Socrates or Smartypants: Testing Logic Reasoning Capabilities of Large Language Models with Logic Programming-based Test Oracles
作者: Zihao Xu, Junchen Ding, Yiling Lou, Kun Zhang, Dong Gong, Yuekang Li
分类: cs.CL
发布日期: 2025-04-09 (更新: 2025-11-19)
💡 一句话要点
提出SmartyPat-Bench和SmartyPat框架,用于评估和提升LLM的逻辑推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 逻辑推理 谬误检测 逻辑编程 Prolog 自然语言生成 基准测试
📋 核心要点
- 现有数据集在评估LLM逻辑推理能力时,存在过于简单、不自然以及上下文受限等问题。
- 论文提出SmartyPat-Bench基准和SmartyPat框架,利用逻辑编程自动生成高质量、自然的逻辑谬误数据。
- 实验表明,SmartyPat生成的数据与人工数据质量相当,并揭示了LLM在逻辑推理方面的优势与不足。
📝 摘要(中文)
大型语言模型(LLMs)在语言理解和推理方面取得了显著进展。评估和分析它们的逻辑推理能力变得至关重要。然而,现有的数据集和基准测试通常局限于过于简单、不自然或上下文受限的例子。为了应对日益增长的需求,我们引入了SmartyPat-Bench,这是一个具有挑战性、自然表达且系统标记的基准,源自包含微妙逻辑谬误的真实高质量Reddit帖子。与现有的数据集和基准测试不同,它提供了更详细的逻辑谬误注释,并具有更多样化的数据。为了进一步扩大研究规模并解决手动数据收集和标记的局限性(例如谬误类型不平衡和劳动密集型注释),我们引入了SmartyPat,这是一个由基于逻辑编程的预言机驱动的自动化框架。SmartyPat利用Prolog规则系统地生成逻辑上错误的陈述,然后由LLM将其细化为流畅的自然语言句子,从而确保精确的谬误表示。广泛的评估表明,SmartyPat产生的谬误在微妙性和质量上与人类生成的内容相当,并且明显优于基线方法。最后,实验揭示了LLM能力的细微见解,强调了过多的推理步骤会降低谬误检测的准确性,而结构化推理可以提高谬误分类的性能。
🔬 方法详解
问题定义:论文旨在解决现有LLM逻辑推理能力评估数据集的不足,即数据集过于简单、不自然,且人工标注成本高昂。现有方法难以系统性地生成多样且高质量的逻辑谬误数据,限制了对LLM逻辑推理能力的深入评估。
核心思路:论文的核心思路是利用逻辑编程(Prolog规则)自动生成逻辑谬误,然后使用LLM将这些谬误转化为自然语言,从而构建一个高质量、多样化的逻辑谬误数据集。这种方法结合了逻辑编程的精确性和LLM的自然语言生成能力,能够有效地生成具有挑战性的逻辑推理测试用例。
技术框架:SmartyPat框架包含以下主要模块:1) 基于Prolog的谬误生成器:使用预定义的Prolog规则生成各种类型的逻辑谬误。2) LLM自然语言转换器:利用LLM将Prolog生成的逻辑谬误转化为流畅、自然的语言句子。3) SmartyPat-Bench基准:包含人工标注和自动生成的逻辑谬误数据,用于评估LLM的逻辑推理能力。整体流程是从Prolog规则生成逻辑表达式,然后通过LLM将其转化为自然语言,最后人工或自动进行标注。
关键创新:最重要的技术创新点在于结合了逻辑编程和LLM,利用逻辑编程的精确性来保证谬误的逻辑正确性,同时利用LLM的自然语言生成能力来提高谬误的自然度和可读性。与现有方法相比,该方法能够更高效、更系统地生成高质量的逻辑谬误数据。
关键设计:Prolog规则的设计是关键,需要覆盖各种常见的逻辑谬误类型。LLM的选择和prompt设计也很重要,需要保证生成的句子既自然流畅,又能准确地表达逻辑谬误。此外,论文还设计了详细的标注规范,用于对生成的数据进行质量控制。
🖼️ 关键图片
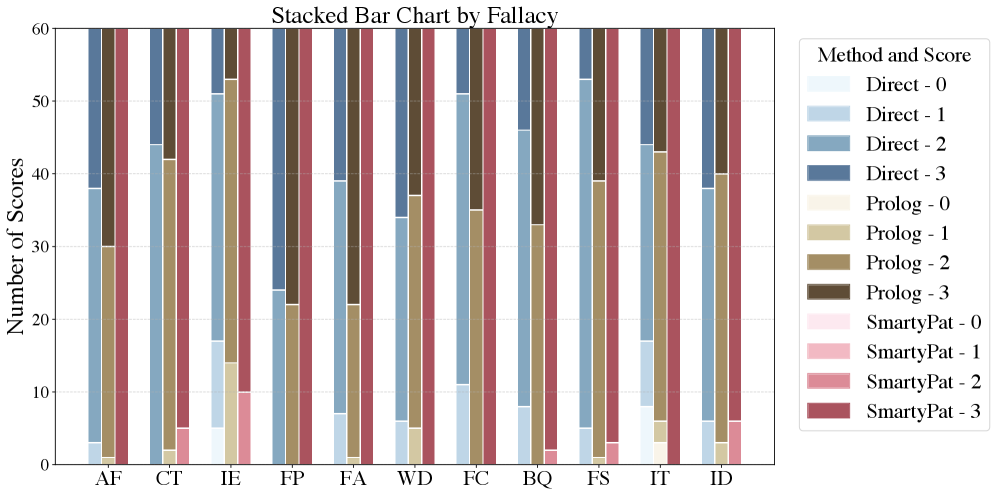
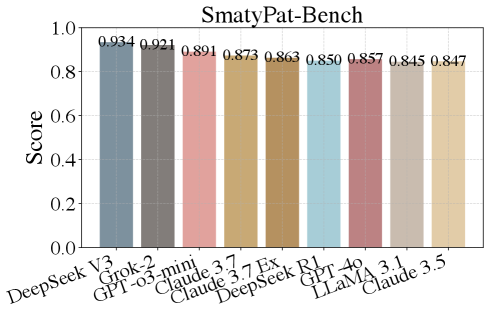

📊 实验亮点
实验结果表明,SmartyPat生成的数据在质量上与人工标注的数据相当,并且明显优于基线方法。具体来说,SmartyPat生成的数据能够更有效地揭示LLM在逻辑推理方面的弱点,例如,过多的推理步骤会降低谬误检测的准确性,而结构化推理可以提高谬误分类的性能。实验还表明,SmartyPat能够生成更具挑战性的逻辑谬误,从而更全面地评估LLM的逻辑推理能力。
🎯 应用场景
该研究成果可应用于LLM的逻辑推理能力评估与提升,例如:构建更有效的LLM训练数据集,开发更强大的逻辑推理引擎,以及提高LLM在对话、问答等任务中的可靠性。此外,该方法还可用于检测和纠正人类文本中的逻辑谬误,提高信息传播的质量。
📄 摘要(原文)
Large Language Models (LLMs) have achieved significant progress in language understanding and reasoning. Evaluating and analyzing their logical reasoning abilities has therefore become essential. However, existing datasets and benchmarks are often limited to overly simplistic, unnatural, or contextually constrained examples. In response to the growing demand, we introduce SmartyPat-Bench, a challenging, naturally expressed, and systematically labeled benchmark derived from real-world high-quality Reddit posts containing subtle logical fallacies. Unlike existing datasets and benchmarks, it provides more detailed annotations of logical fallacies and features more diverse data. To further scale up the study and address the limitations of manual data collection and labeling - such as fallacy-type imbalance and labor-intensive annotation - we introduce SmartyPat, an automated framework powered by logic programming-based oracles. SmartyPat utilizes Prolog rules to systematically generate logically fallacious statements, which are then refined into fluent natural-language sentences by LLMs, ensuring precise fallacy representation. Extensive evaluation demonstrates that SmartyPat produces fallacies comparable in subtlety and quality to human-generated content and significantly outperforms baseline methods. Finally, experiments reveal nuanced insights into LLM capabilities, highlighting that while excessive reasoning steps hinder fallacy detection accuracy, structured reasoning enhances fallacy categorization performance.