Harnessing the Unseen: The Hidden Influence of Intrinsic Knowledge in Long-Context Language Models
作者: Yu Fu, Haz Sameen Shahgir, Hui Liu, Xianfeng Tang, Qi He, Yue Dong
分类: cs.CL
发布日期: 2025-04-11
备注: 21 pages,11figures
💡 一句话要点
长文本模型中固有知识影响被忽视,提出混合检索评估方法并验证Qwen-2.5的优越性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本模型 固有知识 外部检索 内部检索 混合评估 Qwen-2.5 Llama-3.1
📋 核心要点
- 现有长文本模型主要关注外部上下文利用,忽略了模型自身固有知识的影响,限制了模型的潜力。
- 论文提出一种混合检索评估方法,同时考察模型利用外部上下文和自身固有知识的能力。
- 实验表明,Qwen-2.5模型在固有检索能力上优于Llama-3.1模型,即使是更大的Llama-3.1-70B-Instruct模型也未表现出优势。
📝 摘要(中文)
长文本模型(LCMs)旨在处理极长的输入上下文,但现有研究主要关注利用外部上下文信息,往往忽略了大型语言模型固有知识的影响。本文研究了这种固有知识如何影响内容生成,并证明其影响随着上下文长度的增加而变得更加明显。此外,研究表明模型利用固有知识的能力(称为固有检索能力)并没有随着其通过外部检索能力利用上下文知识的能力同步提高。更强的外部检索能力甚至会干扰模型有效利用自身知识的能力,限制其潜力。为了弥合这一差距,我们设计了一个简单而有效的混合“大海捞针”测试,该测试基于模型在两种检索能力上的表现进行评估,而不是仅仅强调外部检索能力。实验结果表明,Qwen-2.5模型明显优于Llama-3.1模型,表现出更强的固有检索能力。此外,即使是更强大的Llama-3.1-70B-Instruct模型也未能表现出更好的LCM性能,突出了从双重检索角度评估模型的重要性。
🔬 方法详解
问题定义:现有长文本模型的研究主要集中在如何有效地利用外部上下文信息,而忽略了模型自身所具备的固有知识在长文本生成中的作用。这种忽略导致模型在长文本处理中可能无法充分发挥其潜力,甚至可能因为过度依赖外部信息而降低了生成质量。现有评估方法也主要关注外部信息检索能力,缺乏对模型固有知识利用能力的评估。
核心思路:论文的核心思路是强调长文本模型应该同时具备有效的外部信息检索能力和强大的固有知识利用能力。模型不仅要能够从长上下文中提取相关信息,还要能够有效地利用自身已有的知识来生成高质量的内容。论文认为,这两种能力是相互补充的,并且需要同时进行评估和优化。
技术框架:论文提出了一个混合“大海捞针”测试框架,用于同时评估模型的外部信息检索能力(extrinsic retrieval ability)和固有知识利用能力(intrinsic retrieval ability)。该测试框架通过在长上下文中插入“needle”信息,并要求模型根据上下文生成包含该信息的内容,从而评估模型的外部信息检索能力。同时,该框架还设计了一些问题,需要模型利用自身已有的知识来回答,从而评估模型的固有知识利用能力。
关键创新:论文的关键创新在于提出了一个同时评估长文本模型外部信息检索能力和固有知识利用能力的混合测试框架。该框架能够更全面地评估模型的长文本处理能力,并帮助研究人员更好地理解模型在长文本处理中的行为。此外,论文还发现,更强的外部信息检索能力可能会干扰模型对自身固有知识的利用,这是一个重要的发现。
关键设计:混合“大海捞针”测试的关键设计在于同时考察模型对外部上下文信息和内部固有知识的利用。具体来说,测试包含两部分:一部分是传统的“大海捞针”测试,用于评估模型从长上下文中检索特定信息的能力;另一部分是设计一些需要模型利用自身知识才能回答的问题,用于评估模型的固有知识利用能力。通过综合评估这两部分的结果,可以更全面地了解模型的长文本处理能力。
🖼️ 关键图片
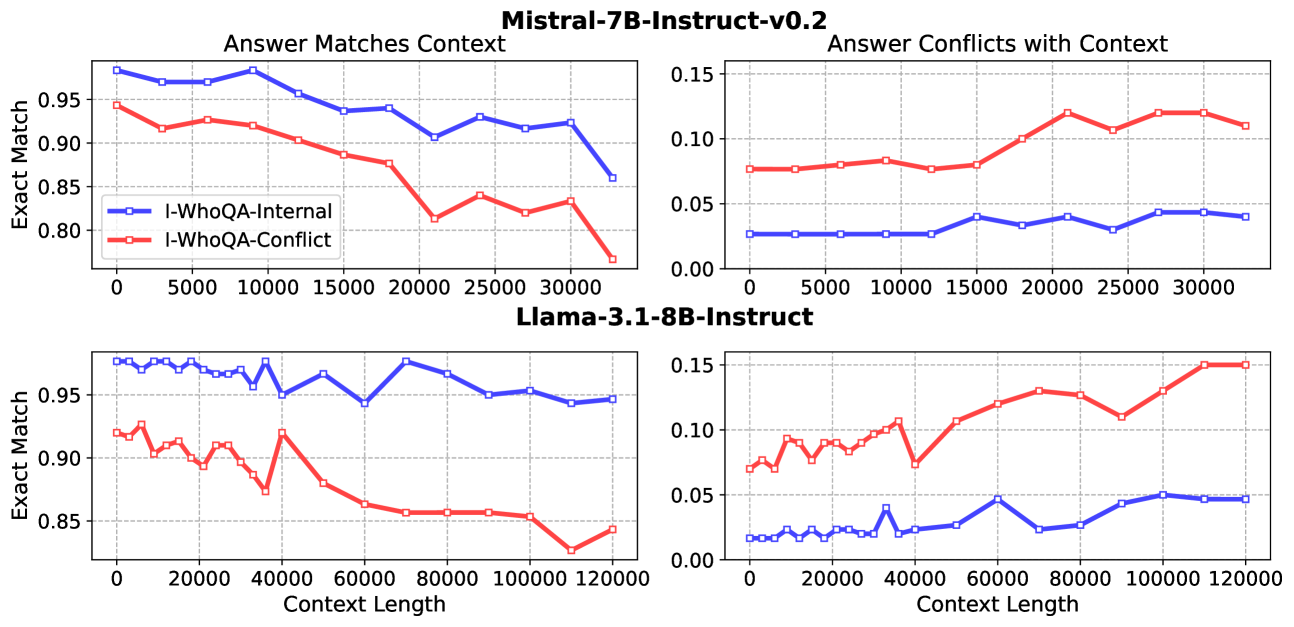


📊 实验亮点
实验结果表明,Qwen-2.5模型在混合“大海捞针”测试中表现优于Llama-3.1模型,尤其是在固有知识利用能力方面。即使是更大的Llama-3.1-70B-Instruct模型也未能表现出更好的性能,这表明仅仅增加模型参数并不能有效提升其长文本处理能力,而需要更加关注模型对固有知识的利用。这一发现强调了从双重检索角度评估长文本模型的重要性。
🎯 应用场景
该研究成果可应用于各种需要长文本处理的场景,例如长篇小说生成、科技报告撰写、法律文档分析等。通过提升模型对固有知识的利用能力,可以提高生成内容的质量和相关性,减少对外部信息的过度依赖。未来的研究可以进一步探索如何更好地融合外部信息和固有知识,以实现更智能、更高效的长文本处理。
📄 摘要(原文)
Recent advances in long-context models (LCMs), designed to handle extremely long input contexts, primarily focus on utilizing external contextual information, often leaving the influence of large language models' intrinsic knowledge underexplored. In this work, we investigate how this intrinsic knowledge affects content generation and demonstrate that its impact becomes increasingly pronounced as context length extends. Furthermore, we show that the model's ability to utilize intrinsic knowledge, which we call intrinsic retrieval ability, does not improve simultaneously with its ability to leverage contextual knowledge through extrinsic retrieval ability. Moreover, better extrinsic retrieval can interfere with the model's ability to use its own knowledge effectively, limiting its full potential. To bridge this gap, we design a simple yet effective Hybrid Needle-in-a-Haystack test that evaluates models based on their capabilities across both retrieval abilities, rather than solely emphasizing extrinsic retrieval ability. Our experimental results reveal that Qwen-2.5 models significantly outperform Llama-3.1 models, demonstrating superior intrinsic retrieval ability. Moreover, even the more powerful Llama-3.1-70B-Instruct model fails to exhibit better performance under LCM conditions, highlighting the importance of evaluating models from a dual-retrieval perspective.