Data Augmentation for Fake Reviews Detection in Multiple Languages and Multiple Domains
作者: Ming Liu, Massimo Poesio
分类: cs.CL
发布日期: 2025-04-09
备注: 32 pages, 15 figures
💡 一句话要点
提出基于大型语言模型的数据增强方法,提升多语言多领域虚假评论检测性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 虚假评论检测 数据增强 大型语言模型 多语言 多领域
📋 核心要点
- 现有虚假评论检测模型在低资源语言和领域面临数据匮乏的挑战,限制了模型性能。
- 利用大型语言模型生成高质量的虚假评论数据,作为数据增强手段,扩充训练数据集。
- 实验证明,该方法在多个领域和语言上均能有效提升虚假评论检测的准确率。
📝 摘要(中文)
随着互联网的发展,购买习惯发生了改变,顾客越来越依赖其他顾客的在线评价来指导购买决策。因此,识别虚假评论成为自然语言处理(NLP)研究的一个重要领域。然而,开发高性能的NLP模型依赖于大量的训练数据,而这些数据在低资源语言或领域中往往是不可用的。在这项研究中,我们使用大型语言模型来生成数据集,以训练虚假评论检测器。我们的方法被用于生成不同领域(书籍评论、餐厅评论和酒店评论)和不同语言(英语和中文)的虚假评论。我们的结果表明,我们的数据增强技术可以提高所有领域和语言的虚假评论检测性能。使用增强数据集,我们的虚假评论检测模型的准确率在DeRev TEST上提高了0.3个百分点,在Amazon TEST上提高了10.9个百分点,在Yelp TEST上提高了8.3个百分点,在DianPing TEST上提高了7.2个百分点。
🔬 方法详解
问题定义:论文旨在解决低资源语言和领域中,虚假评论检测模型训练数据不足的问题。现有的方法难以在这些场景下获得足够的标注数据,导致模型泛化能力差,检测准确率低。
核心思路:论文的核心思路是利用大型语言模型强大的生成能力,自动生成与真实评论相似的虚假评论数据,从而扩充训练数据集。通过在增强后的数据集上训练模型,可以提高模型在低资源场景下的性能。这种方法避免了人工标注的成本,并且可以灵活地应用于不同的领域和语言。
技术框架:整体流程包括:1) 使用大型语言模型生成虚假评论数据;2) 将生成的虚假评论数据与真实评论数据混合,构建增强后的训练数据集;3) 在增强后的数据集上训练虚假评论检测模型;4) 在测试集上评估模型的性能。具体来说,可以使用预训练的语言模型,如BERT或GPT系列模型,并针对虚假评论生成任务进行微调。
关键创新:关键创新在于将大型语言模型的生成能力应用于数据增强,并将其应用于多语言、多领域的虚假评论检测任务。与传统的数据增强方法相比,使用大型语言模型可以生成更逼真、更多样化的数据,从而更有效地提高模型的性能。此外,该方法具有较强的通用性,可以应用于其他类似的低资源NLP任务。
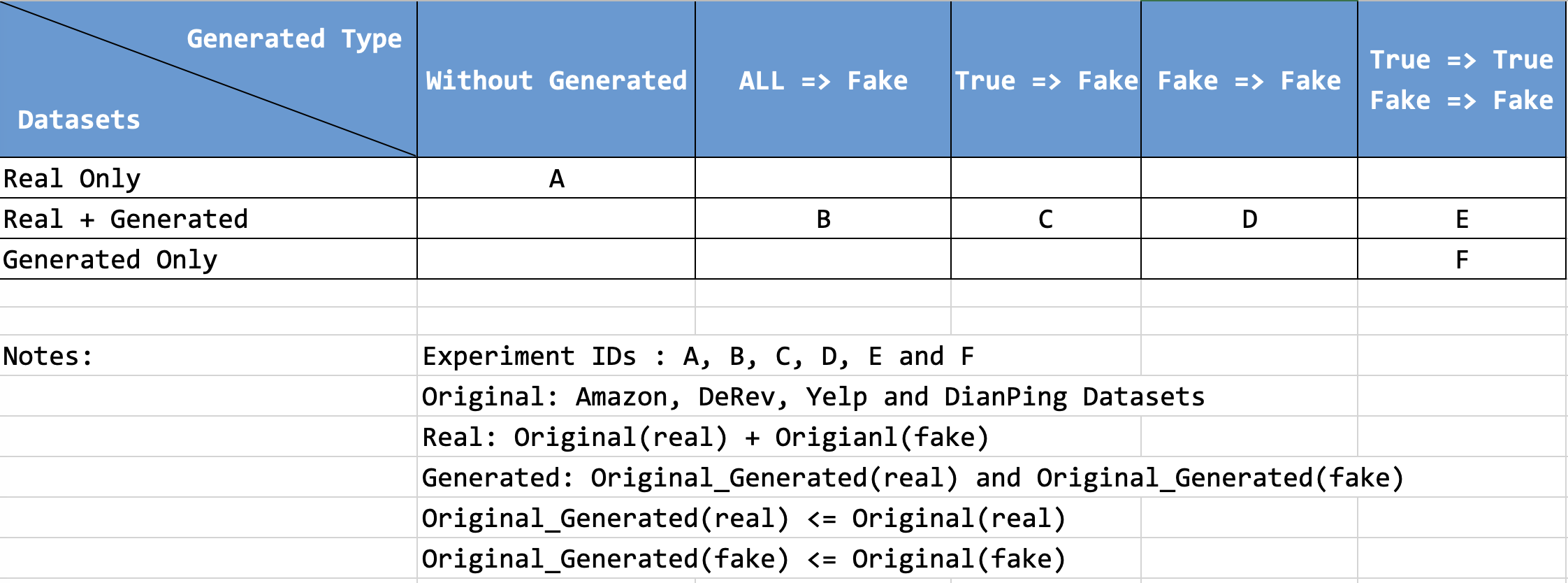
关键设计:论文中可能涉及的关键设计包括:1) 如何选择合适的prompt来引导大型语言模型生成高质量的虚假评论;2) 如何控制生成数据的质量,避免引入噪声;3) 如何平衡真实数据和生成数据的比例,以获得最佳的训练效果;4) 损失函数的设计,例如可以使用交叉熵损失函数来训练分类模型;5) 模型结构的选择,例如可以使用基于Transformer的模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用该数据增强方法,虚假评论检测模型的准确率在DeRev TEST上提高了0.3个百分点,在Amazon TEST上提高了10.9个百分点,在Yelp TEST上提高了8.3个百分点,在DianPing TEST上提高了7.2个百分点。这些结果表明,该方法在不同领域和语言上均能有效提升虚假评论检测的性能。
🎯 应用场景
该研究成果可应用于电商平台、社交媒体等领域,帮助识别和过滤虚假评论,提升用户体验,维护平台声誉。此外,该方法也可推广至其他低资源场景下的文本分类任务,例如垃圾邮件检测、情感分析等,具有广泛的应用前景。
📄 摘要(原文)
With the growth of the Internet, buying habits have changed, and customers have become more dependent on the online opinions of other customers to guide their purchases. Identifying fake reviews thus became an important area for Natural Language Processing (NLP) research. However, developing high-performance NLP models depends on the availability of large amounts of training data, which are often not available for low-resource languages or domains. In this research, we used large language models to generate datasets to train fake review detectors. Our approach was used to generate fake reviews in different domains (book reviews, restaurant reviews, and hotel reviews) and different languages (English and Chinese). Our results demonstrate that our data augmentation techniques result in improved performance at fake review detection for all domains and languages. The accuracy of our fake review detection model can be improved by 0.3 percentage points on DeRev TEST, 10.9 percentage points on Amazon TEST, 8.3 percentage points on Yelp TEST and 7.2 percentage points on DianPing TEST using the augmented datasets.