On the Temporal Question-Answering Capabilities of Large Language Models Over Anonymized Data
作者: Alfredo Garrachón Ruiz, Tomás de la Rosa, Daniel Borrajo
分类: cs.CL, cs.AI
发布日期: 2025-04-10 (更新: 2025-12-02)
备注: 18 pages, 7 tables, 5 figures
💡 一句话要点
提出RATA数据集,研究LLM在匿名时序数据上的推理能力,并验证集成方法的需求。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 时序推理 匿名数据 RATA数据集 思维树 自我反思 代码执行 集成方法
📋 核心要点
- 现有LLM在处理未见过的匿名时序数据推理任务时,能力尚待探索,面临依赖先验知识而非推理的挑战。
- 构建RATA数据集,并探索思维树、自我反思和代码执行等多种方法,评估LLM在匿名时序数据上的推理能力。
- 实验结果表明,仅依靠独立LLM难以实现可靠的时序推理,需要集成多种方法以提升性能。
📝 摘要(中文)
本文探讨了大型语言模型(LLM)在处理训练数据中未出现的时序推理任务中的适用性,重点关注结构化和半结构化的匿名数据。研究不仅开发了直接的LLM流水线,还比较了各种方法并进行了深入分析。研究识别并检验了自然语言中十七种常见的时序推理任务,侧重于它们的算法组成部分。为了评估LLM的性能,创建了“推理和回答时间能力”数据集(RATA),该数据集以半结构化的匿名数据为特征,以确保依赖推理而非先验知识。研究比较了几种方法,包括诸如思维树(Tree-of-Thought)、自我反思(self-reflexion)和代码执行等SoTA技术,并针对此场景进行了专门调整。结果表明,实现可扩展且可靠的解决方案需要的不仅仅是独立的LLM,突出了集成方法的需求。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在处理匿名化的结构化和半结构化时序数据时,进行有效时序推理的问题。现有方法的痛点在于,LLM容易依赖训练数据中的先验知识,而非基于给定的匿名数据进行推理,导致泛化能力不足。此外,如何针对不同的时序推理任务选择合适的LLM使用策略也是一个挑战。
核心思路:论文的核心思路是通过构建一个专门的匿名时序推理数据集(RATA),并结合多种先进的LLM使用策略(如思维树、自我反思和代码执行),来评估和提升LLM在这一任务上的表现。通过匿名化数据,确保LLM必须依赖于给定的数据进行推理,而非利用预训练知识。同时,通过比较不同策略的效果,探索最佳的LLM使用方法。
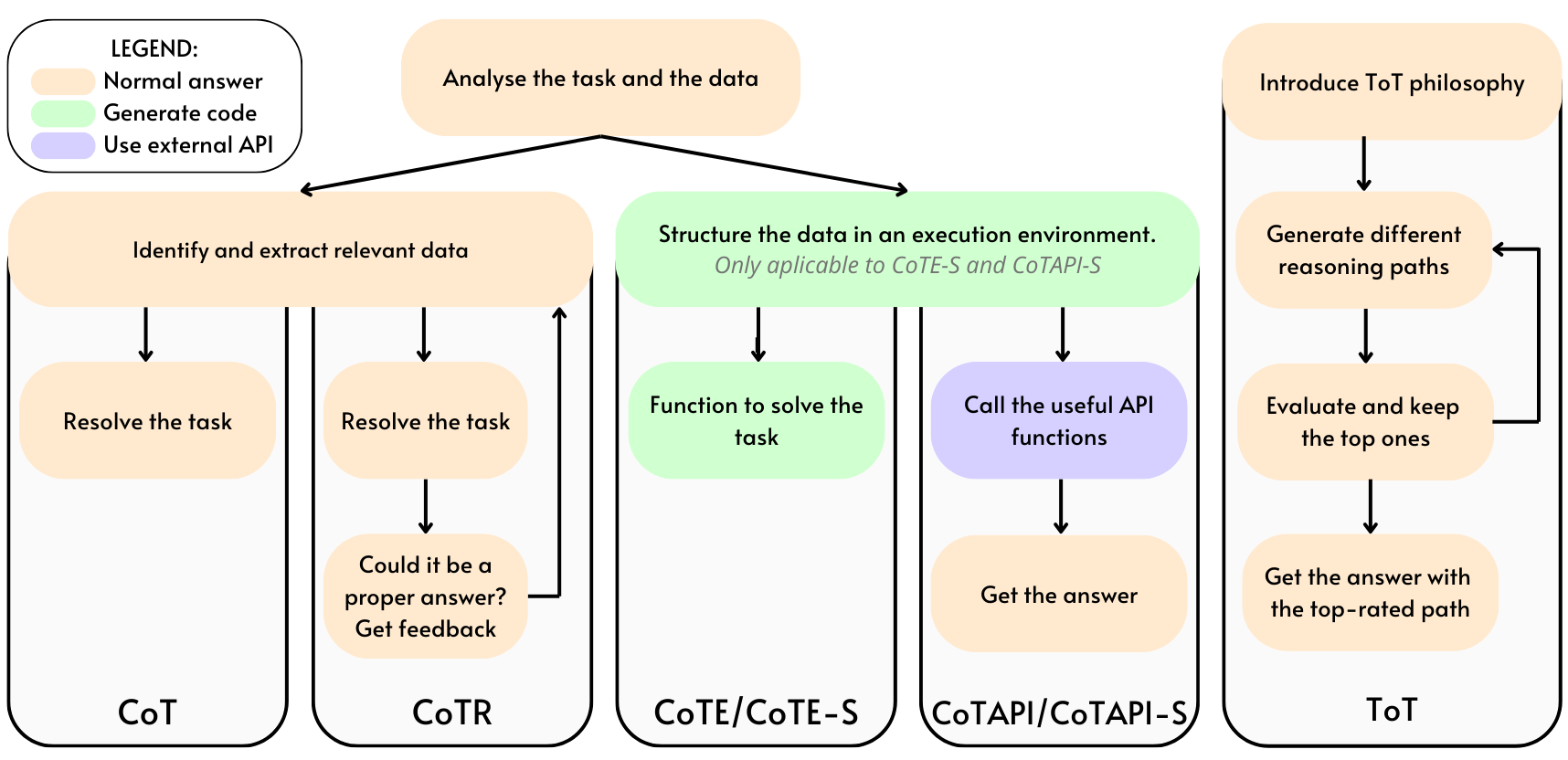
技术框架:整体框架包含以下几个主要步骤:1) 构建RATA数据集,包含多种时序推理任务和匿名化的结构化/半结构化数据;2) 设计不同的LLM流水线,包括直接LLM调用、思维树、自我反思和代码执行等方法;3) 在RATA数据集上评估不同流水线的性能;4) 分析实验结果,找出最佳的LLM使用策略,并探讨集成方法的必要性。
关键创新:论文的关键创新在于:1) 构建了RATA数据集,这是一个专门用于评估LLM在匿名时序数据上推理能力的数据集;2) 系统地比较了多种先进的LLM使用策略在时序推理任务上的表现,并分析了它们的优缺点;3) 强调了集成方法在解决复杂时序推理问题中的重要性。与现有方法相比,该研究更关注LLM在缺乏先验知识情况下的推理能力,并探索了多种提升LLM推理能力的方法。
关键设计:RATA数据集包含17种常见的时序推理任务,涵盖了不同的算法组件。数据集中的数据是半结构化的,并且经过匿名化处理,以确保LLM必须依赖于给定的数据进行推理。在实验中,研究人员针对不同的LLM使用策略进行了参数调整,例如,在思维树方法中,调整了分支数量和搜索深度。对于代码执行方法,研究人员使用了特定的代码解释器和编程语言,并设计了相应的代码模板。
🖼️ 关键图片

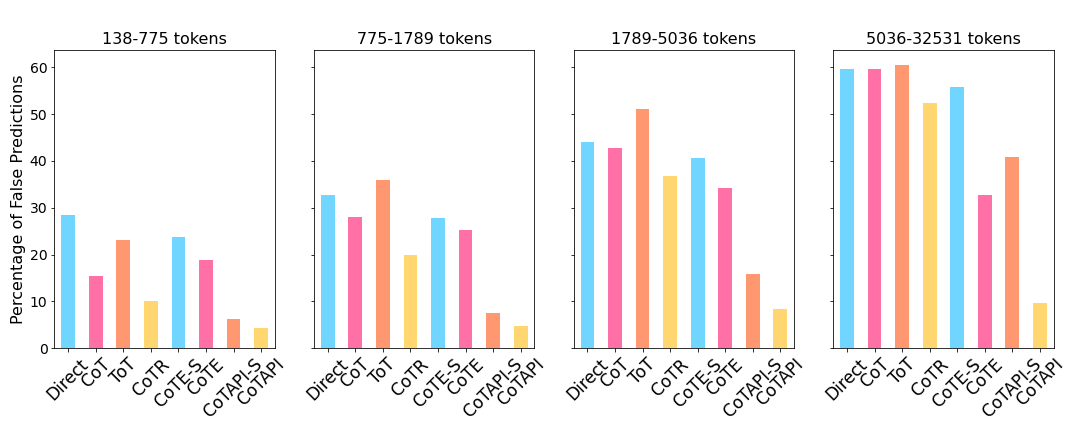
📊 实验亮点
实验结果表明,直接使用LLM在RATA数据集上的表现有限,而采用思维树、自我反思和代码执行等策略可以显著提升LLM的推理能力。然而,即使采用了这些策略,LLM的性能仍然不够理想,表明需要集成多种方法才能实现可靠的时序推理。具体性能数据未知,但论文强调了集成方法的重要性。
🎯 应用场景
该研究成果可应用于金融风控、医疗诊断、供应链管理等领域,在这些领域中,时序数据的分析至关重要,但数据往往需要匿名化处理以保护用户隐私。通过提升LLM在匿名时序数据上的推理能力,可以帮助企业更好地进行决策,同时保护用户隐私。未来的研究可以进一步探索更有效的集成方法,以及如何将LLM与其他推理技术相结合。
📄 摘要(原文)
The applicability of Large Language Models (LLMs) in temporal reasoning tasks over data that is not present during training is still a field that remains to be explored. In this paper we work on this topic, focusing on structured and semi-structured anonymized data. We not only develop a direct LLM pipeline, but also compare various methodologies and conduct an in-depth analysis. We identified and examined seventeen common temporal reasoning tasks in natural language, focusing on their algorithmic components. To assess LLM performance, we created the \textit{Reasoning and Answering Temporal Ability} dataset (RATA), featuring semi-structured anonymized data to ensure reliance on reasoning rather than on prior knowledge. We compared several methodologies, involving SoTA techniques such as Tree-of-Thought, self-reflexion and code execution, tuned specifically for this scenario. Our results suggest that achieving scalable and reliable solutions requires more than just standalone LLMs, highlighting the need for integrated approaches.