniques, while crucially maintaining the models' standard generation capabilities.