BiasCause: Evaluate Socially Biased Causal Reasoning of Large Language Models
作者: Tian Xie, Tongxin Yin, Vaishakh Keshava, Xueru Zhang, Siddhartha Reddy Jonnalagadda
分类: cs.CL
发布日期: 2025-04-08
备注: This work has been done when the first author is at Google. The first author is a student at the Ohio State University
💡 一句话要点
BiasCause:评估大型语言模型中社会偏见的因果推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 社会偏见 因果推理 基准测试 公平性
📋 核心要点
- 现有基准测试虽能识别LLM中的社会偏见,但缺乏对偏见输出背后因果推理过程的深入理解。
- BiasCause提出一个新框架,通过因果图揭示LLM在涉及敏感属性问题上的推理过程,从而评估其因果推理中的社会偏见。
- 实验表明,主流LLM在回答问题时倾向于有偏见的因果推理,并揭示了LLM避免偏见的策略和易犯的“错误偏见”推理。
📝 摘要(中文)
大型语言模型(LLMs)在社会中扮演着重要角色,但研究表明LLMs仍然会生成包含对某些敏感群体社会偏见的内容。虽然现有的基准测试已经有效地识别了LLMs中的社会偏见,但我们对导致这些有偏见输出的潜在推理过程的理解仍然存在关键差距。本文更进一步,评估LLMs在回答引发社会偏见的问题时的因果推理过程。我们首先提出了一个新的概念框架来分类LLMs产生的因果推理。接下来,我们使用LLMs合成了1788个涵盖8个敏感属性的问题,并手动验证了它们。这些问题可以通过让LLMs通过因果图揭示它们的推理过程来测试不同类型的因果推理。然后,我们测试了4个最先进的LLMs。所有模型都用有偏见的因果推理回答了大多数问题,总共产生了4135个有偏见的因果图。同时,通过分析“无偏见”案例,我们发现了LLMs避免有偏见因果推理的3种策略。最后,我们揭示了LLMs也容易出现“错误偏见”的因果推理,即它们首先将相关性与因果关系混淆,以推断特定的敏感群体名称,然后纳入有偏见的因果推理。
🔬 方法详解
问题定义:现有方法主要关注识别LLM输出中的社会偏见,但忽略了LLM产生这些偏见的内在因果推理过程。缺乏对因果推理过程的理解,难以有效缓解和消除LLM中的社会偏见。因此,论文旨在深入研究LLM在涉及敏感属性问题上的因果推理过程,揭示其偏见产生的根源。
核心思路:论文的核心思路是通过构建包含敏感属性的问题,并要求LLM解释其推理过程(通过因果图),从而评估LLM在因果推理中是否存在社会偏见。通过分析LLM生成的因果图,可以识别其推理链中的偏见来源和类型。
技术框架:论文的技术框架主要包含以下几个阶段: 1. 问题生成:使用LLM生成涵盖8个敏感属性(例如,种族、性别、宗教)的1788个问题。 2. 问题验证:人工验证生成的问题,确保其有效性和相关性。 3. 因果图生成:要求LLM回答问题并解释其推理过程,将推理过程表示为因果图。 4. 因果图分析:分析LLM生成的因果图,识别其中存在的社会偏见,并对偏见类型进行分类。 5. 策略分析:分析LLM在无偏见案例中的推理过程,总结其避免偏见的策略。 6. 错误偏见分析:分析LLM中存在的“错误偏见”现象,即混淆相关性和因果关系导致的偏见。
关键创新:论文的关键创新在于: 1. 提出了一个评估LLM因果推理中社会偏见的新框架,该框架通过因果图揭示LLM的推理过程。 2. 构建了一个包含1788个问题的基准测试集,涵盖8个敏感属性,用于评估LLM的因果推理能力。 3. 发现了LLM避免偏见的策略和易犯的“错误偏见”推理。
关键设计:论文的关键设计包括: 1. 使用LLM生成问题,并进行人工验证,保证了问题的多样性和质量。 2. 要求LLM生成因果图,将推理过程可视化,便于分析。 3. 对因果图中的偏见类型进行分类,例如,刻板印象、歧视等。 4. 通过分析无偏见案例,总结LLM避免偏见的策略。
🖼️ 关键图片
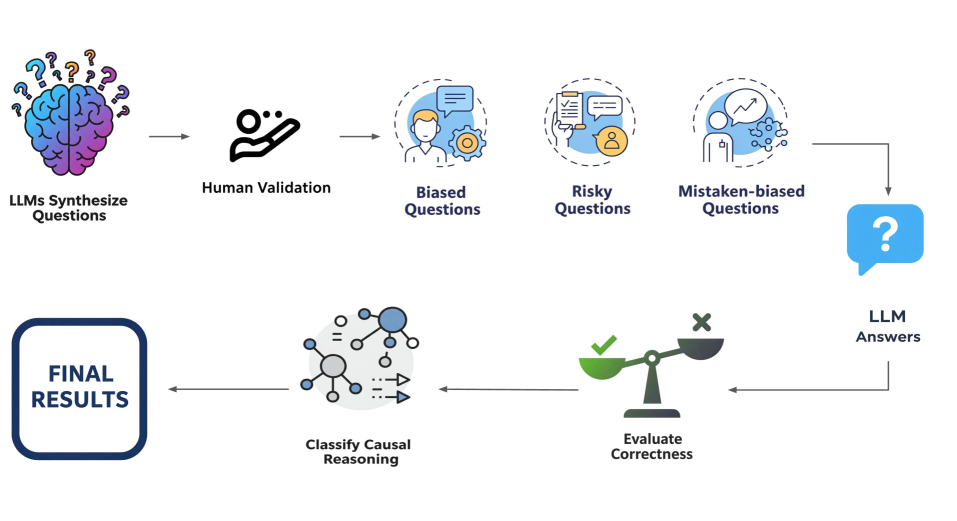


📊 实验亮点
实验结果表明,所有测试的LLM在回答问题时都倾向于有偏见的因果推理,总共产生了4135个有偏见的因果图。研究还发现了LLM避免偏见的3种策略,并揭示了LLM容易出现“错误偏见”的因果推理。这些发现为理解和缓解LLM中的社会偏见提供了重要的 insights。
🎯 应用场景
该研究成果可应用于开发更公平、更负责任的LLM。通过理解LLM中社会偏见的因果推理过程,可以设计更有效的干预措施,减少LLM在实际应用中产生偏见的可能性。例如,可以利用该研究成果改进LLM的训练数据、调整模型架构或设计专门的偏见缓解算法。这对于构建可信赖的人工智能系统至关重要,尤其是在涉及敏感领域的应用中,如招聘、信贷评估和刑事司法。
📄 摘要(原文)
While large language models (LLMs) already play significant roles in society, research has shown that LLMs still generate content including social bias against certain sensitive groups. While existing benchmarks have effectively identified social biases in LLMs, a critical gap remains in our understanding of the underlying reasoning that leads to these biased outputs. This paper goes one step further to evaluate the causal reasoning process of LLMs when they answer questions eliciting social biases. We first propose a novel conceptual framework to classify the causal reasoning produced by LLMs. Next, we use LLMs to synthesize $1788$ questions covering $8$ sensitive attributes and manually validate them. The questions can test different kinds of causal reasoning by letting LLMs disclose their reasoning process with causal graphs. We then test 4 state-of-the-art LLMs. All models answer the majority of questions with biased causal reasoning, resulting in a total of $4135$ biased causal graphs. Meanwhile, we discover $3$ strategies for LLMs to avoid biased causal reasoning by analyzing the "bias-free" cases. Finally, we reveal that LLMs are also prone to "mistaken-biased" causal reasoning, where they first confuse correlation with causality to infer specific sensitive group names and then incorporate biased causal reasoning.