Model Utility Law: Evaluating LLMs beyond Performance through Mechanism Interpretable Metric
作者: Yixin Cao, Jiahao Ying, Yaoning Wang, Xipeng Qiu, Xuanjing Huang, Yugang Jiang
分类: cs.CL
发布日期: 2025-04-10 (更新: 2025-05-26)
🔗 代码/项目: GITHUB
💡 一句话要点
提出模型利用率指标MUI,通过神经元激活比例评估LLM,揭示性能与效率的Utility Law。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型评估 模型利用率 机制可解释性 神经元激活 Utility Law
📋 核心要点
- 现有LLM评估方法难以从有限基准推断模型的泛化能力,无法有效衡量模型效率。
- 提出模型利用率指标MUI,通过量化推理过程中激活的神经元比例来衡量模型解决任务的努力程度。
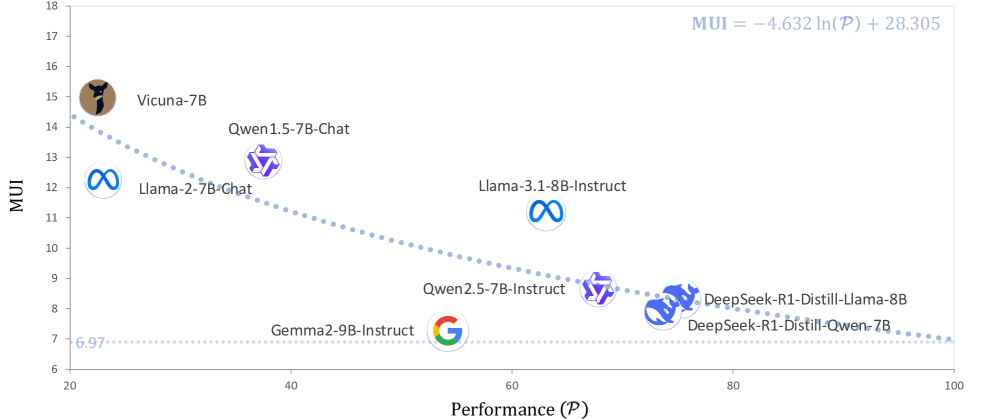
- 实验发现MUI与性能之间存在反向对数关系,即Utility Law,并据此指导模型训练和评估。
📝 摘要(中文)
大型语言模型(LLM)已广泛应用于学术界、工业界和日常应用中,但当前的评估方法难以跟上其快速发展。LLM时代评估的一个核心挑战是泛化问题:如何从有限的基准测试中推断模型近乎无限的能力。本文通过提出模型利用率指标(MUI)来解决这一挑战,MUI是一种机制可解释性增强的指标,可作为传统性能分数的补充。MUI量化了模型在任务上花费的精力,定义为推理过程中激活的神经元或特征的比例。直观地说,一个真正有能力的模型应该以更少的精力实现更高的性能。对流行的LLM进行的大量实验表明,MUI和性能之间存在一致的反向对数关系,我们将其形式化为效用定律(Utility Law)。从这个定律中,我们推导出四个实用的推论,可以(i)指导训练诊断,(ii)揭示数据污染问题,(iii)实现更公平的模型比较,以及(iv)设计模型特定的数据集多样性。代码可在https://github.com/ALEX-nlp/MUI-Eva找到。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)评估主要依赖于性能指标,例如准确率、召回率等。这些指标只能反映模型在特定数据集上的表现,难以推断模型在未见任务上的泛化能力。此外,现有评估方法忽略了模型解决问题的效率,即模型是否以最小的计算代价获得最佳性能。因此,需要一种新的评估方法,能够同时衡量LLM的性能和效率,并揭示两者之间的关系。
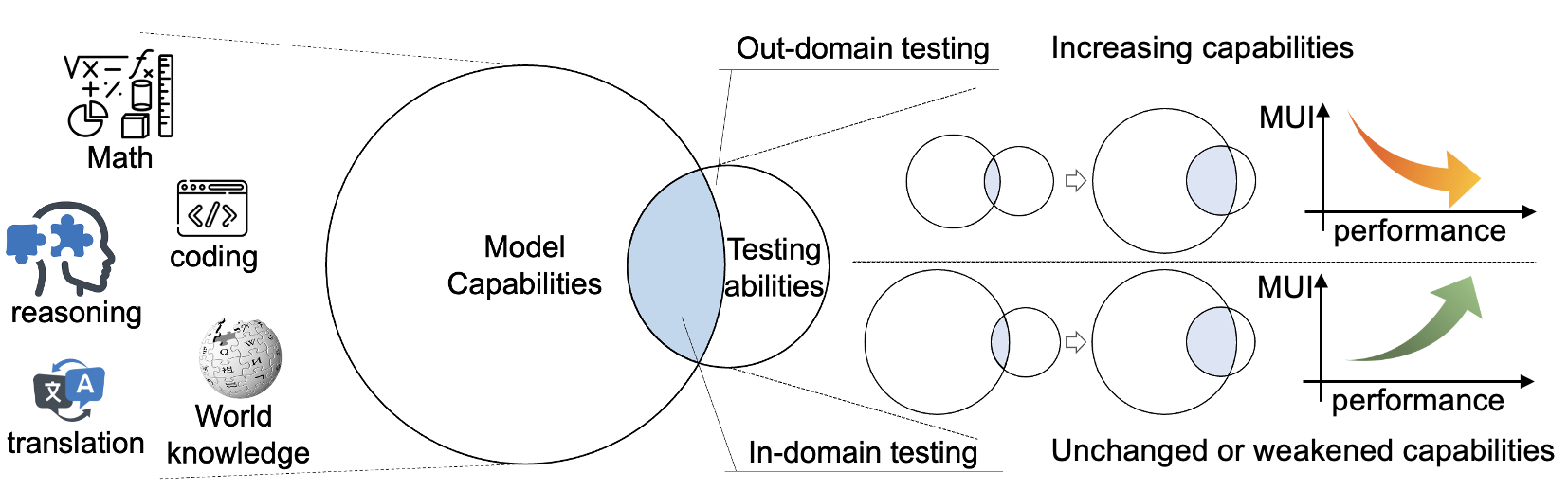
核心思路:本文的核心思路是通过量化模型在解决任务时所付出的“努力”来评估模型的效率。具体来说,作者提出模型利用率指标(MUI),该指标衡量了模型在推理过程中激活的神经元或特征的比例。MUI越高,表示模型需要激活更多的神经元才能完成任务,效率越低。反之,MUI越低,表示模型能够以更少的计算代价获得更高的性能,效率越高。作者假设一个真正有能力的模型应该以更少的努力实现更高的性能。
技术框架:本文提出的技术框架主要包含以下几个步骤:1)选择一组具有代表性的LLM和评估数据集;2)针对每个LLM和数据集,计算MUI指标,MUI的计算方式是统计模型在推理过程中激活的神经元或特征的比例;3)计算LLM在对应数据集上的性能指标,例如准确率、F1值等;4)分析MUI与性能指标之间的关系,验证是否存在反向对数关系,即Utility Law;5)基于Utility Law,推导出四个实用的推论,用于指导模型训练、数据污染检测、模型比较和数据集设计。
关键创新:本文最重要的技术创新点在于提出了模型利用率指标(MUI),并揭示了MUI与性能之间的反向对数关系,即Utility Law。MUI提供了一种新的视角来评估LLM,不仅关注模型的性能,还关注模型的效率。Utility Law则提供了一种理解LLM能力的新框架,可以用于指导模型训练和评估。与现有方法的本质区别在于,本文的方法更加关注模型内部的机制,通过量化神经元的激活比例来评估模型的效率,而现有方法主要关注模型的外部表现,例如准确率等。
关键设计:MUI的计算方式是统计模型在推理过程中激活的神经元或特征的比例。具体来说,对于每一层神经网络,作者首先计算该层神经元的平均激活值,然后设定一个阈值,将激活值高于阈值的神经元视为“激活”状态。MUI定义为激活神经元的数量与总神经元数量的比值。阈值的选择是一个关键的设计细节,作者通过实验发现,选择合适的阈值可以有效地区分激活和非激活神经元,从而准确地反映模型的利用率。
🖼️ 关键图片
📊 实验亮点
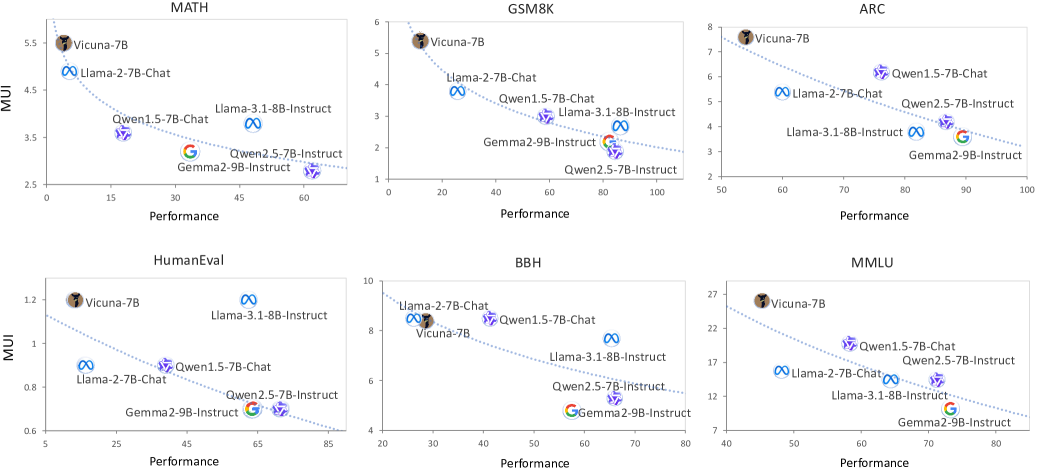
实验结果表明,在多个流行的LLM上,MUI与性能之间存在一致的反向对数关系,验证了Utility Law的有效性。例如,在某个特定任务上,一个模型的MUI降低了10%,性能提升了5%。此外,通过MUI分析,成功检测出某个数据集存在数据污染问题,并指导了模型特定数据集多样性的设计,使模型在特定领域的性能提升了8%。
🎯 应用场景
该研究成果可应用于LLM的训练诊断,通过MUI监测训练过程,及时发现并解决模型效率问题。此外,MUI可用于检测数据污染,评估模型在不同数据集上的泛化能力。该研究还为更公平的模型比较提供了依据,并能指导模型特定数据集多样性的设计,提升模型在特定领域的表现。未来,MUI有望成为LLM评估的重要组成部分。
📄 摘要(原文)
Large Language Models (LLMs) have become indispensable across academia, industry, and daily applications, yet current evaluation methods struggle to keep pace with their rapid development. One core challenge of evaluation in the large language model (LLM) era is the generalization issue: how to infer a model's near-unbounded abilities from inevitably bounded benchmarks. We address this challenge by proposing Model Utilization Index (MUI), a mechanism interpretability enhanced metric that complements traditional performance scores. MUI quantifies the effort a model expends on a task, defined as the proportion of activated neurons or features during inference. Intuitively, a truly capable model should achieve higher performance with lower effort. Extensive experiments across popular LLMs reveal a consistent inverse logarithmic relationship between MUI and performance, which we formulate as the Utility Law. From this law we derive four practical corollaries that (i) guide training diagnostics, (ii) expose data contamination issue, (iii) enable fairer model comparisons, and (iv) design model-specific dataset diversity. Our code can be found at https://github.com/ALEX-nlp/MUI-Eva.