Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
作者: Yichun Yin, Wenyong Huang, Kaikai Song, Yehui Tang, Xueyu Wu, Wei Guo, Peng Guo, Yaoyuan Wang, Xiaojun Meng, Yasheng Wang, Dong Li, Can Chen, Dandan Tu, Yin Li, Fisher Yu, Ruiming Tang, Yunhe Wang, Baojun Wang, Bin Wang, Bo Wang, Boxiao Liu, Changzheng Zhang, Duyu Tang, Fei Mi, Hui Jin, Jiansheng Wei, Jiarui Qin, Jinpeng Li, Jun Zhao, Liqun Deng, Lin Li, Minghui Xu, Naifu Zhang, Nianzu Zheng, Qiang Li, Rongju Ruan, Shengjun Cheng, Tianyu Guo, Wei He, Wei Li, Weiwen Liu, Wulong Liu, Xinyi Dai, Yonghan Dong, Yu Pan, Yue Li, Yufei Wang, Yujun Li, Yunsheng Ni, Zhe Liu, Zhenhe Zhang, Zhicheng Liu
分类: cs.CL, cs.AI
发布日期: 2025-04-10 (更新: 2025-04-11)
备注: fix conflicts of latex pacakges
💡 一句话要点
盘古Ultra:在昇腾NPU上突破稠密大语言模型的极限
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 昇腾NPU 深度学习 Transformer 模型训练
📋 核心要点
- 现有大语言模型训练面临规模扩展带来的优化和系统挑战,训练过程不稳定,容易出现损失尖峰。
- 论文提出深度缩放的三明治归一化方法,有效消除深度模型训练中的损失尖峰,稳定训练过程。
- 盘古Ultra在多个基准测试中超越Llama 405B和Mistral Large 2等稠密模型,性能与DeepSeek-R1等稀疏模型相当。
📝 摘要(中文)
本文介绍了盘古Ultra,一个拥有1350亿参数的稠密Transformer大语言模型(LLM),该模型在昇腾神经处理单元(NPU)上进行训练。近年来,LLM领域在规模和能力上取得了前所未有的进展,但训练如此大规模的模型仍然面临着重大的优化和系统挑战。为了稳定训练过程,我们提出了一种深度缩放的“三明治”归一化方法,有效地消除了深度模型训练过程中的损失尖峰。我们使用13.2万亿个多样化和高质量的tokens对模型进行预训练,并在后训练阶段进一步增强其推理能力。为了高效地执行如此大规模的训练,我们利用了8192个昇腾NPU,并进行了一系列系统优化。在多个不同基准上的评估表明,盘古Ultra显著提升了稠密LLM(如Llama 405B和Mistral Large 2)的性能,甚至达到了与DeepSeek-R1(其稀疏模型结构包含更多参数)相媲美的结果。我们的探索表明,昇腾NPU能够高效且有效地训练超过1000亿参数的稠密模型。我们的模型和系统将提供给我们的商业客户。
🔬 方法详解
问题定义:现有大语言模型在训练过程中,随着模型深度的增加,训练过程变得不稳定,容易出现损失尖峰,影响模型收敛和最终性能。这主要是由于梯度消失或爆炸等问题引起的,需要有效的归一化方法来缓解。
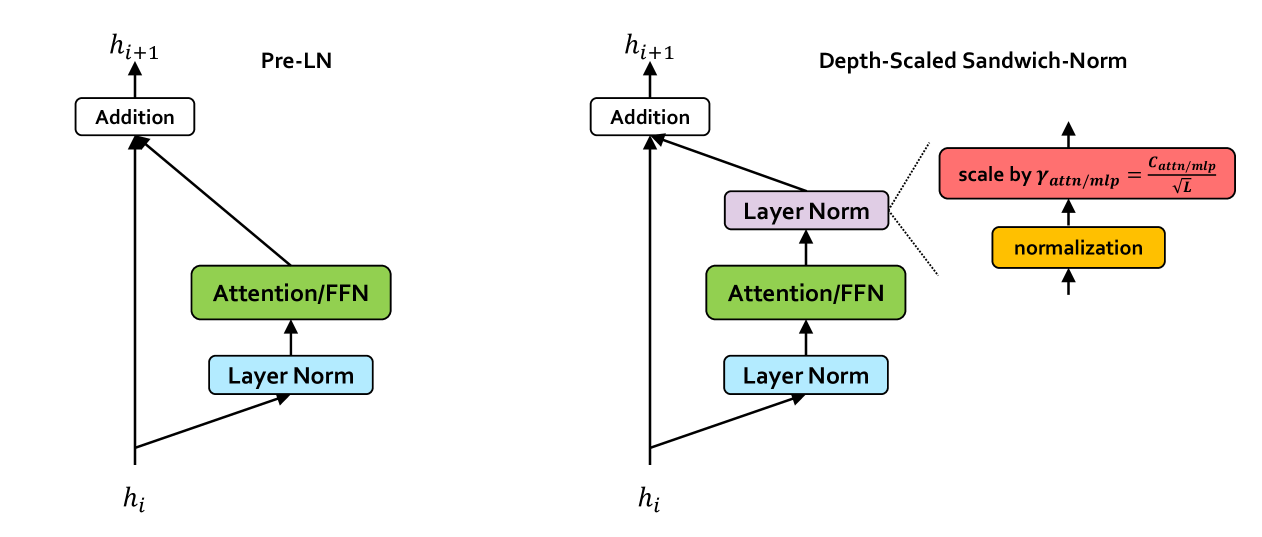
核心思路:论文的核心思路是提出一种深度缩放的三明治归一化方法,该方法在Transformer模块的输入和输出都进行归一化,并根据网络深度对归一化参数进行缩放。这种方法可以有效地控制梯度的范围,避免梯度消失或爆炸,从而稳定训练过程。
技术框架:盘古Ultra的整体架构是一个标准的Transformer模型,包含多个Transformer层。每个Transformer层包括自注意力模块和前馈神经网络模块。在每个模块的输入和输出都应用了深度缩放的三明治归一化方法。整个模型在8192个昇腾NPU上进行分布式训练。
关键创新:论文最重要的技术创新点是深度缩放的三明治归一化方法。与传统的归一化方法(如LayerNorm或BatchNorm)不同,该方法不仅在输入端进行归一化,还在输出端进行归一化,形成一个“三明治”结构。此外,该方法还根据网络深度对归一化参数进行缩放,使得不同深度的层能够更好地适应不同的梯度范围。
关键设计:深度缩放的三明治归一化方法的具体实现如下:对于第l层的Transformer模块,其输入为x_l,输出为y_l。首先对输入进行归一化:x_l' = LayerNorm(x_l)。然后将x_l'输入到Transformer模块中,得到输出y_l。接着对输出进行归一化:y_l' = LayerNorm(y_l)。最后,将y_l'乘以一个深度缩放因子:y_l'' = scale_l * y_l',其中scale_l是一个与层数l相关的参数。损失函数采用标准的交叉熵损失函数。
🖼️ 关键图片


📊 实验亮点
盘古Ultra在多个基准测试中取得了显著的成果。例如,在某些测试中,它超越了Llama 405B和Mistral Large 2等稠密模型,并且达到了与DeepSeek-R1等稀疏模型相当的性能。这些结果表明,盘古Ultra在稠密模型中具有很强的竞争力,并且证明了昇腾NPU能够有效地训练大规模的语言模型。
🎯 应用场景
盘古Ultra作为一款高性能的大语言模型,具有广泛的应用前景。它可以应用于自然语言处理的各个领域,如文本生成、机器翻译、问答系统、对话系统等。此外,它还可以作为基础模型,通过微调或迁移学习的方式,应用于各种特定任务。该研究成果将推动大语言模型在商业领域的应用,为客户提供更强大的AI能力。
📄 摘要(原文)
We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.