HalluciNot: Hallucination Detection Through Context and Common Knowledge Verification
作者: Bibek Paudel, Alexander Lyzhov, Preetam Joshi, Puneet Anand
分类: cs.CL, cs.AI
发布日期: 2025-04-09
💡 一句话要点
提出HalluciNot,通过上下文和常识验证检测企业级大语言模型中的幻觉问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 幻觉检测 上下文验证 常识知识 企业应用
📋 核心要点
- 现有LLM在企业应用中存在幻觉问题,产生不准确或虚假信息,影响决策。
- 提出HDM-2模型,结合上下文和常识验证LLM输出,提供幻觉评分和词级别标注。
- HDM-2在多个数据集上超越现有方法,并在企业部署方面考虑了效率和专业化。
📝 摘要(中文)
本文介绍了一个全面的系统,用于检测企业环境中大型语言模型(LLM)输出中的幻觉。我们提出了一种新颖的LLM响应分类方法,专门针对企业应用中的幻觉,将其分为基于上下文、常识、企业特定和无害陈述。我们的幻觉检测模型HDM-2通过上下文和一般已知事实(常识)验证LLM响应。它提供幻觉分数和词级注释,从而能够精确识别有问题的内容。为了在基于上下文和常识的幻觉上评估它,我们引入了一个新的数据集HDMBench。实验结果表明,HDM-2在RagTruth、TruthfulQA和HDMBench数据集上优于现有方法。这项工作解决了企业部署的特定挑战,包括计算效率、领域专业化和细粒度的错误识别。我们的评估数据集、模型权重和推理代码已公开。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在企业级应用中产生幻觉的问题。现有方法在检测幻觉方面存在不足,尤其是在结合上下文信息和常识知识方面。此外,企业应用对计算效率、领域专业化和细粒度错误识别有更高的要求。
核心思路:论文的核心思路是通过上下文和常识知识验证LLM的输出,判断其是否与已知信息一致。这种方法模拟了人类的推理过程,能够更准确地识别LLM产生的幻觉。论文还针对企业应用场景,对LLM的响应进行了分类,以便更好地进行幻觉检测。
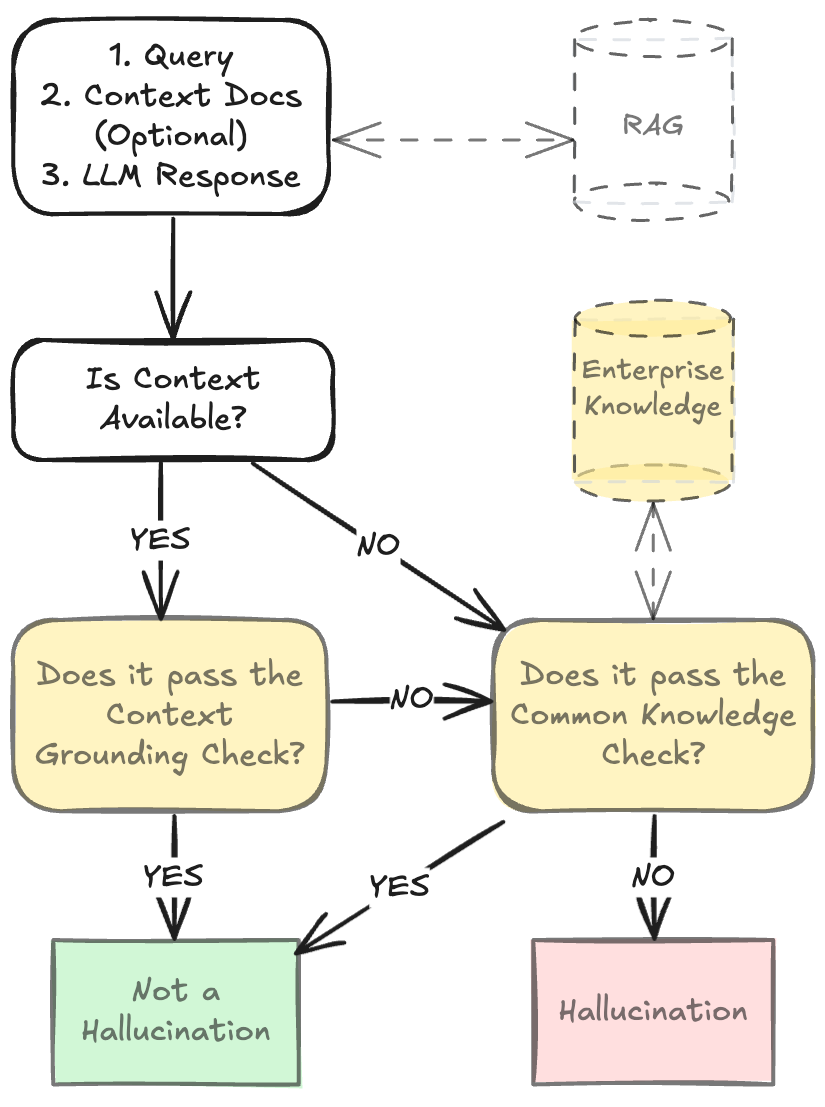
技术框架:HDM-2模型是论文提出的幻觉检测框架,它包含以下主要模块:1) LLM响应分类模块,将LLM的输出分为基于上下文、常识、企业特定和无害陈述;2) 上下文验证模块,利用上下文信息验证LLM输出的真实性;3) 常识验证模块,利用常识知识验证LLM输出的合理性;4) 幻觉评分模块,根据上下文和常识验证的结果,为LLM输出生成幻觉分数和词级别标注。
关键创新:论文的关键创新在于:1) 提出了针对企业应用场景的LLM响应分类方法;2) 提出了结合上下文和常识知识的幻觉检测模型HDM-2;3) 构建了新的数据集HDMBench,用于评估幻觉检测模型的性能。与现有方法相比,HDM-2能够更准确地检测LLM产生的幻觉,并提供更细粒度的错误信息。
关键设计:论文中关于HDM-2模型的具体参数设置、损失函数和网络结构等技术细节未详细描述,属于未知信息。但从整体框架来看,上下文验证和常识验证模块可能采用了知识图谱、外部数据库查询等技术,以获取相关信息并进行比对。
🖼️ 关键图片


📊 实验亮点
HDM-2模型在RagTruth、TruthfulQA和HDMBench数据集上均优于现有方法,表明其在幻觉检测方面具有显著优势。HDMBench数据集的构建为评估幻觉检测模型提供了一个新的基准。具体的性能提升数据在摘要中没有给出,需要查阅论文原文。
🎯 应用场景
该研究成果可应用于企业级智能客服、文档生成、知识库问答等场景,提高LLM应用的可靠性和准确性,降低因幻觉问题带来的风险。未来可进一步扩展到医疗、金融等对信息准确性要求更高的领域,并与人工审核相结合,构建更完善的LLM应用安全体系。
📄 摘要(原文)
This paper introduces a comprehensive system for detecting hallucinations in large language model (LLM) outputs in enterprise settings. We present a novel taxonomy of LLM responses specific to hallucination in enterprise applications, categorizing them into context-based, common knowledge, enterprise-specific, and innocuous statements. Our hallucination detection model HDM-2 validates LLM responses with respect to both context and generally known facts (common knowledge). It provides both hallucination scores and word-level annotations, enabling precise identification of problematic content. To evaluate it on context-based and common-knowledge hallucinations, we introduce a new dataset HDMBench. Experimental results demonstrate that HDM-2 out-performs existing approaches across RagTruth, TruthfulQA, and HDMBench datasets. This work addresses the specific challenges of enterprise deployment, including computational efficiency, domain specialization, and fine-grained error identification. Our evaluation dataset, model weights, and inference code are publicly available.