Playpen: An Environment for Exploring Learning Through Conversational Interaction
作者: Nicola Horst, Davide Mazzaccara, Antonia Schmidt, Michael Sullivan, Filippo Momentè, Luca Franceschetti, Philipp Sadler, Sherzod Hakimov, Alberto Testoni, Raffaella Bernardi, Raquel Fernández, Alexander Koller, Oliver Lemon, David Schlangen, Mario Giulianelli, Alessandro Suglia
分类: cs.CL
发布日期: 2025-04-11 (更新: 2025-09-24)
备注: Accepted at EMNLP 2025 (Main) Source code: https://github.com/lm-playpen/playpen Please send correspodence to: lm-playschool@googlegroups.com
💡 一句话要点
Playpen:一个通过对话交互探索学习的环境,用于LLM的后训练。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对话游戏 大型语言模型 后训练 强化学习 自博弈
📋 核心要点
- 现有大型语言模型后训练方法依赖奖励模型判断回复的适当性,但缺乏利用对话交互本身作为反馈信号的探索。
- Playpen环境通过对话游戏自博弈,为LLM提供交互式学习机会,探索监督微调、直接策略优化和强化学习等后训练方法。
- 实验表明,监督微调提升了特定任务性能,但损害了其他能力,而基于GRPO的强化学习实现了更平衡的性能提升。
📝 摘要(中文)
本文探讨了对话游戏(以口头行为为主导、目标明确且规则明确的活动)是否可以作为学习的反馈信号来源,用于大型语言模型(LLM)的后训练。我们介绍了一个名为Playpen的环境,用于通过对话游戏自博弈进行离线和在线学习,并研究了一组具有代表性的后训练方法:监督微调(SFT)、直接策略优化(DPO)和基于GRPO的强化学习。我们实验性地对一个小型LLM(Llama-3.1-8B-Instruct)进行后训练,评估其在未见过的训练游戏实例、未见过的游戏以及标准基准上的性能。结果表明,通过SFT进行的模仿学习提高了在未见过的实例上的性能,但对其他技能产生了负面影响,而使用GRPO进行的交互式学习显示出平衡的改进,且没有损失技能。我们发布了该框架和基线训练设置,以促进在(合成)交互中学习这一有前景的新方向的研究。
🔬 方法详解
问题定义:论文旨在探索如何利用对话游戏中的交互作为反馈信号,提升大型语言模型的后训练效果。现有方法主要依赖奖励模型,而忽略了对话本身蕴含的丰富信息。痛点在于,如何设计有效的对话交互机制,并将其转化为可用于模型训练的信号,从而提升模型的泛化能力和综合性能。
核心思路:论文的核心思路是利用对话游戏自博弈,构建一个可控的交互式学习环境。通过定义明确的游戏规则和目标,让模型在与自身或其他模型进行对话的过程中,学习如何更好地完成任务,并根据游戏结果获得反馈信号。这种方法模拟了人类学习的过程,能够更有效地提升模型的对话能力和策略性思维。
技术框架:Playpen环境包含以下主要模块:1) 对话游戏引擎,负责定义游戏规则、状态转移和奖励机制;2) LLM代理,作为参与游戏的智能体,负责生成对话内容;3) 后训练模块,负责利用对话数据对LLM进行微调或强化学习。整体流程是:LLM代理在游戏引擎中进行自博弈,生成对话数据,然后利用这些数据进行监督微调(SFT)、直接策略优化(DPO)或基于GRPO的强化学习。
关键创新:论文的关键创新在于提出了利用对话游戏自博弈进行LLM后训练的方法。与传统的奖励模型方法相比,该方法能够更自然地利用对话交互中的信息,避免了人工设计奖励函数的困难。此外,Playpen环境提供了一个可控的实验平台,方便研究人员探索不同的对话策略和后训练算法。
关键设计:论文中,对话游戏的设计需要考虑游戏规则的合理性、奖励机制的有效性以及对话数据的多样性。在后训练方面,SFT使用交叉熵损失函数,DPO使用pairwise ranking loss,GRPO使用advantage actor-critic算法。具体的参数设置和网络结构根据不同的后训练方法进行调整。例如,在GRPO中,需要设计合适的奖励函数,以引导模型学习有效的对话策略。
🖼️ 关键图片

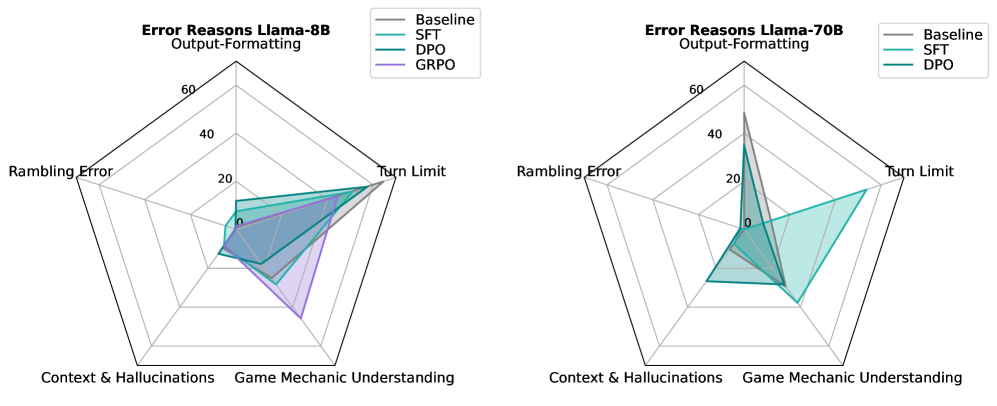
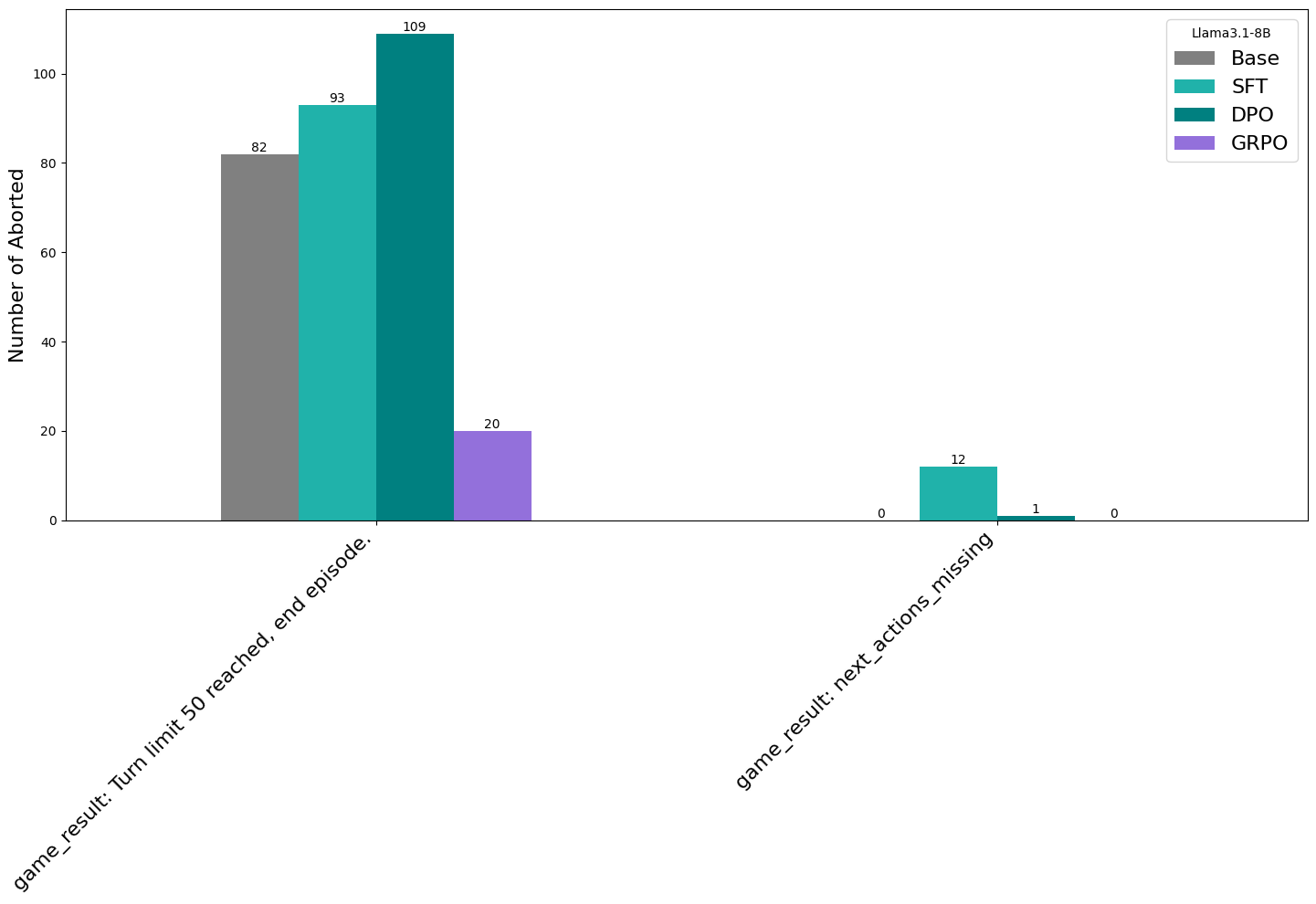
📊 实验亮点
实验结果表明,通过监督微调(SFT)可以提高模型在未见过的游戏实例上的性能,但会损害其他技能。而使用基于GRPO的强化学习,可以在不损失其他技能的前提下,实现更平衡的性能提升。这表明交互式学习在提升LLM的综合能力方面具有潜力。
🎯 应用场景
该研究成果可应用于智能对话系统、游戏AI、教育机器人等领域。通过对话游戏进行模型训练,可以提升对话系统的流畅性、逻辑性和策略性,使其能够更好地与用户进行交互。在教育领域,可以利用该方法训练个性化辅导机器人,根据学生的学习情况进行针对性指导。
📄 摘要(原文)
Interaction between learner and feedback-giver has come into focus recently for post-training of Large Language Models (LLMs), through the use of reward models that judge the appropriateness of a model's response. In this paper, we investigate whether Dialogue Games -- goal-directed and rule-governed activities driven predominantly by verbal actions -- can also serve as a source of feedback signals for learning. We introduce Playpen, an environment for off- and online learning through Dialogue Game self-play, and investigate a representative set of post-training methods: supervised fine-tuning; direct alignment (DPO); and reinforcement learning with GRPO. We experiment with post-training a small LLM (Llama-3.1-8B-Instruct), evaluating performance on unseen instances of training games as well as unseen games, and on standard benchmarks. We find that imitation learning through SFT improves performance on unseen instances, but negatively impacts other skills, while interactive learning with GRPO shows balanced improvements without loss of skills. We release the framework and the baseline training setups to foster research in the promising new direction of learning in (synthetic) interaction.