Zero-Shot Cross-Domain Code Search without Fine-Tuning
作者: Keyu Liang, Zhongxin Liu, Chao Liu, Zhiyuan Wan, David Lo, Xiaohu Yang
分类: cs.SE, cs.CL
发布日期: 2025-04-10
DOI: 10.1145/3729357
💡 一句话要点
提出CodeBridge,一种无需微调的零样本跨领域代码搜索方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码搜索 跨领域学习 零样本学习 预训练语言模型 大型语言模型 代码注释 信息检索
📋 核心要点
- 现有跨领域代码搜索方法依赖于昂贵的微调或面临零样本性能下降,限制了其在资源受限场景下的应用。
- CodeBridge将查询-代码匹配分解为查询-注释和代码-代码匹配,利用三种匹配模式的互补性,实现零样本跨领域搜索。
- 实验表明,CodeBridge在MRR指标上显著优于现有PLM方法,并能与需要微调的RAPID方法相媲美。
📝 摘要(中文)
代码搜索旨在为自然语言查询检索语义相关的代码片段。虽然预训练语言模型(PLM)在此任务中表现出色,但它们在跨领域场景中表现不佳,通常需要昂贵的微调或在零样本设置中面临性能下降。RAPID是目前唯一有效的零样本跨领域代码搜索方法,它生成合成数据用于模型微调。尽管有效,RAPID需要大量的计算资源进行微调,并且需要为每个领域维护专门的模型,这突显了对零样本、无需微调的跨领域代码搜索方法的需求。本文提出将代码搜索的查询-代码匹配过程分解为两个更简单的任务:查询-注释匹配和代码-代码匹配。实证研究表明,查询-代码、查询-注释和代码-代码匹配这三种匹配模式在零样本跨领域设置中具有很强的互补性。基于这些发现,我们提出CodeBridge,一种零样本、无需微调的跨领域代码搜索方法。具体来说,CodeBridge使用大型语言模型(LLM)生成注释和伪代码,然后通过基于PLM的相似性评分和基于采样的融合来组合查询-代码、查询-注释和代码-代码匹配。实验结果表明,我们的方法在三个数据集上的MRR平均优于最先进的基于PLM的代码搜索方法(即CoCoSoDa和UniXcoder)21.4%和24.9%。我们的方法也产生了比零样本跨领域代码搜索方法RAPID更好或相当的结果,而RAPID需要昂贵的微调。
🔬 方法详解
问题定义:论文旨在解决零样本跨领域代码搜索问题。现有方法,如直接使用预训练语言模型(PLM)进行查询-代码匹配,在跨领域场景下性能显著下降。而RAPID等方法虽然有效,但需要针对每个领域进行代价高昂的微调,限制了其应用范围。
核心思路:论文的核心思路是将复杂的查询-代码匹配问题分解为两个更简单的子问题:查询-注释匹配和代码-代码匹配。通过利用大型语言模型(LLM)生成代码注释和伪代码,从而建立查询和代码之间的桥梁。这种分解能够有效利用不同匹配模式的互补性,提升跨领域搜索的性能。
技术框架:CodeBridge的整体框架包含以下几个主要步骤:1) 使用大型语言模型(LLM)为代码生成注释和伪代码;2) 利用预训练语言模型(PLM)计算查询-代码、查询-注释和代码-代码之间的相似度得分;3) 使用基于采样的融合策略,将三种相似度得分进行有效融合,得到最终的排序结果。
关键创新:CodeBridge的关键创新在于其分解匹配问题的思想,以及利用LLM生成注释和伪代码来弥合领域差异。与直接进行查询-代码匹配的方法不同,CodeBridge通过引入中间表示(注释和伪代码),使得模型能够更好地理解查询和代码的语义关系,从而提升跨领域搜索的泛化能力。
关键设计:CodeBridge的关键设计包括:1) 使用高质量的LLM(具体模型未知)生成准确且信息丰富的注释和伪代码;2) 选择合适的PLM(具体模型未知)来计算不同匹配模式下的相似度得分;3) 设计有效的采样融合策略,以平衡不同匹配模式的贡献,并优化最终的排序结果。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细说明。
🖼️ 关键图片
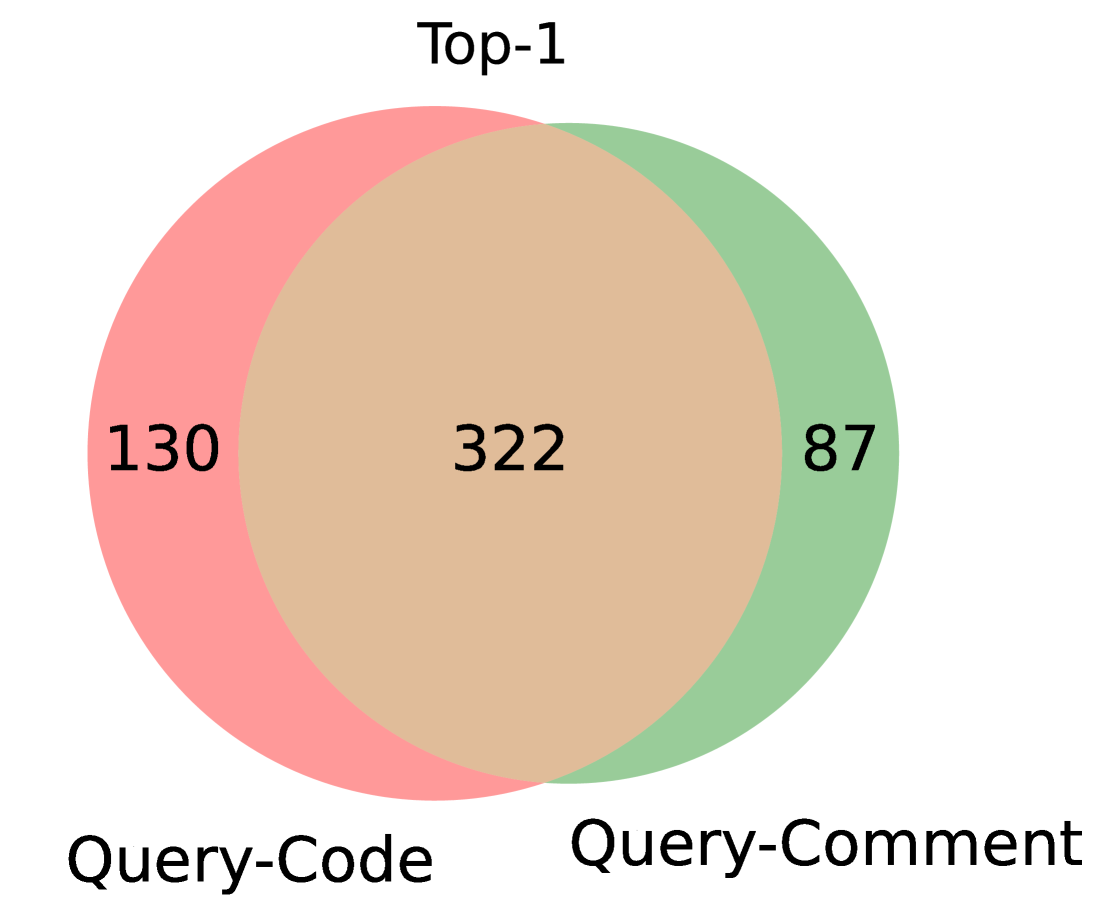
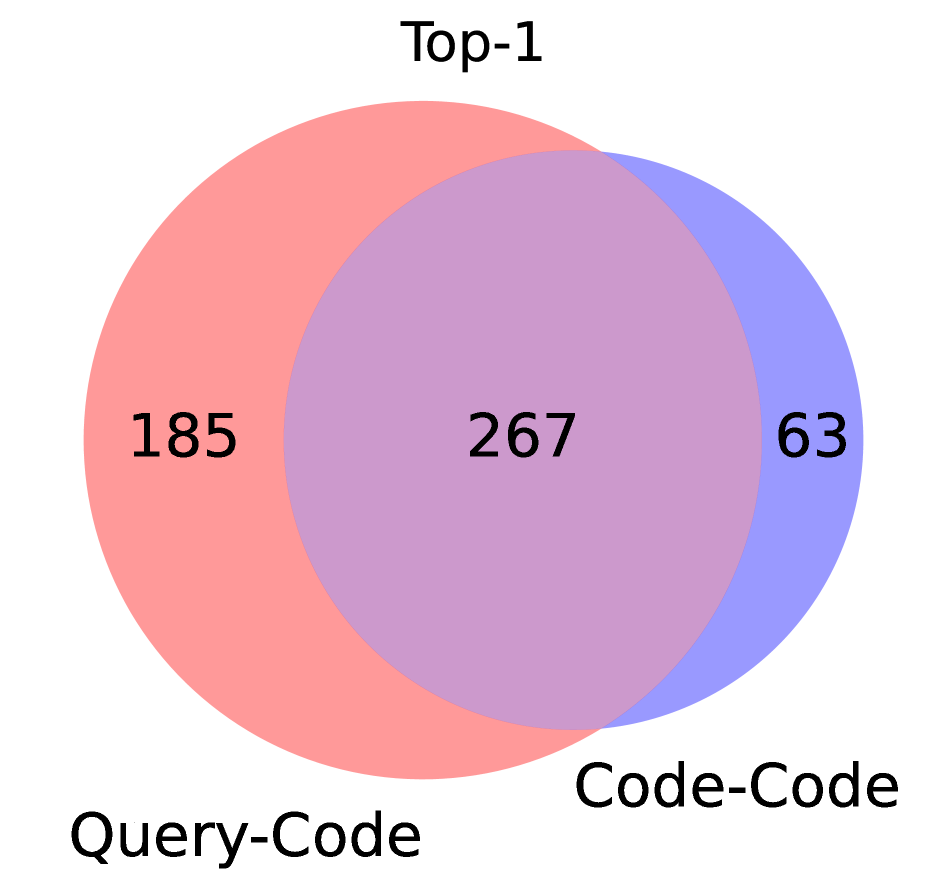
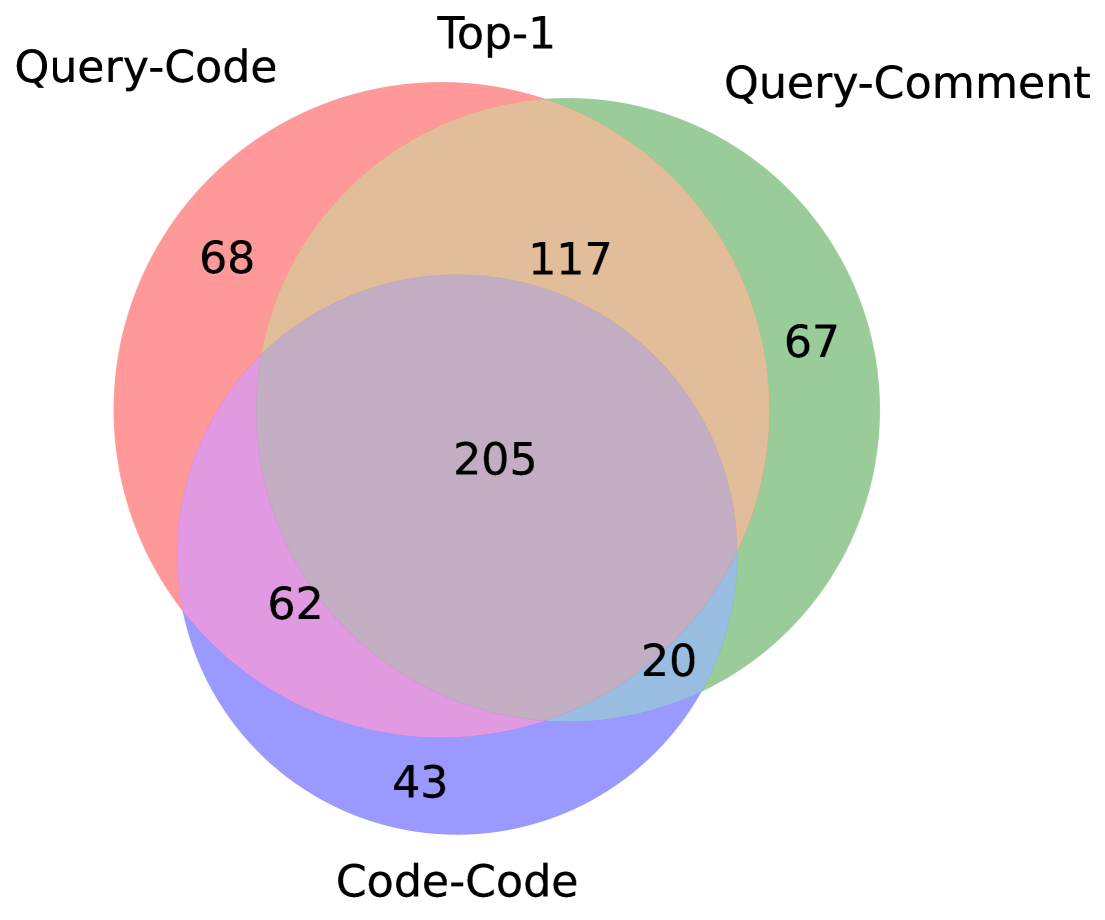
📊 实验亮点
实验结果表明,CodeBridge在三个数据集上的MRR指标上,平均优于CoCoSoDa 21.4%,优于UniXcoder 24.9%。更重要的是,CodeBridge在零样本设置下,取得了与需要昂贵微调的RAPID方法相当甚至更好的性能,证明了其在跨领域代码搜索方面的有效性。
🎯 应用场景
CodeBridge可应用于各种软件开发场景,例如在不同的编程语言或软件项目中进行代码搜索,帮助开发者快速找到所需的代码片段。该方法无需针对特定领域进行微调,降低了部署成本,并提高了代码搜索的效率和准确性,具有广泛的应用前景。
📄 摘要(原文)
Code search aims to retrieve semantically relevant code snippets for natural language queries. While pre-trained language models (PLMs) have shown remarkable performance in this task, they struggle in cross-domain scenarios, often requiring costly fine-tuning or facing performance drops in zero-shot settings. RAPID, which generates synthetic data for model fine-tuning, is currently the only effective method for zero-shot cross-domain code search. Despite its effectiveness, RAPID demands substantial computational resources for fine-tuning and needs to maintain specialized models for each domain, underscoring the need for a zero-shot, fine-tuning-free approach for cross-domain code search. The key to tackling zero-shot cross-domain code search lies in bridging the gaps among domains. In this work, we propose to break the query-code matching process of code search into two simpler tasks: query-comment matching and code-code matching. Our empirical study reveals the strong complementarity among the three matching schemas in zero-shot cross-domain settings, i.e., query-code, query-comment, and code-code matching. Based on the findings, we propose CodeBridge, a zero-shot, fine-tuning-free approach for cross-domain code search. Specifically, CodeBridge uses Large Language Models (LLMs) to generate comments and pseudo-code, then combines query-code, query-comment, and code-code matching via PLM-based similarity scoring and sampling-based fusion. Experimental results show that our approach outperforms the state-of-the-art PLM-based code search approaches, i.e., CoCoSoDa and UniXcoder, by an average of 21.4% and 24.9% in MRR, respectively, across three datasets. Our approach also yields results that are better than or comparable to those of the zero-shot cross-domain code search approach RAPID, which requires costly fine-tuning.