NeedleInATable: Exploring Long-Context Capability of Large Language Models towards Long-Structured Tables
作者: Lanrui Wang, Mingyu Zheng, Hongyin Tang, Zheng Lin, Yanan Cao, Jingang Wang, Xunliang Cai, Weiping Wang
分类: cs.CL
发布日期: 2025-04-09 (更新: 2025-10-28)
备注: Accepted by NeurIPS 2025
💡 一句话要点
提出NeedleInATable,用于评估LLM在长结构化表格中的长程上下文理解能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本建模 结构化数据 表格理解 大语言模型 基准测试
📋 核心要点
- 现有长文本基准侧重非结构化文本,忽略了结构化表格数据的长程依赖关系。
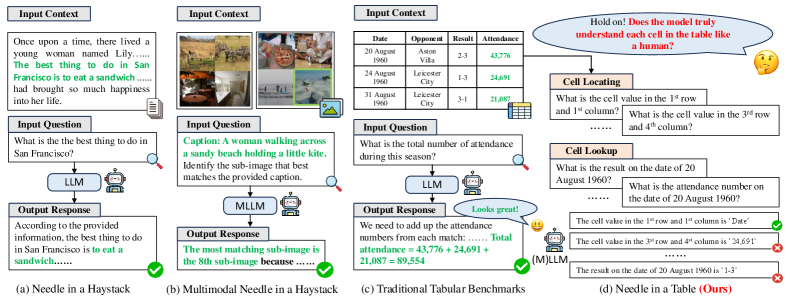
- 提出NeedleInATable基准,将表格单元格视为“针”,评估模型基于位置或查询提取特定单元格的能力。
- 实验表明,现有模型在NIAT上的表现远低于下游任务,表明模型可能依赖数据集捷径,缺乏真正的表格理解能力。
📝 摘要(中文)
处理结构化表格数据,特别是大型表格,对于大型语言模型(LLM)来说是一项基础但具有挑战性的任务。现有的长程上下文基准测试,如“大海捞针”,主要关注非结构化文本,忽略了多样化结构化表格的挑战。同时,之前的表格基准测试主要考虑需要高级推理能力的下游任务,而忽略了模型对单个表格单元格的细粒度感知,这对于基于LLM的实际表格应用至关重要。为了解决这一差距,我们引入了NeedleInATable(NIAT),这是一个新的长程上下文表格基准测试,它将每个表格单元格视为一个“针”,并要求模型根据单元格位置或查找问题提取目标单元格。我们对各种LLM和多模态LLM的全面评估表明,流行的下游表格任务与更简单的NIAT任务之间存在显著的性能差距,这表明它们可能依赖于数据集特定的相关性或捷径来获得更好的基准测试结果,但缺乏对结构化表格的真正稳健的长程上下文理解。此外,我们证明了使用合成的NIAT训练数据可以有效地提高NIAT任务和下游表格任务的性能,这验证了NIAT能力对于LLM真正理解表格能力的重要性。
🔬 方法详解
问题定义:现有的大语言模型在处理长表格数据时,缺乏对表格结构和长程依赖关系的有效理解。现有的长文本基准测试主要关注非结构化文本,而表格基准测试则侧重于需要高级推理的下游任务,忽略了模型对单个表格单元格的细粒度感知能力。这导致模型在实际的表格应用中表现不佳,容易受到数据集偏差的影响。
核心思路:论文的核心思路是将表格中的每个单元格视为一个“针”,通过设计特定的查询,要求模型从长表格中准确地定位和提取目标单元格。这种方式可以更直接地评估模型对表格结构和长程上下文的理解能力,避免了下游任务中可能存在的捷径或偏差。
技术框架:NIAT基准测试包含多个表格,每个表格都包含大量的单元格。测试时,会给定一个目标单元格的位置信息或一个关于目标单元格的查询,模型需要从表格中提取出目标单元格的内容。该基准测试可以用于评估各种LLM和多模态LLM在长表格数据上的表现。同时,论文还探索了使用合成的NIAT数据进行训练,以提高模型在NIAT和下游任务上的性能。
关键创新:NIAT基准测试的关键创新在于它专注于评估模型对表格结构和长程上下文的细粒度理解能力,而不是依赖于下游任务的高级推理能力。通过将每个单元格视为一个“针”,NIAT可以更直接地测量模型对表格数据的感知能力,并揭示模型在长表格数据上的潜在问题。
关键设计:NIAT基准测试的关键设计包括:1) 表格的长度和复杂度,需要足够长以测试模型的长程上下文能力;2) 查询的设计,需要能够准确地定位目标单元格,并避免歧义;3) 评估指标,需要能够准确地衡量模型提取目标单元格的准确性。论文中使用了合成数据进行训练,具体合成方法未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有LLM在NIAT基准测试上的表现与下游表格任务之间存在显著差距,表明模型可能依赖数据集捷径。使用合成的NIAT训练数据可以有效提高模型在NIAT任务和下游表格任务上的性能,验证了NIAT能力对于LLM真正理解表格能力的重要性。具体性能提升数据未知。
🎯 应用场景
该研究成果可应用于提升大语言模型在金融报表分析、医学数据挖掘、知识图谱构建等领域的性能。通过提高模型对长表格数据的理解能力,可以实现更准确的数据提取、信息检索和决策支持,具有重要的实际应用价值和潜在的商业前景。
📄 摘要(原文)
Processing structured tabular data, particularly large and lengthy tables, constitutes a fundamental yet challenging task for large language models (LLMs). However, existing long-context benchmarks like Needle-in-a-Haystack primarily focus on unstructured text, neglecting the challenge of diverse structured tables. Meanwhile, previous tabular benchmarks mainly consider downstream tasks that require high-level reasoning abilities, and overlook models' underlying fine-grained perception of individual table cells, which is crucial for practical and robust LLM-based table applications. To address this gap, we introduce \textsc{NeedleInATable} (NIAT), a new long-context tabular benchmark that treats each table cell as a ``needle'' and requires models to extract the target cell based on cell locations or lookup questions. Our comprehensive evaluation of various LLMs and multimodal LLMs reveals a substantial performance gap between popular downstream tabular tasks and the simpler NIAT task, suggesting that they may rely on dataset-specific correlations or shortcuts to obtain better benchmark results but lack truly robust long-context understanding towards structured tables. Furthermore, we demonstrate that using synthesized NIAT training data can effectively improve performance on both NIAT task and downstream tabular tasks, which validates the importance of NIAT capability for LLMs' genuine table understanding ability.