A Strategic Coordination Framework of Small LLMs Matches Large LLMs in Data Synthesis
作者: Xin Gao, Qizhi Pei, Zinan Tang, Yu Li, Honglin Lin, Jiang Wu, Lijun Wu, Conghui He
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-04-11 (更新: 2025-04-21)
🔗 代码/项目: GITHUB
💡 一句话要点
提出GRA框架,通过协同小LLM实现与大LLM相当的数据合成能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据合成 小型语言模型 协同学习 模型蒸馏 同行评审 数据增强 GRA框架
📋 核心要点
- 现有数据合成方法依赖大型LLM,存在成本高、效率低和偏见等问题,小型LLM难以单独生成高质量数据。
- 提出GRA框架,通过多个小型LLM协作,模拟同行评审流程,分解数据合成任务,提升数据质量和多样性。
- 实验表明,GRA生成的数据质量与大型LLM相当甚至超过,证明了小型智能体战略协调的可行性。
📝 摘要(中文)
数据合成和蒸馏是增强小型语言模型的有效策略,但现有方法严重依赖大型语言模型(LLM),导致计算成本高昂、环境效率低下,并可能继承单体架构的偏见。相比之下,小型LLM更易于访问且更具可持续性,但其个体能力通常不足以生成高质量、多样化和可靠的数据。受人类协作过程(如同行评审)的启发,我们提出了一个涉及多个小型LLM的框架GRA,该框架聚合了小型LLM的专业角色,以实现通常由单个大型LLM实现的迭代改进和质量控制。在这个协作框架中,多个小型LLM承担不同的角色——生成器、审阅者和仲裁者——以模拟受同行评审启发的的数据合成流程。生成器提出初始数据样本,审阅者批判其质量和多样性,仲裁者解决冲突以最终确定输出。通过将合成过程分解为专门的子任务,协作小型LLM可以在数据层面上达到与基于大型LLM的蒸馏相当的水平。通过跨多个基准的实验,我们证明了GRA生成的数据在质量上与单个大型LLM(例如,Qwen-2.5-72B-Instruct)的输出相匹配或超过。我们的结果挑战了单体大型模型对于高质量数据合成的必要性,转而提倡小型智能体的战略协调。我们的数据集、模型和代码已在https://github.com/GX-XinGao/GRA上公开发布。
🔬 方法详解
问题定义:论文旨在解决数据合成过程中对大型语言模型(LLM)的过度依赖问题。现有方法虽然能够生成高质量数据,但由于大型LLM的计算成本高昂、环境效率低下,以及潜在的偏见继承,使得数据合成过程的可持续性和公平性受到挑战。小型LLM虽然更易于获取和使用,但其个体能力不足以生成高质量、多样化和可靠的数据,无法满足数据合成的需求。
核心思路:论文的核心思路是借鉴人类协作过程中的同行评审机制,构建一个由多个小型LLM组成的协作框架,通过分工合作和迭代优化,实现与大型LLM相当的数据合成能力。这种方法的核心在于将复杂的数据合成任务分解为多个专门的子任务,并分配给不同的小型LLM,从而充分利用小型LLM的优势,弥补其个体能力的不足。
技术框架:GRA框架包含三个主要角色:生成器(Generator)、审阅者(Reviewer)和仲裁者(Adjudicator)。生成器负责提出初始数据样本;审阅者负责评估数据样本的质量和多样性,并提出改进意见;仲裁者负责解决生成器和审阅者之间的冲突,并最终确定输出。整个流程是一个迭代的过程,生成器根据审阅者的反馈不断改进数据样本,直到仲裁者认为数据质量达到要求为止。
关键创新:论文最重要的技术创新点在于提出了一个基于小型LLM协作的数据合成框架,该框架能够通过分工合作和迭代优化,实现与大型LLM相当的数据合成能力。与现有方法相比,该框架不仅降低了计算成本和环境负担,还能够避免大型LLM的潜在偏见,提高了数据合成的可持续性和公平性。
关键设计:GRA框架的关键设计包括角色分配、迭代流程和冲突解决机制。角色分配需要根据小型LLM的特点和能力进行合理分配,以充分发挥其优势。迭代流程需要设计合适的反馈机制,以便生成器能够及时了解审阅者的意见并进行改进。冲突解决机制需要设计有效的仲裁规则,以确保数据合成过程的公平性和效率。具体的参数设置、损失函数和网络结构等技术细节取决于所使用的小型LLM和具体的应用场景,论文中未详细说明。
🖼️ 关键图片
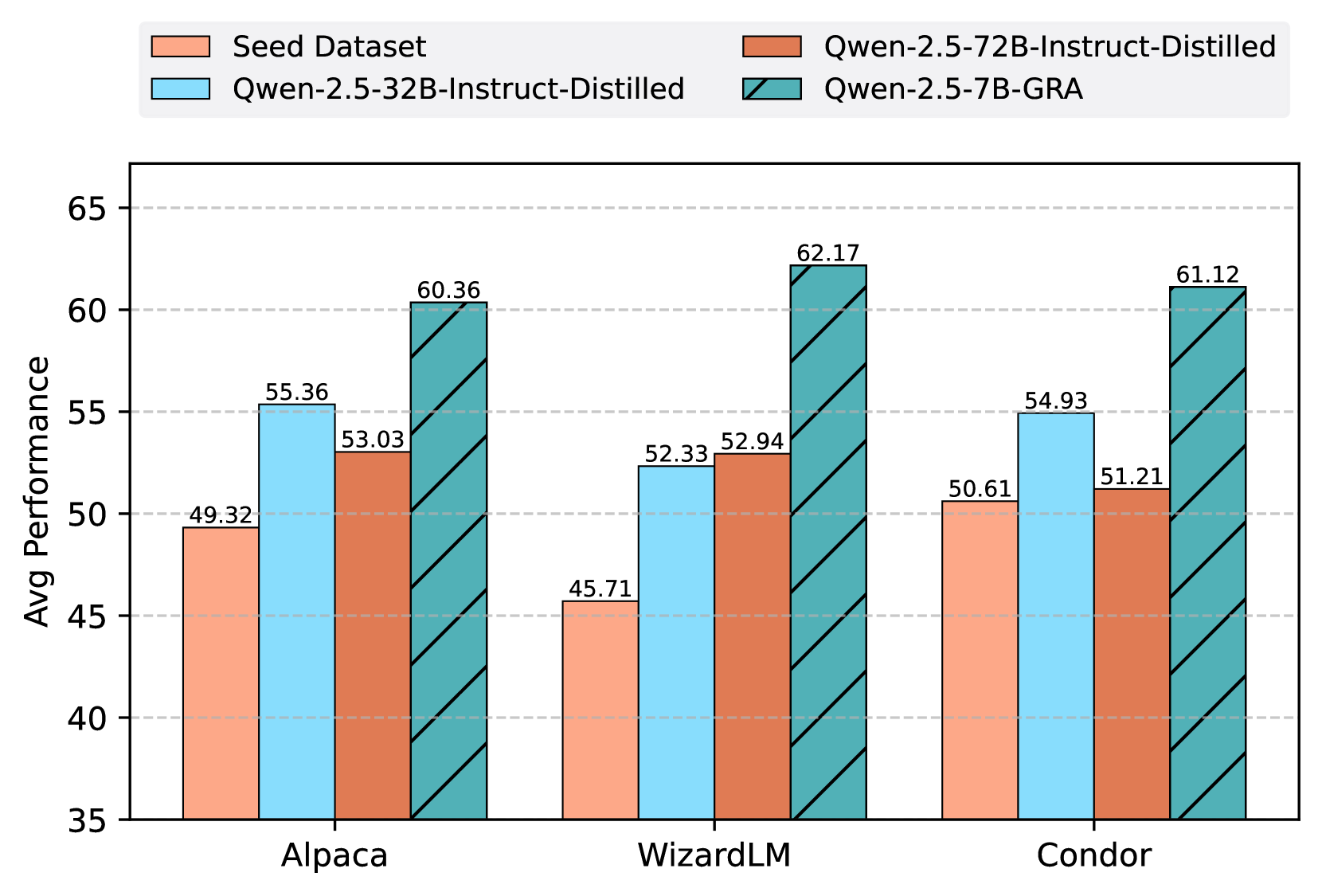

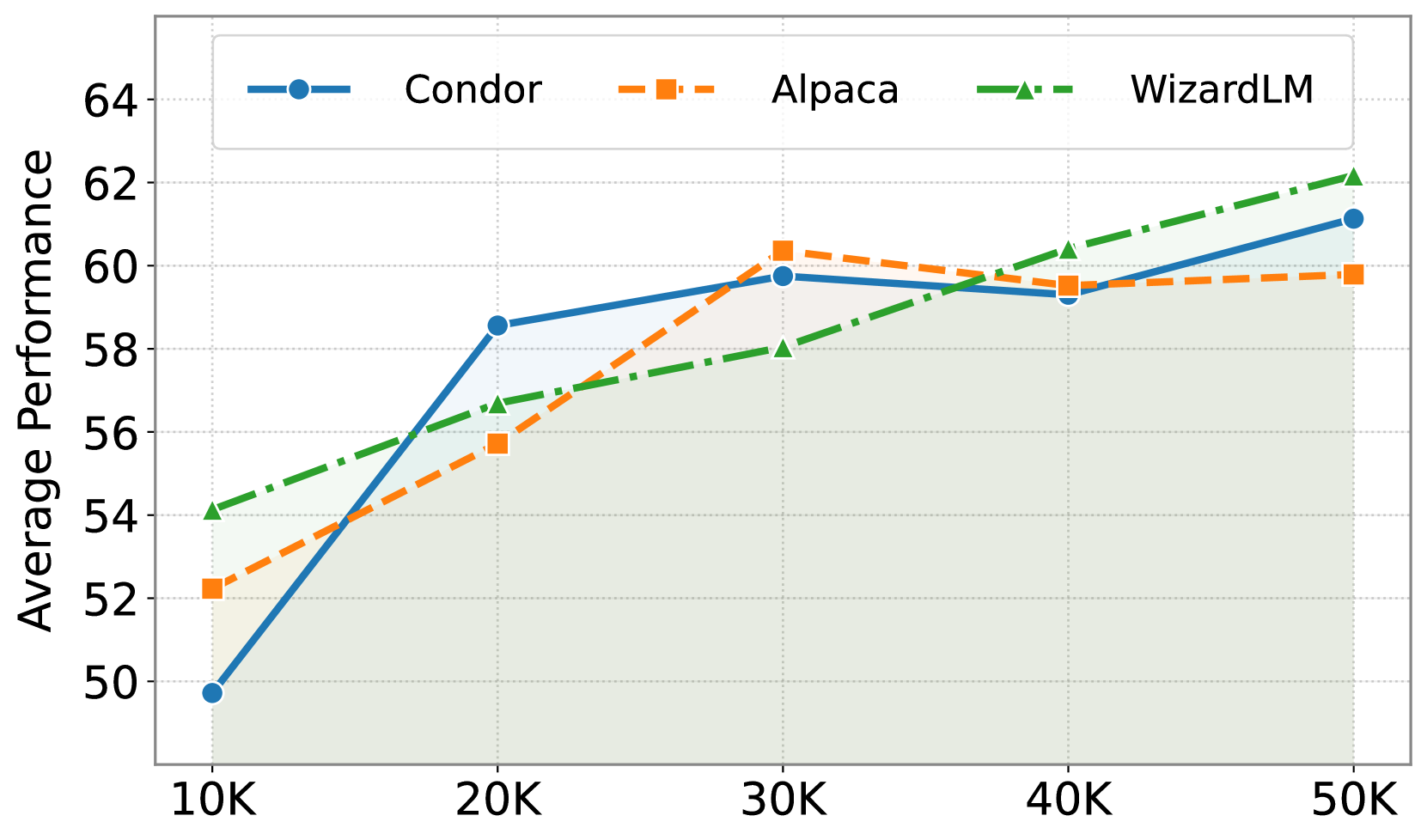
📊 实验亮点
实验结果表明,GRA框架生成的数据在质量上与大型LLM(如Qwen-2.5-72B-Instruct)的输出相匹配甚至超过。这表明,通过小型LLM的战略协调,可以实现与大型LLM相当的数据合成能力,挑战了单体大型模型对于高质量数据合成的必要性。具体的性能数据和提升幅度在论文中进行了详细的展示。
🎯 应用场景
该研究成果可广泛应用于各种需要数据合成的场景,例如模型蒸馏、数据增强和领域自适应等。通过使用GRA框架,可以降低数据合成的成本和环境负担,提高数据质量和多样性,并避免大型LLM的潜在偏见。该研究还有助于推动小型LLM的发展和应用,使其能够在更多领域发挥作用。
📄 摘要(原文)
While data synthesis and distillation are promising strategies to enhance small language models, current approaches heavily rely on Large Language Models (LLMs), which suffer from high computational costs, environmental inefficiency, and potential biases inherited from monolithic architectures. In contrast, smaller LLMs are more accessible and sustainable, but their individual capabilities often fall short in generating high-quality, diverse, and reliable data. Inspired by collaborative human processes (e.g., peer review), we propose a multiple small LLMs involved framework, GRA, that aggregates specialized roles across small LLMs to iterative refinement and quality control typically achieved by a single large LLM. In this collaborative framework, multiple small LLMs assume distinct roles-Generator, Reviewer, and Adjudicator-to simulate a peer-review-inspired data synthesis pipeline. The Generator proposes initial data samples, the Reviewer critiques their quality and diversity, and the Adjudicator resolves conflicts to finalize the output. By decomposing the synthesis process into specialized sub-tasks, collaborative small LLMs can achieve data-level parity with large LLM-based distillation. Through experiments across multiple benchmarks, we demonstrate that GRA-produced data matches or exceeds the quality of single large LLM outputs, e.g., Qwen-2.5-72B-Instruct. Our results challenge the necessity of monolithic large models for high-quality data synthesis, advocating instead for strategic coordination of smaller agents. Our datasets, models, and code are publicly available at https://github.com/GX-XinGao/GRA.