Generating Planning Feedback for Open-Ended Programming Exercises with LLMs
作者: Mehmet Arif Demirtaş, Claire Zheng, Max Fowler, Kathryn Cunningham
分类: cs.CL, cs.AI
发布日期: 2025-04-11
备注: Accepted as full paper at AIED 2025
💡 一句话要点
利用大型语言模型为开放式编程练习生成规划反馈
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 编程教育 自动评分 代码理解 规划反馈
📋 核心要点
- 开放式编程练习缺乏对学生规划过程的反馈,现有自动评分侧重于最终代码的正确性。
- 利用大型语言模型检测学生代码中的高层次目标和编程模式,即使代码存在语法错误。
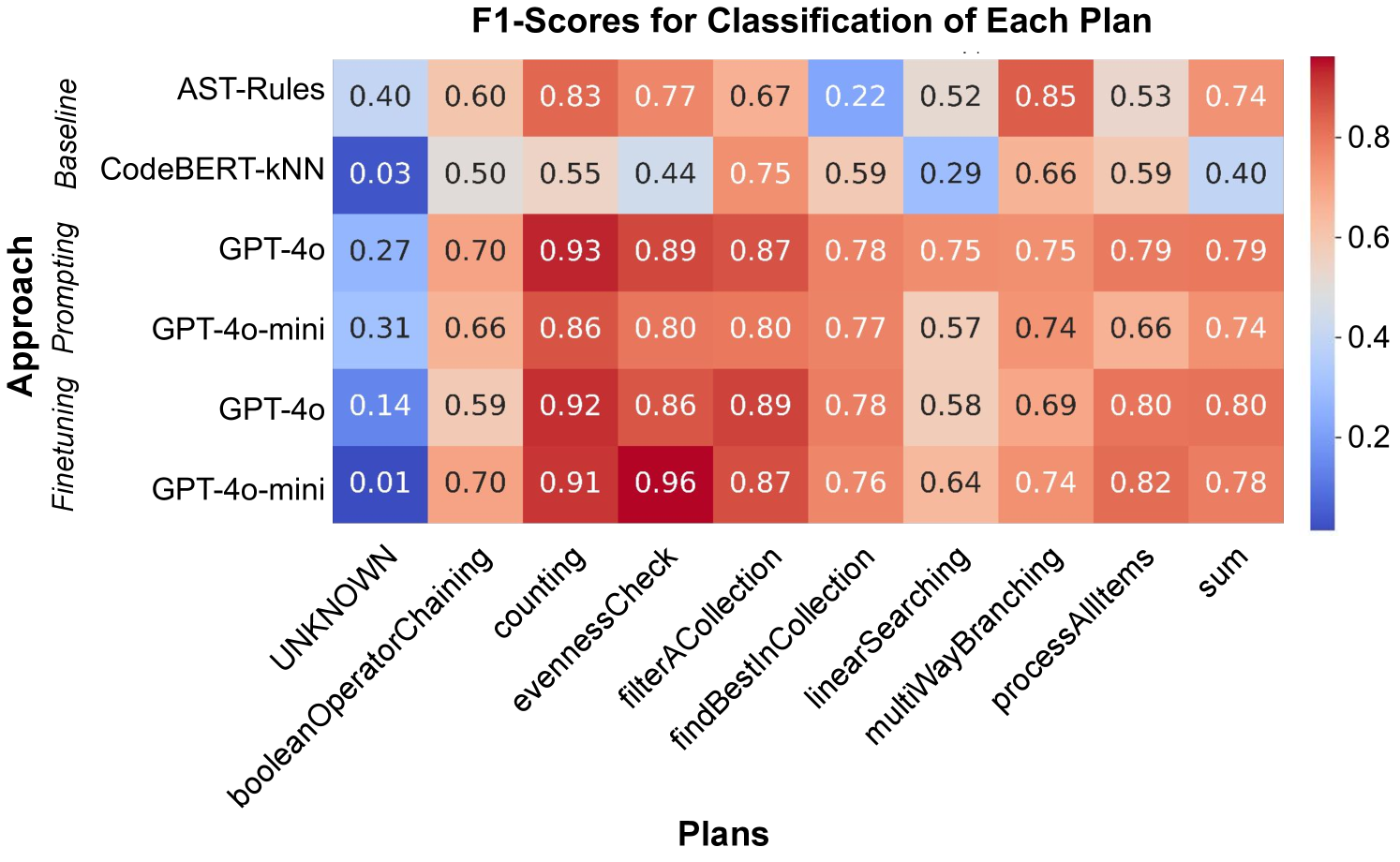
- GPT-4o及其小型变体GPT-4o-mini在检测编程计划方面表现出色,微调后的GPT-4o-mini可媲美GPT-4o。
📝 摘要(中文)
为了完成开放式编程练习,学生既需要规划高层次的解决方案,也需要使用正确的语法来实现它。然而,这些问题通常通过测试用例自动评分最终提交的正确性,学生无法获得关于他们规划过程的反馈。大型语言模型(LLM)可能能够通过检测整体代码结构来生成这种反馈,即使提交的代码存在语法错误。为此,我们提出了一种方法,利用LLM检测学生程序中存在哪些高层次的目标和模式(即编程计划)。我们表明,完整的GPT-4o模型和一个小型变体(GPT-4o-mini)都能以惊人的准确性检测到这些计划,优于受传统代码分析方法启发的基线。我们进一步表明,更小、更具成本效益的变体(GPT-4o-mini)在微调后取得了与最先进模型(GPT-4o)相当的结果,为小型模型在实时评分中的应用带来了有希望的意义。这些较小的模型可以被纳入开放式代码编写练习的自动评分器中,为学生隐式的规划技能提供反馈,即使他们的程序在语法上不正确。此外,LLM可能有助于为其他领域的问题提供反馈,在这些领域中,学生从一组高层次的解决方案步骤开始,并迭代地计算输出,例如数学和物理问题。
🔬 方法详解
问题定义:论文旨在解决开放式编程练习中,学生缺乏规划过程反馈的问题。现有的自动评分系统主要关注最终代码的正确性,忽略了学生在问题解决过程中的规划和设计阶段。这种缺乏反馈的情况阻碍了学生编程能力的全面发展。
核心思路:论文的核心思路是利用大型语言模型(LLMs)理解和识别学生代码中的高层次编程计划(programming plans),即学生在解决问题时采用的算法和逻辑结构。即使代码存在语法错误,LLM仍能通过语义理解来推断学生的意图。
技术框架:该方法主要包含以下几个阶段:1) 输入学生提交的可能包含语法错误的代码;2) 使用LLM(如GPT-4o或GPT-4o-mini)分析代码,识别其中蕴含的编程计划;3) 将LLM的识别结果与预定义的编程计划进行比对,评估学生是否正确地使用了这些计划;4) 根据评估结果,生成针对学生规划过程的反馈。
关键创新:该研究的关键创新在于利用LLM进行代码理解,从而为学生提供关于其规划过程的反馈。与传统的代码分析方法相比,LLM具有更强的语义理解能力,能够处理包含语法错误的代码,并识别出学生的高层次意图。此外,研究还探索了小型LLM在代码理解方面的潜力,并验证了通过微调可以使其达到与大型LLM相当的性能。
关键设计:研究中使用了GPT-4o和GPT-4o-mini两种LLM。GPT-4o代表了当前最先进的性能,而GPT-4o-mini则更具成本效益。研究人员通过微调GPT-4o-mini,使其在编程计划识别任务上达到与GPT-4o相当的性能。具体的微调策略和参数设置在论文中可能有所描述(未知)。此外,如何定义和表示编程计划,以及如何设计LLM的输入提示(prompts)也是关键的设计细节(未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GPT-4o和GPT-4o-mini在检测编程计划方面表现出色,优于传统代码分析方法。更重要的是,通过微调,GPT-4o-mini可以达到与GPT-4o相当的性能,这为在资源受限的环境中使用LLM进行代码理解和反馈提供了可能性。具体的性能提升幅度在论文中可能有所描述(未知)。
🎯 应用场景
该研究成果可应用于在线编程教育平台,为学生提供实时的规划反馈,帮助他们提高编程技能。此外,该方法还可以扩展到其他需要高层次规划的领域,如数学、物理等,为学生提供更全面的学习支持。未来,该技术有望促进个性化学习和智能辅导系统的发展。
📄 摘要(原文)
To complete an open-ended programming exercise, students need to both plan a high-level solution and implement it using the appropriate syntax. However, these problems are often autograded on the correctness of the final submission through test cases, and students cannot get feedback on their planning process. Large language models (LLM) may be able to generate this feedback by detecting the overall code structure even for submissions with syntax errors. To this end, we propose an approach that detects which high-level goals and patterns (i.e. programming plans) exist in a student program with LLMs. We show that both the full GPT-4o model and a small variant (GPT-4o-mini) can detect these plans with remarkable accuracy, outperforming baselines inspired by conventional approaches to code analysis. We further show that the smaller, cost-effective variant (GPT-4o-mini) achieves results on par with state-of-the-art (GPT-4o) after fine-tuning, creating promising implications for smaller models for real-time grading. These smaller models can be incorporated into autograders for open-ended code-writing exercises to provide feedback for students' implicit planning skills, even when their program is syntactically incorrect. Furthermore, LLMs may be useful in providing feedback for problems in other domains where students start with a set of high-level solution steps and iteratively compute the output, such as math and physics problems.