Revisiting Prompt Optimization with Large Reasoning Models-A Case Study on Event Extraction
作者: Saurabh Srivastava, Ziyu Yao
分类: cs.CL
发布日期: 2025-04-10 (更新: 2025-10-16)
💡 一句话要点
研究表明,大型推理模型在事件抽取任务中仍受益于提示优化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型推理模型 提示优化 事件抽取 语言模型 提示工程
📋 核心要点
- 现有观点认为大型推理模型不再需要大量提示工程,但其在复杂任务如事件抽取中的表现有待考察。
- 该研究系统性地评估了大型推理模型作为任务模型和提示优化器在事件抽取中的表现。
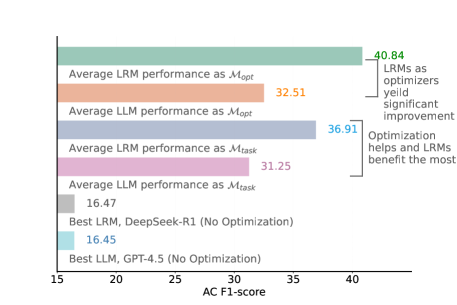
- 实验结果表明,即使是大型推理模型,在事件抽取任务中仍然可以从提示优化中获益。
📝 摘要(中文)
大型推理模型(LRMs),如DeepSeek-R1和OpenAI o1,在各种推理任务中表现出卓越的能力。它们生成和推理中间步骤的强大能力也导致了一种观点,即它们可能不再需要大量的提示工程或优化来解释人类指令并产生准确的输出。在这项工作中,我们旨在系统地研究这个开放性问题,以结构化的事件抽取任务作为案例研究。我们实验了两个LRMs(DeepSeek-R1和o1)和两个通用大型语言模型(LLMs)(GPT-4o和GPT-4.5),将它们用作任务模型或提示优化器。我们的结果表明,在像事件抽取这样复杂的任务中,LRMs作为任务模型仍然受益于提示优化,并且使用LRMs作为提示优化器可以产生更有效的提示。我们的发现也推广到事件抽取以外的任务。最后,我们对LRMs常犯的错误进行了错误分析,并强调了LRMs在改进任务指令和事件指南方面的稳定性和一致性。
🔬 方法详解
问题定义:论文旨在研究大型推理模型(LRMs)在事件抽取任务中是否仍然需要提示优化。现有观点认为LRMs具备强大的推理能力,可能不再依赖于精细的提示工程。然而,事件抽取作为一项复杂的结构化任务,其对提示的敏感性仍需验证。
核心思路:论文的核心思路是通过实验对比不同类型的模型(LRMs和LLMs)在不同提示策略下的事件抽取性能,从而评估提示优化对LRMs的影响。同时,研究还探讨了使用LRMs作为提示优化器是否能进一步提升性能。
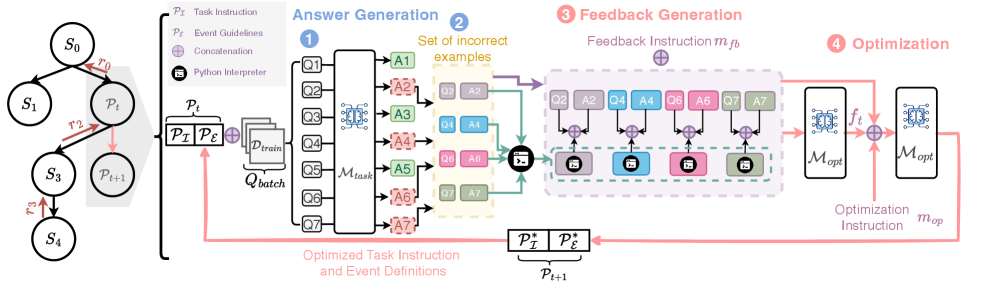
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择事件抽取任务作为研究对象;2) 选择两类模型:LRMs(DeepSeek-R1, o1)和LLMs(GPT-4o, GPT-4.5);3) 设计不同的提示策略,包括人工设计的提示和由模型优化的提示;4) 使用不同模型和提示策略进行事件抽取实验;5) 分析实验结果,评估提示优化对LRMs的影响,并比较不同提示策略的优劣。
关键创新:该研究的关键创新在于系统性地评估了大型推理模型在事件抽取任务中对提示优化的依赖性。以往的研究较少关注LRMs在复杂结构化任务中对提示的敏感性。此外,该研究还探索了使用LRMs作为提示优化器的新思路,并验证了其有效性。
关键设计:论文的关键设计包括:1) 选择了具有代表性的LRMs和LLMs;2) 设计了多种提示策略,包括人工设计的提示和由模型优化的提示,以进行对比;3) 进行了充分的实验,并对实验结果进行了详细的分析,包括错误分析,以深入了解LRMs的优缺点。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是DeepSeek-R1和o1这样的大型推理模型,在事件抽取任务中仍然受益于提示优化。使用LRMs作为提示优化器可以产生更有效的提示,从而进一步提升事件抽取性能。该发现也推广到事件抽取以外的任务。
🎯 应用场景
该研究的成果可应用于提升信息抽取系统的性能,特别是在需要处理复杂事件和关系的场景中。通过优化提示,可以提高大型语言模型在金融分析、舆情监控、安全情报等领域的应用效果。此外,该研究也为如何有效利用大型语言模型进行提示工程提供了指导。
📄 摘要(原文)
Large Reasoning Models (LRMs) such as DeepSeek-R1 and OpenAI o1 have demonstrated remarkable capabilities in various reasoning tasks. Their strong capability to generate and reason over intermediate thoughts has also led to arguments that they may no longer require extensive prompt engineering or optimization to interpret human instructions and produce accurate outputs. In this work, we aim to systematically study this open question, using the structured task of event extraction for a case study. We experimented with two LRMs (DeepSeek-R1 and o1) and two general-purpose Large Language Models (LLMs) (GPT-4o and GPT-4.5), when they were used as task models or prompt optimizers. Our results show that on tasks as complicated as event extraction, LRMs as task models still benefit from prompt optimization, and that using LRMs as prompt optimizers yields more effective prompts. Our finding also generalizes to tasks beyond event extraction. Finally, we provide an error analysis of common errors made by LRMs and highlight the stability and consistency of LRMs in refining task instructions and event guidelines.