Towards LLMs Robustness to Changes in Prompt Format Styles
作者: Lilian Ngweta, Kiran Kate, Jason Tsay, Yara Rizk
分类: cs.CL
发布日期: 2025-04-09
备注: NAACL Student Research Workshop (SRW) 2025
💡 一句话要点
提出混合格式(MOF)方法,提升LLM对提示格式变化的鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 提示工程 提示脆弱性 混合格式 鲁棒性 风格迁移 少量样本学习
📋 核心要点
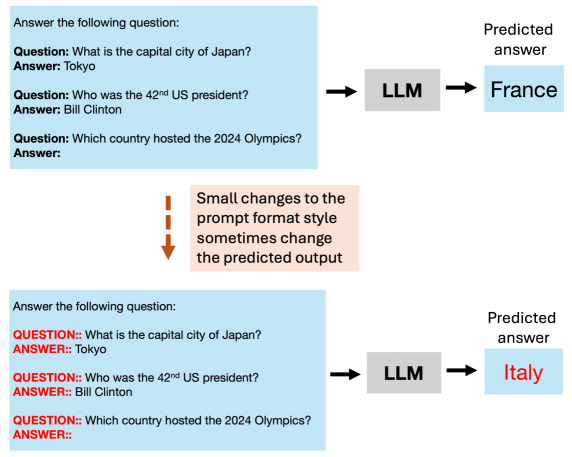
- 大型语言模型对提示格式的微小变化非常敏感,导致性能波动,即“提示脆弱性”。
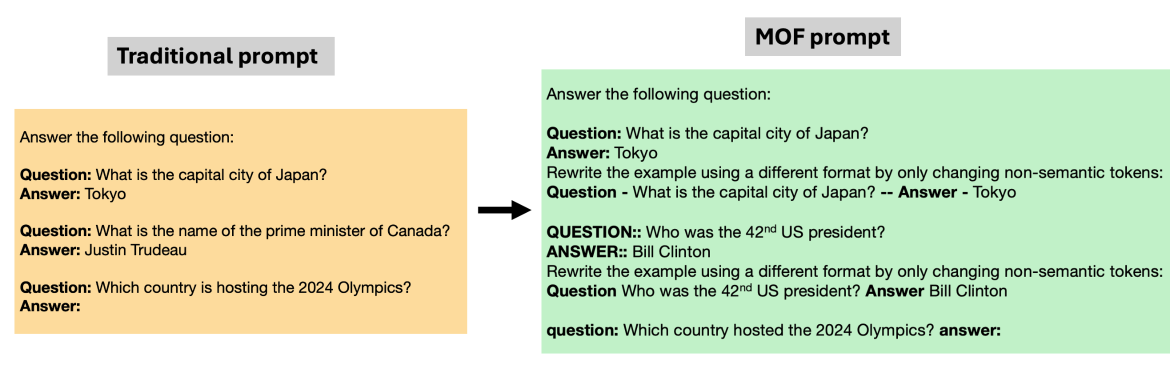
- 论文提出混合格式(MOF)方法,通过在少量样本中引入多样化的提示风格,增强模型的鲁棒性。
- 实验结果表明,MOF能有效降低提示脆弱性,并在不同数据集和提示变化下提升整体性能。
📝 摘要(中文)
近年来,大型语言模型(LLMs)因其在各种应用中的实用性而广受欢迎。然而,LLMs对提示格式的非语义变化非常敏感,提示格式的微小变化可能导致性能的显著波动。在文献中,这个问题通常被称为提示脆弱性。以往关于提示工程的研究主要集中在开发用于识别特定任务的最佳提示的技术。一些研究也探讨了提示脆弱性的问题,并提出了量化性能变化的方法;然而,尚未找到解决这一挑战的简单方案。我们提出混合格式(MOF),这是一种简单有效的技术,通过多样化提示少量样本中使用的样式来解决LLMs中的提示脆弱性。MOF的灵感来自计算机视觉技术,该技术利用多样化的样式数据集来防止模型将特定样式与目标变量相关联。实证结果表明,我们提出的技术降低了各种LLMs中由样式引起的提示脆弱性,同时还提高了提示变化和不同数据集的整体性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)对提示格式变化的敏感性问题,即“提示脆弱性”。现有方法主要集中于寻找特定任务的最佳提示,而忽略了模型对提示格式微小变化的鲁棒性。这种脆弱性限制了LLMs在实际应用中的可靠性和泛化能力。
核心思路:论文的核心思路是借鉴计算机视觉中风格迁移的思想,通过在训练或微调阶段,向LLM展示多种不同风格的提示格式,从而使模型学习到与任务相关的本质特征,而非依赖于特定的提示格式。这样,即使在测试阶段遇到新的提示格式,模型也能保持较好的性能。
技术框架:MOF方法主要包含以下步骤:1. 收集或生成多种不同风格的提示格式。2. 将这些不同格式的提示应用于少量样本,构建混合格式的训练数据集。3. 使用该数据集对LLM进行微调或训练。4. 在测试阶段,使用不同的提示格式评估模型的性能。整体流程简单易行,易于集成到现有的LLM训练流程中。
关键创新:MOF的关键创新在于将计算机视觉中的风格迁移思想应用于自然语言处理领域,并将其用于解决LLM的提示脆弱性问题。与以往专注于寻找最佳提示的方法不同,MOF关注的是提升模型对不同提示格式的泛化能力,从而增强模型的鲁棒性。
关键设计:MOF的关键设计在于如何选择或生成多样化的提示格式。论文可能采用了人工设计、数据增强或自动生成等方法来构建这些格式。此外,损失函数的设计也至关重要,需要确保模型能够学习到与任务相关的本质特征,而非过度拟合特定的提示格式。具体的参数设置和网络结构可能与所使用的LLM有关,需要根据具体情况进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MOF方法能够有效降低LLM对提示格式变化的敏感性,并在各种数据集和提示变化下提升整体性能。具体而言,MOF在多个基准测试中均取得了显著的性能提升,尤其是在面对新的或未见过的提示格式时,其性能优势更为明显。这些结果验证了MOF方法在提升LLM鲁棒性方面的有效性。
🎯 应用场景
该研究成果可广泛应用于各种依赖大型语言模型的自然语言处理任务,例如文本分类、问答系统、文本生成等。通过提升LLM对提示格式变化的鲁棒性,可以提高这些应用在实际场景中的可靠性和用户体验。此外,该方法还有助于降低提示工程的成本,减少对特定提示格式的依赖。
📄 摘要(原文)
Large language models (LLMs) have gained popularity in recent years for their utility in various applications. However, they are sensitive to non-semantic changes in prompt formats, where small changes in the prompt format can lead to significant performance fluctuations. In the literature, this problem is commonly referred to as prompt brittleness. Previous research on prompt engineering has focused mainly on developing techniques for identifying the optimal prompt for specific tasks. Some studies have also explored the issue of prompt brittleness and proposed methods to quantify performance variations; however, no simple solution has been found to address this challenge. We propose Mixture of Formats (MOF), a simple and efficient technique for addressing prompt brittleness in LLMs by diversifying the styles used in the prompt few-shot examples. MOF was inspired by computer vision techniques that utilize diverse style datasets to prevent models from associating specific styles with the target variable. Empirical results show that our proposed technique reduces style-induced prompt brittleness in various LLMs while also enhancing overall performance across prompt variations and different datasets.